本文主要是介绍1852_bash中的find应用扩展,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Grey
全部学习内容汇总: https://github.com/GreyZhang/toolbox
1852_bash中的find应用扩展
find这个工具我用了好多年了,但是是不是真的会用呢?其实不然,否则也不会出现这种总结式的笔记。其实,注意部分小细节之后,find可以很好的实现我们对于文件存放位置的搜索需要。
主题由来介绍
一直以来,我用find直接搜索我磁盘上的文件去看是否有重复的文件可以清除。常用的一种方式为,首先切换到磁盘根目录,之后执行如下的命令:
find -iname *keyword*
我通过上面的搜索命令来匹配带有关键词的文件,-iname用以说明执行的方式是按照忽略大小写形式搜索文件名称。一直以来,在我的树莓派以及NAS上做这样的搜索到时没遇到啥问题。但是,偶然一次我在git bash中搜索 emacs lisp所有文件的时候失败了。我输入了如下的命令:
find -iname *.el
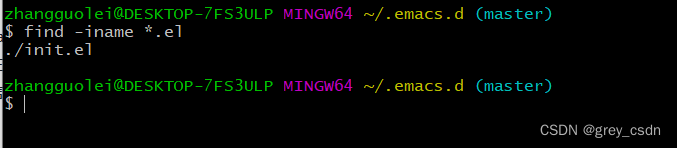
这是我搜索出来的结果,我知道我的这个目录中这样的文件很多,因此接着就发现了不正确。其实,我这一次的搜索命令格式与之前的确也有不同,这一次的表达式中少了一个星号。不过,还是看得出来我对这个命令掌握的不是很熟悉。
为了排除这个是工具的问题,同样的测试我在不同的平台上都做了尝试。同时,我还查看了软件的版本,首先确认全都是GNU的工具,最多版本略有差异。结果,在不同的平台上测试下来也是如此。为此,我觉得我应该探索并总结下find的用法了。
资料寻找与分析
这样的资料还是很多的,一如既往,我还是以英文搜索为主: Find Command in Linux (Find Files and Directories) | Linuxize
这一次找到的资料网页,广告有一些多,占据了几乎将近一半的版面。不过还好,知识内容还是值得的。
- 我前面操作失败似乎一个特点就是没有进行目录级的操作,只是搜索了当前的目录。而find本身是具备这样的功能的,这毫无疑问,之前也已经用过很多了。
- 除了简单的文件名称搜索之外,find其实还可以搜索很多其他的属性,比如说权限、类型、日期、拥有者、大小等。从这里的属性看,其实这个也是更多的在unix的平台上使用。
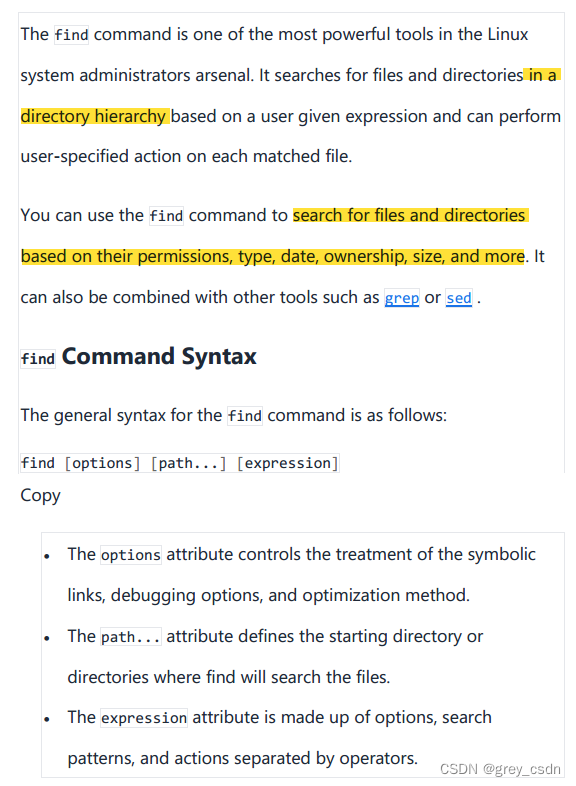
- 这里给出来了这个命令的基本语法形式,从这里看,其实我平时的用法少了很多参数。可能正好有默认的行为满足了我的搜索需求。
- 上面的三段参数分别是文件的属性信息、搜索的目录、搜索内容形式。
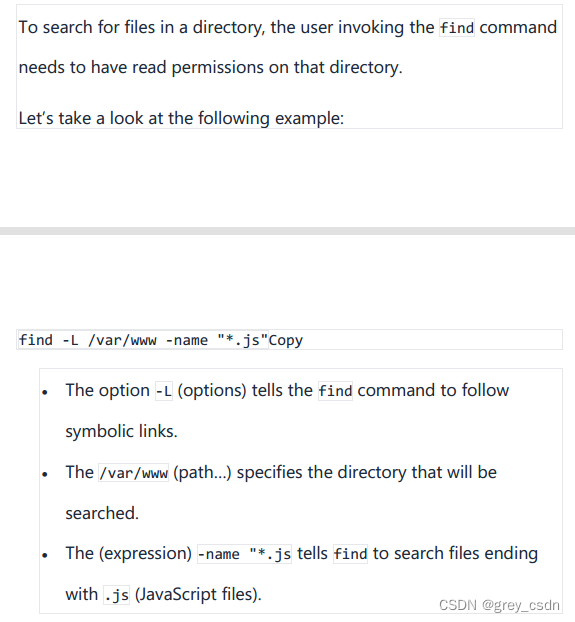
- 首先需要说明的是上面的例子中,Copy是多余的。
- 这个搜索的命令形式很好懂,不过为什么是符号链接我不是很清楚。不知道是否是快捷方式之类的?不过话又说回来,可能我用到的概率并不会很大。

