本文主要是介绍cube开源一站式云原生机器学习平台--volcano 多机分布式计算,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

全栈工程师开发手册 (作者:栾鹏)
一站式云原生机器学习平台
volcano的基本原理和架构
Volcano是一个基于Kubernetes的云原生批量计算平台,也是CNCF的首个批量计算项目。
volcano是华为开源出的分布式训练架构,github官方网址:https://github.com/volcano-sh/volcano
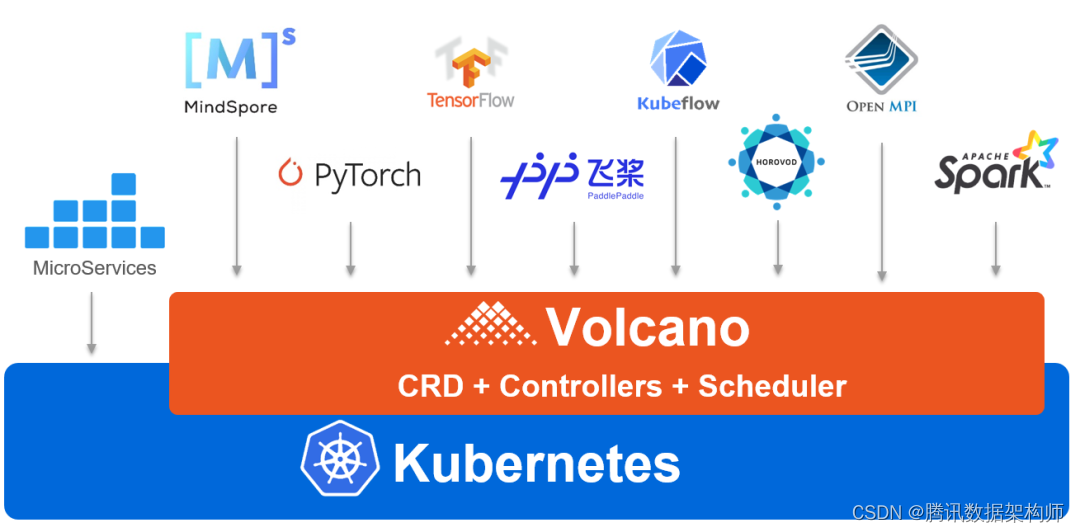
volcano 多机分布式
有时候单台机器多进程也无法快速完成代码运行,这个时候就需要多机器实现:
1、单机器算力有限,核数不足
2、有些运行有机器白名单显示,需要多台机器ip增加并发处理
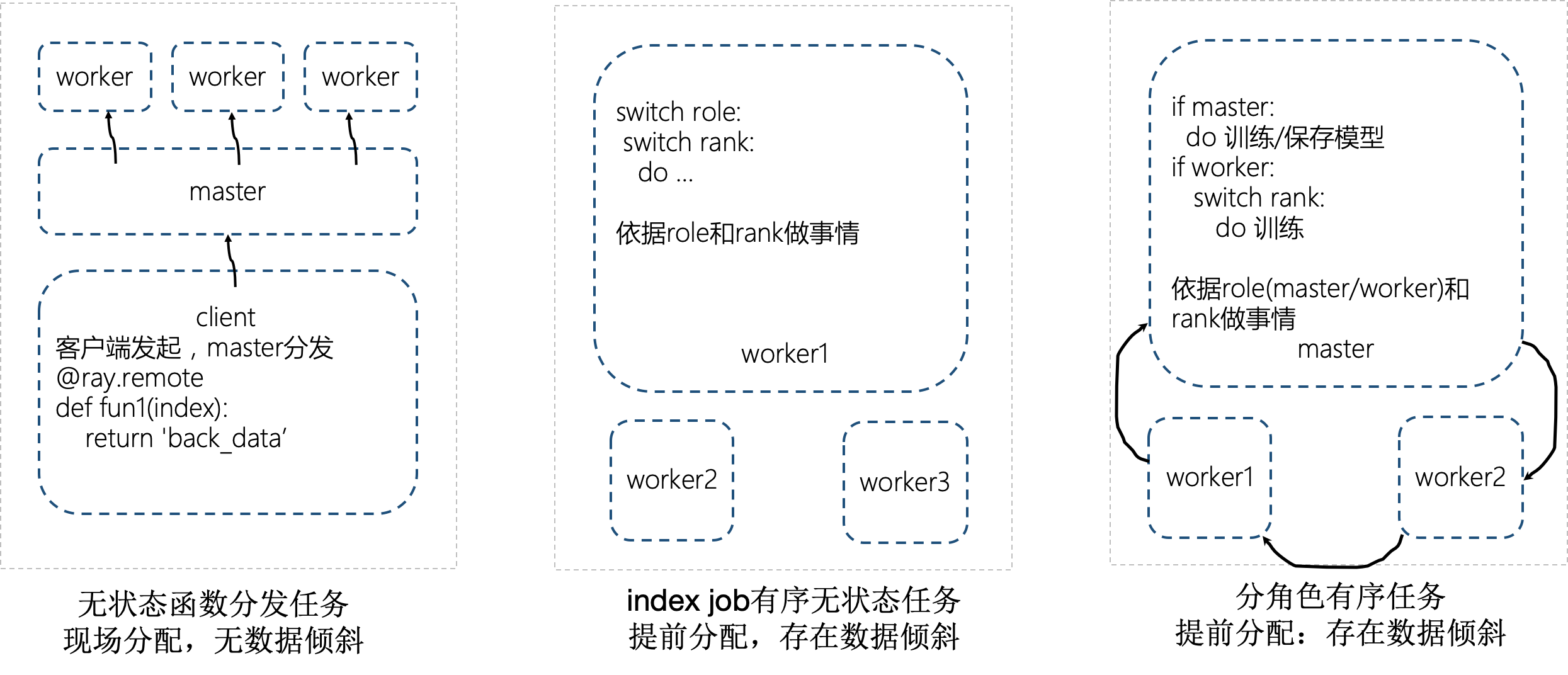
volcano主要为我们提供index job, 也就是启动多个pod,并为每个pod提供index,role,以及其他role的访问地址。这样我们就可以用这些信息来做事情。
分布式计算集群
为了方便的实现一个volcano多机分布式集群,这里直接使用
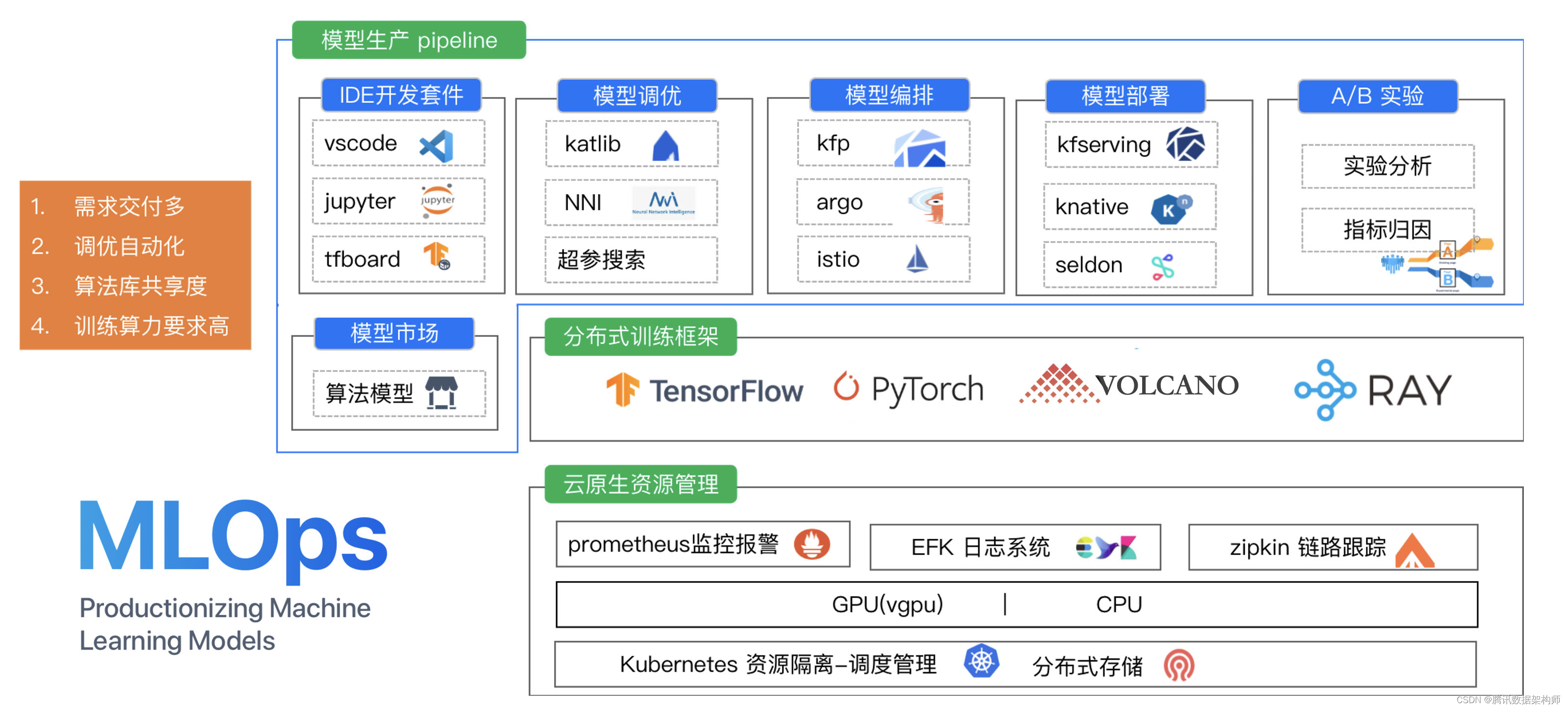
https://github.com/tencentmusic/cube-studio 开源的云原生一站式机器学习平台。
使用volcano这个模板,填上自己的worker数量,每个worker的镜像和启动命令就可以了

分布式原理和代码
基本原则
