本文主要是介绍YOLOv5改进 | 2023 | CARAFE提高精度的上采样方法(助力细节长点),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、本文介绍
本文给大家带来的CARAFE(Content-Aware ReAssembly of FEatures)是一种用于增强卷积神经网络特征图的上采样方法。其主要旨在改进传统的上采样方法(就是我们的Upsample)的性能。CARAFE的核心思想是:使用输入特征本身的内容来指导上采样过程,从而实现更精准和高效的特征重建。CARAFE是一种即插即用的上采样机制其本身并没有任何的使用限制。所以在YOLOv5的改进中其也可以做到一个提高精度的改进方法
专栏回顾:YOLOv5改进专栏——持续复现各种顶会内容——内含100+创新
实验效果图如下所示->

目录
一、本文介绍
二、CARAFE的机制原理
2.1 CARAFE的基本原理
2.2 图解CARAFE原理
2.3 CARAFE的效果图
三、CARAFE的复现源码
四、手把手教你添加CARAFE机制
4.1 细节修改教程
4.1.1 修改一
4.1.2 修改二
4.1.3 修改三
4.1.4 修改四
4.2 CARAFE的yaml文件
4.3 CARAFE运行成功截图
五、本文总结
二、CARAFE的机制原理

论文地址:官方论文地址点击即可跳转
代码地址:官方代码地址点击即可跳转

2.1 CARAFE的基本原理
CARAFE(Content-Aware ReAssembly of FEatures)是一种用于增强卷积神经网络特征图的上采样方法。这种方法首次在论文《CARAFE: Content-Aware ReAssembly of FEatures》中提出,旨在改进传统的上采样方法(如双线性插值和转置卷积)的性能。
CARAFE通过在每个位置利用底层内容信息来预测重组核,并在预定义的附近区域内重组特征。由于内容信息的引入,CARAFE可以在不同位置使用自适应和优化的重组核,从而比主流的上采样操作符(如插值或反卷积)表现更好。
CARAFE包括两个步骤:首先预测每个目标位置的重组核,然后用预测的核重组特征。给定一个尺寸为 H×W×C 的特征图和一个上采样比率 U,CARAFE将产生一个新的尺寸为 UH×UW×C 的特征图。其次CARAFE的核预测模块根据输入特征的内容生成位置特定的核,然后内容感知重组模块使用这些核来重组特征。
CARAFE可以无缝集成到需要上采样操作的现有框架中。在主流的密集预测任务中,CARAFE对高级和低级任务(如对象检测、实例分割、语义分割和图像修复)都有益处,且额外的参数微不足道。
2.2 图解CARAFE原理
下图是CARAFE工作机制的示意图。左侧展示了来自Mask R-CNN的多层FPN(特征金字塔网络)特征(直至虚线左侧),右侧展示了集成了CARAFE的Mask R-CNN(直至虚线右侧)。对于采样的位置,该图显示了FPN自上而下路径中累积重组的区域。这样一个区域内的信息被重组到相应的重组中心。

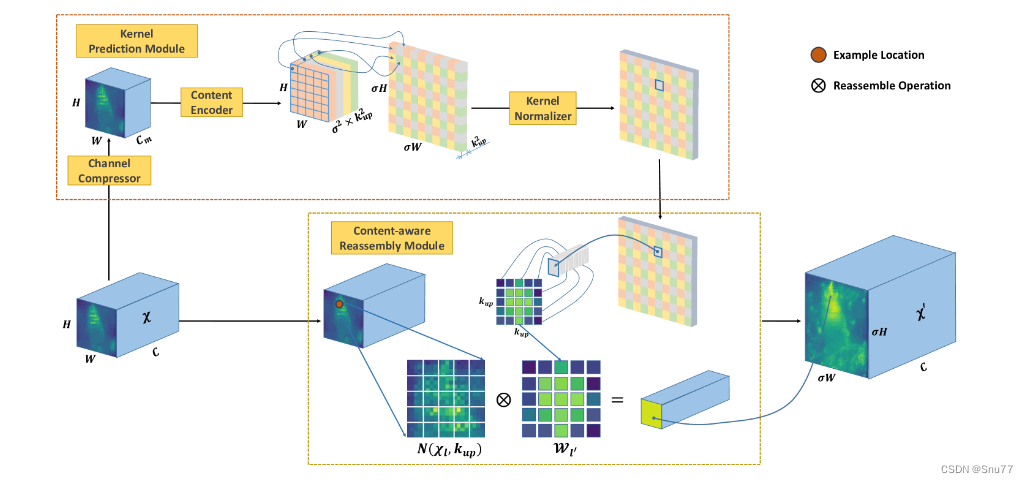
下图展示了CARAFE的整体框架。CARAFE由两个关键部分组成,即核预测模块和内容感知重组模块。在这个框架中,一个尺寸为 H×W×C 的特征图被上采样因子 U(=2) 倍。
下图展示了集成了CARAFE的特征金字塔网络(FPN)架构。在这个架构中,CARAFE在FPN的自上而下路径中将特征图的尺寸上采样2倍。CARAFE通过无缝替换最近邻插值而整合到FPN中,从而优化了特征上采样的过程。

2.3 CARAFE的效果图
下图比较了COCO 2017验证集上基线(上面)和CARAFE(下面)在实例分割结果方面的差异。
总结:我个人觉得其实其效果提升比较一般甚至某些数据集上提点很微弱,但是它主要的作用是减少计算量是一个更加轻量化的上采样方法。