- 按照文件名称搜索,这个可能是我用到的最多的一种用法。
- -iname中的i代表忽略大小写,这个也很容易记忆。

- 这一个例子我觉得对我来说很有用。
- 首先是学到了一个按照类型处理的方式。
- 接下来,着色的部分很可能是我之前遇到问题的原因。稍后,我增加转义做一个测试看看效果。
- 最后,还可以通过-not来搜索不满足的结果。
- 这样综合看下来,搜索的功能以及有很大的灵活度了。而且,从扩展名的搜索这部分来看,其实使用的搜索方式还是正则表达式。
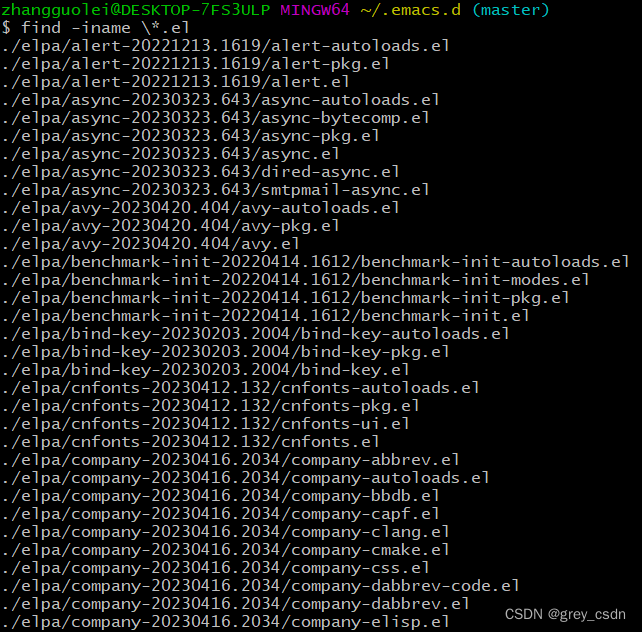
- 通过上面的结果看,通过转义的操作的确是让之前“异常”的搜索出现了期待的结果。
- 不过,结合上面的说明,后续最好还是规范化一些不要继续使用缺省的参数造成误解。
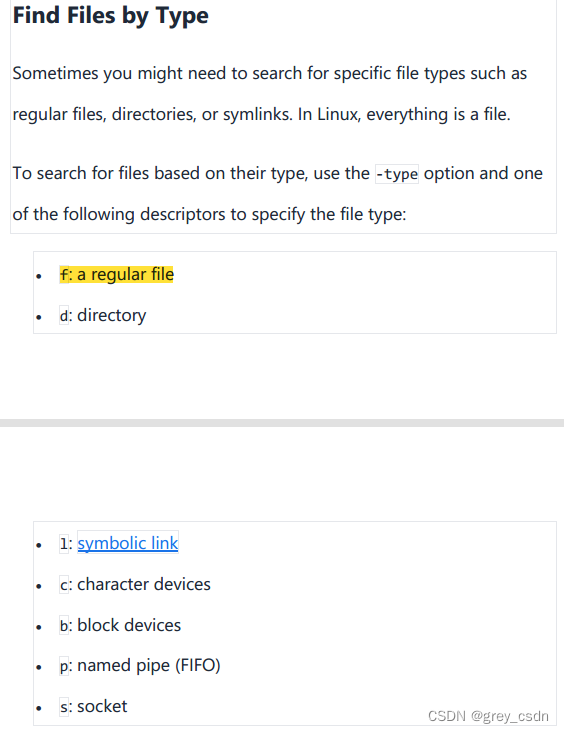
- 针对前面看到的例子中type后面的参数f,这里也看到了解释的信息。

- 这里给出来了一个按照大小来搜索文件的方式,里面可以选择不同的单位。
- 实际的测试中,这个选项可以跟其他的选项组合使用。
- 如果需要大于对应大小的文件,可以在参数之前写一个+,如果小于则是写-。
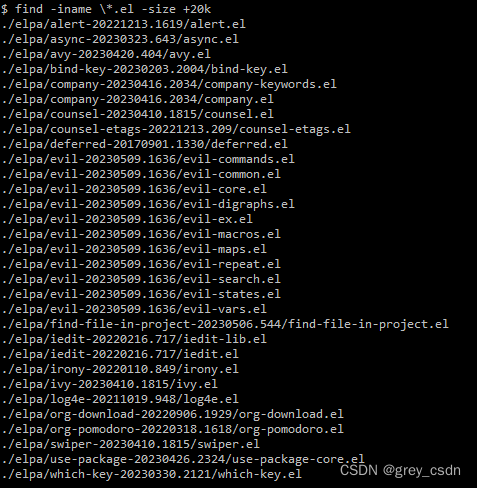
- 上面是实际测试的一个效果。
其他
除了上面的信息之外,find还支持按照权限、所有者、用户组以及时间等信息进行搜索。目前看来,我现在的需要可能是比较纯粹的文件内容管理。因此上面的内容暂且可以不去尝试了。
小结
简单了解了一下,算是又增加了一些见识。不过,从了解的过程中看得出来,现在了解的功能还是比较皮毛的内容。比如说,如何更好地使用正则表达式来进行搜索等。这些,留待以后有需要的时候再去探索。
这篇关于1852_bash中的find应用扩展的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



