本文主要是介绍使用Gensim库来实现Word2Vec,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Gensim
Gensim是一个开源库,用于无监督的统计建模和自然语言处理,用Python和Cython实现的
Gensim库来实现Word2Vec
Word2Vec被认为是自然语言处理(NLP)领域中最大、最新的突破之一。其的概念简单,优雅,(相对)容易掌握。Google一下就会找到一堆关于如何使用诸如Gensim和TensorFlow的库来调用Word2Vec方法的结果
Word2Vec的目标是生成带有语义的单词的向量表示,用于进一步的NLP任务。每个单词向量通常有几百个维度,语料库中每个唯一的单词在空间中被分配一个向量。例如,单词“happy”可以表示为4维向量[0.24、0.45、0.11、0.49],“sad”具有向量[0.88、0.78、0.45、0.91]。这种从单词到向量的转换也被称为单词嵌入(word embedding)。这种转换的原因是机器学习算法可以对数字(在向量中的)而不是单词进行线性代数运算。
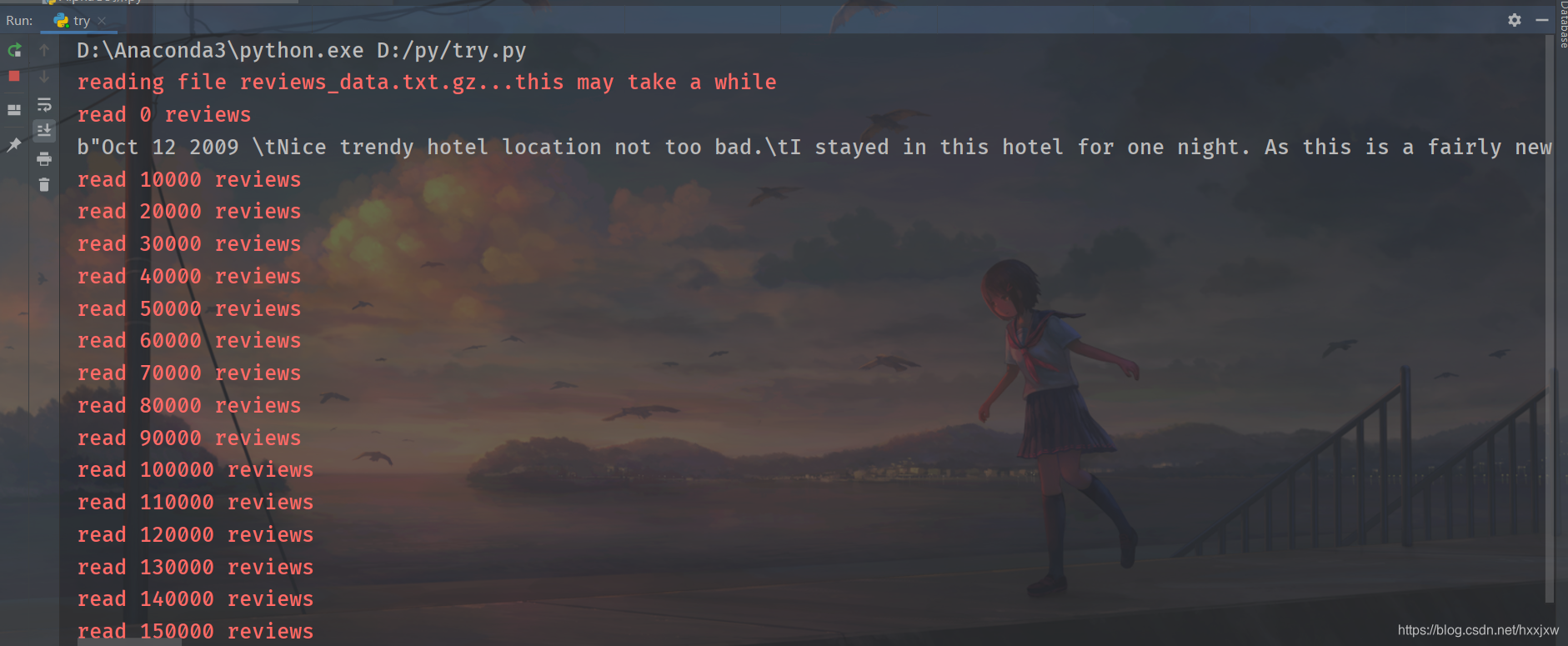
首先解压数据,读入到list里面
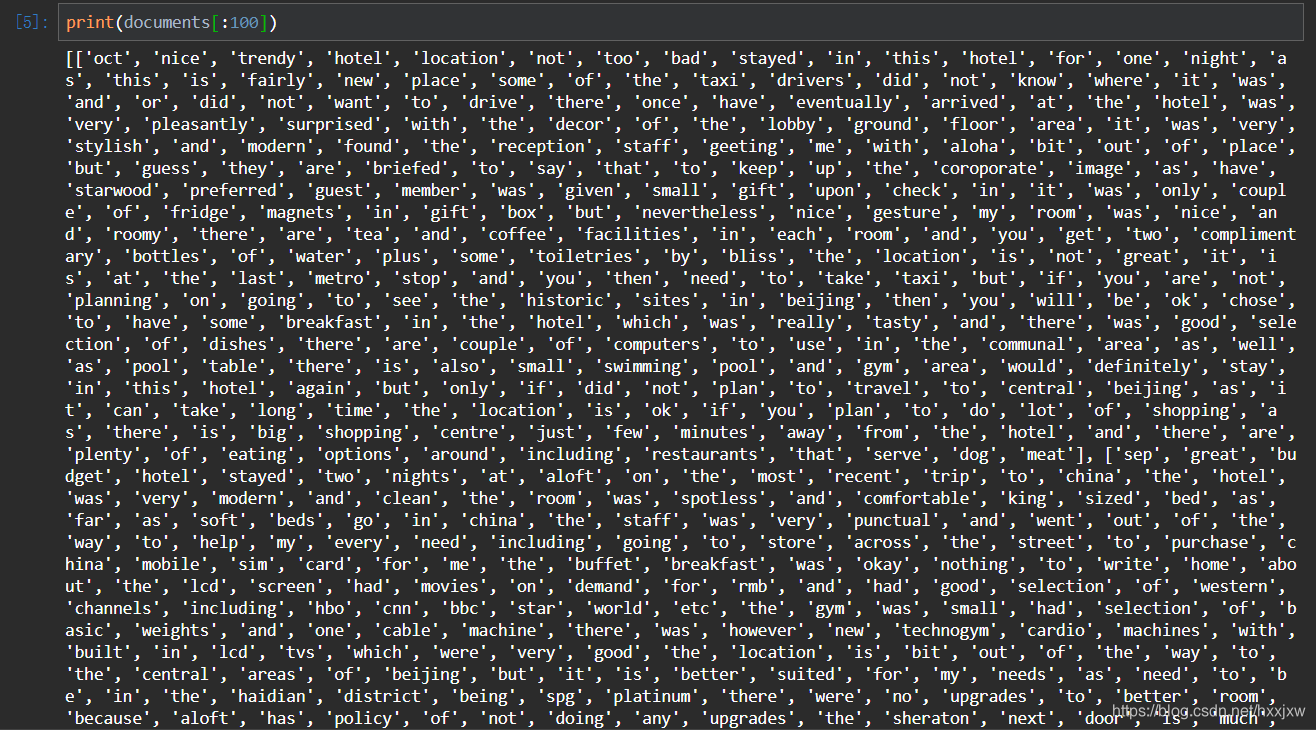
import gzip import gensim import logging#logging格式设置 logging.basicConfig(format="", level=logging.INFO)#解压我们的数据 data_file = "reviews_data.txt.gz"with gzip.open(data_file,'rb') as f:for i, line in enumerate(f):print(line)break#--------------下一步需要把读的数据变为gensim的输入------------------------#把gzip文件的内容读入到list def read_input(input_file):logging.info("reading file {0}...this may take a while".format(input_file))with gzip.open(input_file,'rb') as f:for i, line in enumerate(f):if(i%10000 == 0):logging.info("read {0} reviews".format(i))#做预处理,每个review返回一个单词列表yield gensim.utils.simple_preprocess(line)documents = list(read_input((data_file))) logging.info("Done reading data file") print(documents)
训练model
import gzip import gensim import logging#logging格式设置 logging.basicConfig(format="", level=logging.INFO)#解压我们的数据 data_file = "reviews_data.txt.gz"with gzip.open(data_file,'rb') as f:for i, line in enumerate(f):print(line)break#--------------下一步需要把读的数据变为gensim的输入------------------------#把gzip文件的内容读入到list def read_input(input_file):logging.info("reading file {0}...this may take a while".format(input_file))with gzip.open(input_file,'rb') as f:for i, line in enumerate(f):if(i%10000 == 0):logging.info("read {0} reviews".format(i))#做预处理,每个review返回一个单词列表yield gensim.utils.simple_preprocess(line)documents = list(read_input((data_file))) logging.info("Done reading data file") print(documents)#--------------训练我们的model-------------model = gensim.models.Word2Vec(documents, size=150,window=10, min_count=2,workers=10)#不加这句,光上面那句也能训练,这句是给训练的时候规定一些参数,比如epochs,这里规定了10,如果不规定默认是5的 model.train(documents,total_examples=len(documents), epochs=10)
我们可以通过训练好的模型做什么呢?