三、CARAFE的复现源码
我们将在“ultralytics/nn/modules”目录下面创建一个文件将其复制进去,使用方法在后面会讲。
import torch
import torch.nn as nn
from ultralytics.nn.modules import Convclass CARAFE(nn.Module):def __init__(self, c, k_enc=3, k_up=5, c_mid=64, scale=2):""" The unofficial implementation of the CARAFE module.The details are in "https://arxiv.org/abs/1905.02188".Args:c: The channel number of the input and the output.c_mid: The channel number after compression.scale: The expected upsample scale.k_up: The size of the reassembly kernel.k_enc: The kernel size of the encoder.Returns:X: The upsampled feature map."""super(CARAFE, self).__init__()self.scale = scaleself.comp = Conv(c, c_mid)self.enc = Conv(c_mid, (scale * k_up) ** 2, k=k_enc, act=False)self.pix_shf = nn.PixelShuffle(scale)self.upsmp = nn.Upsample(scale_factor=scale, mode='nearest')self.unfold = nn.Unfold(kernel_size=k_up, dilation=scale,padding=k_up // 2 * scale)def forward(self, X):b, c, h, w = X.size()h_, w_ = h * self.scale, w * self.scaleW = self.comp(X) # b * m * h * wW = self.enc(W) # b * 100 * h * wW = self.pix_shf(W) # b * 25 * h_ * w_W = torch.softmax(W, dim=1) # b * 25 * h_ * w_X = self.upsmp(X) # b * c * h_ * w_X = self.unfold(X) # b * 25c * h_ * w_X = X.view(b, c, -1, h_, w_) # b * 25 * c * h_ * w_X = torch.einsum('bkhw,bckhw->bchw', [W, X]) # b * c * h_ * w_return X四、手把手教你添加CARAFE机制
4.1 细节修改教程
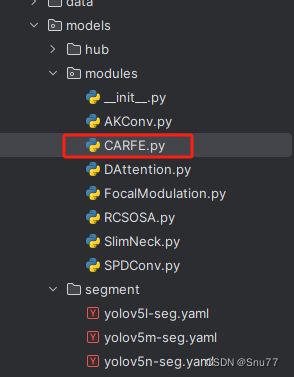
4.1.1 修改一
我们找到如下的目录'yolov5-master/models'在这个目录下创建一整个文件目录(注意是目录,因为我这个专栏会出很多的更新,这里用一种一劳永逸的方法)文件目录起名modules,然后在下面新建一个文件,将我们的代码复制粘贴进去。
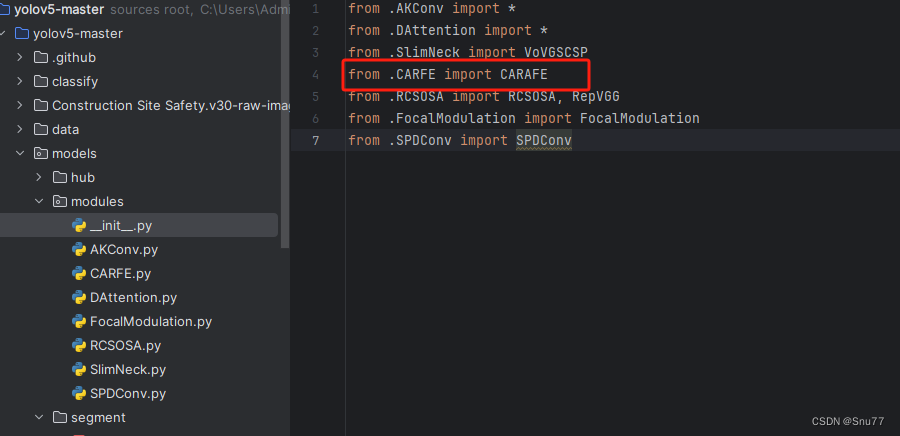
4.1.2 修改二
然后新建一个__init__.py文件,然后我们在里面添加一行代码。注意标记一个'.'其作用是标记当前目录。
4.1.3 修改三
然后我们找到如下文件''models/yolo.py''在开头的地方导入我们的模块按照如下修改->
(如果你看了我多个改进机制此处只需要添加一个即可,无需重复添加。)

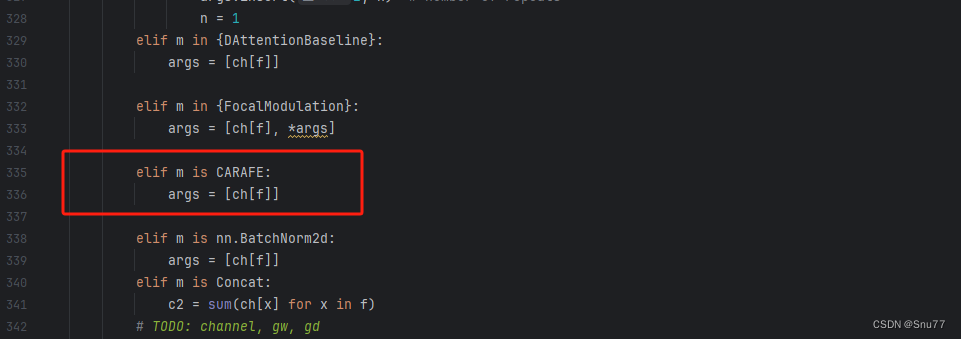
4.1.4 修改四
然后我们找到parse_model方法,按照如下修改->
到此就修改完成了,复制下面的ymal文件即可运行。
4.2 CARAFE的yaml文件
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, CARAFE, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, CARAFE, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
4.3 CARAFE运行成功截图
附上我的运行记录确保我的教程是可用的。

五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv5改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv5改进专栏——持续复现各种顶会内容——内含100+创新

这篇关于YOLOv5改进 | 2023 | CARAFE提高精度的上采样方法(助力细节长点)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