部署分布式volcano集群 平台已经我们实现了,我们只需要编写分布式的代码。 要想针对实现并发操作
1、通过环境变量VC_WORKER_NUM 有多少个worker
2、通过环境变量VC_TASK_INDEX实现当前pod是第几个worker
3、每个worker里面都判别一遍总共需要处理的数据,和当前worker需要处理的数据。
4、代码根据当前是第几个worker处理自己该做的工作。
用户代码示例
保留单机的代码,添加识别集群信息的代码(多少个worker,当前worker是第几个),添加分工(只处理归属于当前worker的任务),
import time, datetime, json, requests, io, os
from multiprocessing import Pool
from functools import partial
import os, random, sysWORLD_SIZE = int(os.getenv('VC_WORKER_NUM', '1')) # 总worker的数目
RANK = int(os.getenv("VC_TASK_INDEX", '0')) # 当前是第几个worker 从0开始print(WORLD_SIZE, RANK)# 子进程要执行的代码
def task(key):print(datetime.datetime.now(),'worker:', RANK, ', task:', key, flush=True)time.sleep(1)if __name__ == '__main__':# if os.path.exists('./success%s' % RANK):# os.remove('./success%s' % RANK)input = range(300) # 所有要处理的数据local_task = [] # 当前worker需要处理的任务for index in input:if index % WORLD_SIZE == RANK:local_task.append(index) # 要处理的数据均匀分配到每个worker# 每个worker内部还可以用多进程,线程池之类的并发操作。pool = Pool(10) # 开辟包含指定数目线程的线程池pool.map(partial(task), local_task) # 当前worker,只处理分配给当前worker的任务pool.close()pool.join()# 添加文件标识,当前worker结束# open('./success%s' % RANK, mode='w').close()# # rank0做聚合操作# while (RANK == 0):# success = [x for x in range(WORLD_SIZE) if os.path.exists('./success%s' % x)]# if len(success) != WORLD_SIZE:# time.sleep(5)# else:# # 所有worker全部结束,worker0开始聚合操作# print('begin reduce')# break
这篇关于cube开源一站式云原生机器学习平台--volcano 多机分布式计算的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