我们要做的是,给出一个之前语料中没有出现的词,然后能够在语料中找一个最相近的
能够计算两个单词之间的相似度
能够在几个单词中找出意思和其他单词相差较大的单词来
找和polite最相近的6个词
找和france最相近的6个词
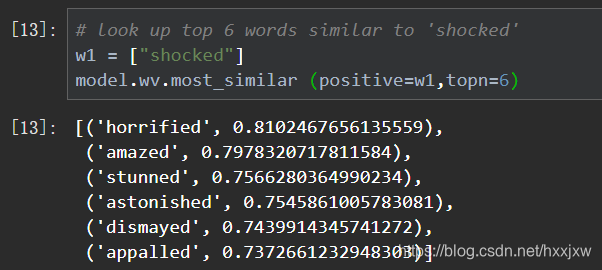
找和shocked最相近的6个词
寻找床上用品相关的词
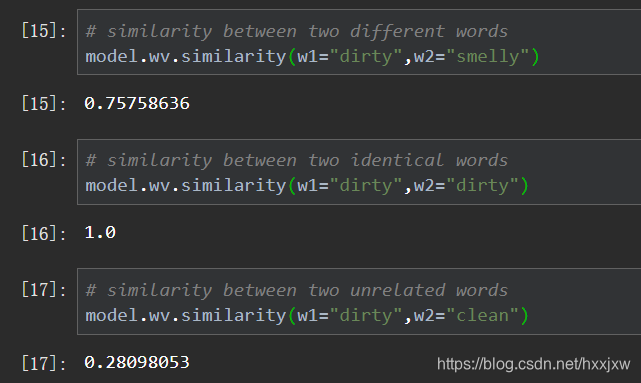
计算两个单词之间的相似度
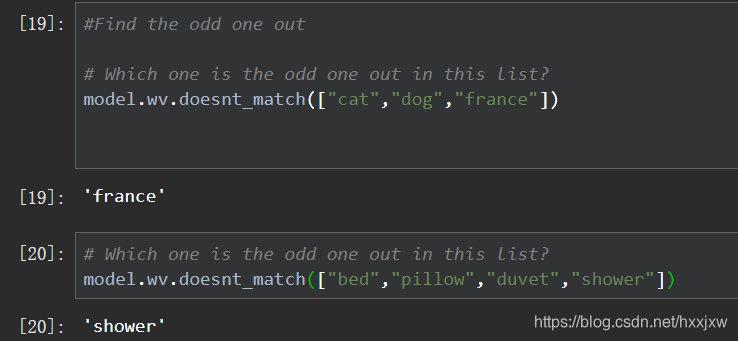
在几个单词中找到意思和其他单词相差较大的单词,即the odd one
总程序
import gzip import gensim import logging#logging格式设置 logging.basicConfig(format="", level=logging.INFO)#解压我们的数据 data_file = "reviews_data.txt.gz"with gzip.open(data_file,'rb') as f:for i, line in enumerate(f):print(line)break#--------------下一步需要把读的数据变为gensim的输入------------------------#把gzip文件的内容读入到list def read_input(input_file):logging.info("reading file {0}...this may take a while".format(input_file))with gzip.open(input_file,'rb') as f:for i, line in enumerate(f):if(i%10000 == 0):logging.info("read {0} reviews".format(i))#做预处理,每个review返回一个单词列表yield gensim.utils.simple_preprocess(line)documents = list(read_input((data_file))) logging.info("Done reading data file") # print(documents)#--------------训练我们的model-------------model = gensim.models.Word2Vec(documents, size=150,window=10, min_count=2,workers=10)#不加这句,光上面那句也能训练,这句是给训练的时候规定一些参数,比如epochs,这里规定了10,如果不规定默认是5的 model.train(documents,total_examples=len(documents), epochs=10)#------------验证我们的结果-------------------- w1 = "dirty" print(model.wv.most_similar(positive=w1))# look up top 6 words similar to 'polite' w1 = ["polite"] print(model.wv.most_similar (positive=w1,topn=6))# look up top 6 words similar to 'france' w1 = ["france"] print(model.wv.most_similar (positive=w1,topn=6))# look up top 6 words similar to 'shocked' w1 = ["shocked"] print(model.wv.most_similar (positive=w1,topn=6))# get everything related to stuff on the bed w1 = ["bed",'sheet','pillow'] w2 = ['couch'] print(model.wv.most_similar (positive=w1,negative=w2,topn=10))# similarity between two different words print(model.wv.similarity(w1="dirty",w2="smelly"))# similarity between two identical words print(model.wv.similarity(w1="dirty",w2="dirty"))# similarity between two unrelated words print(model.wv.similarity(w1="dirty",w2="clean"))#Find the odd one out# Which one is the odd one out in this list? print(model.wv.doesnt_match(["cat","dog","france"]))# Which one is the odd one out in this list? print(model.wv.doesnt_match(["bed","pillow","duvet","shower"]))




这篇关于使用Gensim库来实现Word2Vec的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






