本文主要是介绍Volcano v1.2版本后的资源预留实现原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.背景介绍
在Volcano v1.2版本之前,资源预留是通过Reserve action实现的。具体实现可以参考:
Volcano作业资源预留设计原理解读-云社区-华为云
Reserve action完成资源预留。将选中的目标作业与节点进行绑定。Reserve action、elect action 以及Reservation plugin组成了资源预留机制。Reserve action必须配置在allocate action之后。Reserve action从v1.2开始已经被弃用,并且被SLA plugin替代。下面重点介绍一下SLA的方式。
2.SLA简介
当用户将作业应用到Volcano时,他们可能需要为作业添加一些特定的约束,例如,最长的 Pending 时间旨在防止作业饿死。这些约束可以看作是Volcano和用户之间达成的服务水平协议(SLA)。因此提供了 sla 插件来接收和实现单个作业和整个集群的 SLA 设置。
SLA的全称是Service Level agreement。用户向volcano提交job的时候,可能会给job增加特殊的约束,例如最长等待时间(JobWaitingTime)。这些约束条件可以视为用户与volcano之间的服务协议。SLA plugin可以为单个作业/整个集群接收或者发送SLA参数。
3.场景
根据业务的需要用户可以在自己的集群定制SLA相关参数。例如实时性服务要求较高的集群,JobWaitingTime可以设置的尽量小。批量计算作业为主的集群,JobWaitingTime可以设置较大。具体SLA的参数以及参数的优化需要结合具体的业务以及相关的性能测评结果。
4.实现原理
1.在 sla 插件中,sla-waiting-time提供了实现作业资源预留的参数:sla-waiting-time一个作业应该停留的最长时间Pending或inqueue状态而不被分配。结束sla-waiting-time后,sla插件将作业设置为inqueue立即enqueue生效。然后sla插件会锁定预先分配给该作业的 Pod 的空闲资源allocate,即使该作业Ready尚未完成。这样slaplugin就实现了大job的选举和资源预留,从而替代了v1.1.0中的elect& reserveaction。
2.sla-waiting-time可以为一个作业设置参数,也可以为集群中的所有作业设置参数。
对于一项工作,用户可以在工作注释中设置它们,格式如下:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
annotations:
sla-waiting-time: 1h2m3s
对于所有作业,用户可以通过以下格式在插件参数中设置sla-waiting-time字段:slavolcano-scheduler-configmap
actions: "enqueue, allocate, backfill"
tiers:
- plugins:
- name: priority
- name: gang
- name: sla
arguments:
sla-waiting-time: 1h2m3s
3.sla插件返回 3 个回调函数:JobEnqueueableFn、JobPipelinedFn和JobOrderFn:
(1)JobEnqueueableFnPermit当状态中的作业等待时间Pending长于 时返回sla-waiting-time,并且作业将enqueue立即执行inqueue,而不管其他插件返回Reject或Abstain拒绝该作业inqueue。
(2)JobPipelinedFnPermit当状态中的作业等待时间inqueue长于时返回sla-waiting-time,并且作业将Pipelined立即成为状态,而不管其他插件返回Reject或Abstain拒绝该作业Pipelined。通过这种方式allocate,即使作业尚未就绪,action 也会为作业的 pod 保留资源。
(3)JobOrderFn调整此作业在enqueue&allocate操作的等待队列中的顺序。越接近 sla-waiting-time那个job的等待时间,这个job在plugin中的得分就越高JobOrderFn,sla这样这个job就有更大的概率成为front int priority queue,这意味着它可以接触到更多的空闲资源,并且有更高的优先级被inqueue和分配。
5.SLA插件的执行流程图
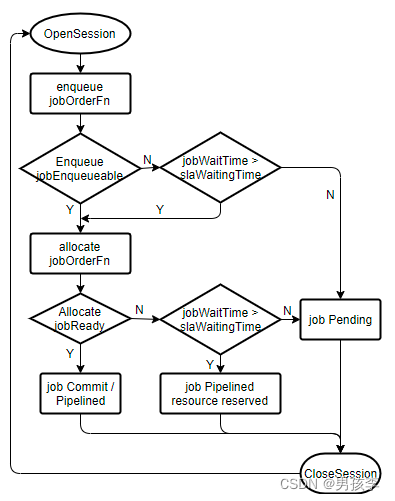
6.参考资料:
Actions | Volcano
Plugins | Volcano
volcano/sla-plugin.md at master · volcano-sh/volcano · GitHub
这篇关于Volcano v1.2版本后的资源预留实现原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





