本文主要是介绍1 文本分词与红楼梦文本分词应用 --- 机器学习之文本挖掘,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:Irain
QQ:2573396010
微信:18802080892
GitHub项目链接:https://github.com/Irain-LUO/machine_learning
视频资源链接:https://www.bilibili.com/video/BV1FJ411B7S1?p=61
目录
- 1 下载jieba库
- 2 jieba库自带的dict词典
- 3 分词示例
- 3.1分词的三种模式
- 3.2词性标注示例
- 4 词库中更改词
- 5 加载自定义词库
- 6 改变词频
- 7 提取固定数量的关键词
- 8 返回词语的位置
- 8.1 默认模式:返回词语的位置
- 8.2 搜索引擎模式,返回词语的位置
- 9 红楼梦文本分词应用
1 下载jieba库
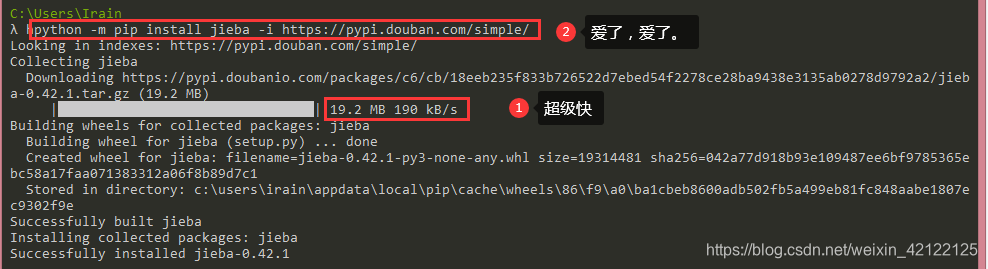
下载命令(为快不破):pip install jieba -i https://pypi.douban.com/simple/

下载命令(受不了):pip install jieba
2 jieba库自带的dict词典
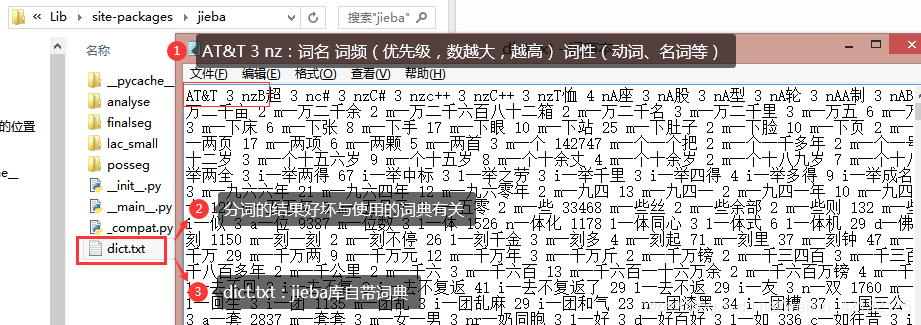
3 分词示例
3.1分词的三种模式

import jieba
sentence = "我是一位火影忍者超级脑残粉迷"
print(sentence)
print("-"*30,"全模式切分","-"*30)
cut1 = jieba.cut(sentence,cut_all=True)
print("cut函数返回类型:",type(cut1))
for cut in cut1:print(cut)print("-"*30,"精准模式切分","-"*30)
cut2 = jieba.cut(sentence,cut_all=False)
print("cut函数返回类型:",type(cut2))
for cut in cut2:print(cut)print("-"*30,"搜索引擎模式切分","-"*30)
cut3 = jieba.cut_for_search(sentence)
print("cut函数返回类型:",type(cut3))
for cut in cut3:print(cut)print("-"*30,"默认模式:精准模式切分","-"*30)
cut4 = jieba.cut(sentence)
print("cut函数返回类型:",type(cut4))
for cut in cut4:print(cut)
3.2词性标注示例

'''
a:形容词、c:连词、d:副词、e:叹词、f:方位词、i:成语、m:数词、n:名词
nr:人名、ns:地名、nt:机构团体、nz:其他专有名词、p:介词、r:代词、t:时间
u:助词、v:动词、vn:动名词、w:标点符号、un:未知词语
'''
print("-"*30,"词性标注","-"*30)
import jieba.posseg
cut5 = jieba.posseg.cut(sentence)
print("cut函数返回类型:",type(cut5))
print("词 --- 词性")
for cut in cut5:print(cut.word + "---" + cut.flag)
4 词库中更改词
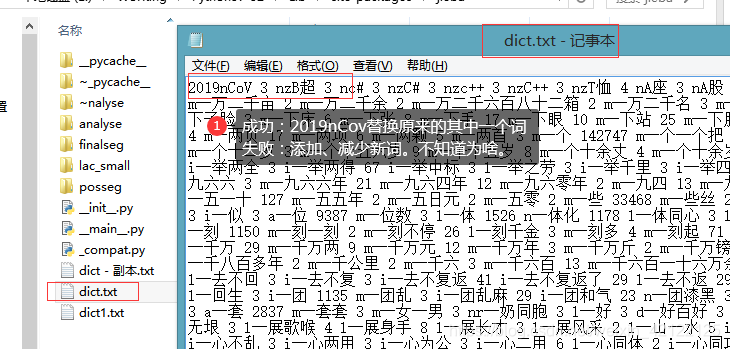




自定义词库的词性可以省略
5 加载自定义词库

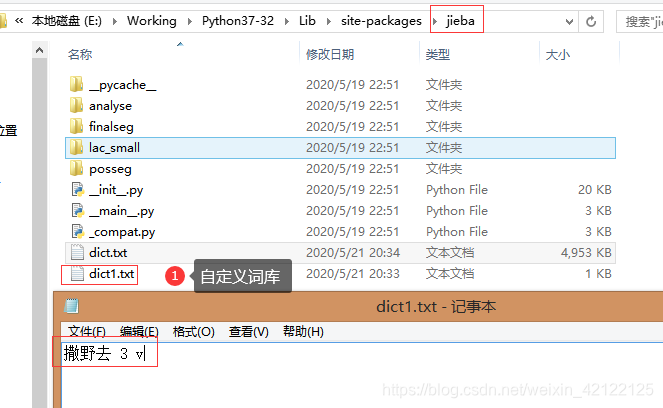
sentence = "撒野去是一位火影忍者超级脑残粉迷"
print("-"*30,"自定义词库 ","-"*30)
jieba.load_userdict("E:/Working/Python37-32/Lib/site-packages/jieba/dict1.txt")
import jieba.posseg
cut6 = jieba.posseg.cut(sentence)
print("cut函数返回类型:",type(cut6))
print("词 --- 词性")
for cut in cut6:print(cut.word + "---" + cut.flag)
6 改变词频

print("-"*30,"更改词频","-"*30)
cut7 = jieba.cut(sentence)
print("cut函数返回类型:",type(cut7))
for cut in cut7:print(cut)
print("")
jieba.suggest_freq("粉迷",True)
cut7 = jieba.cut(sentence)
print("cut函数返回类型:",type(cut7))
for cut in cut7:print(cut)
print("")
7 提取固定数量的关键词

import jieba.analyse
print("-"*30,"提取固定数量的关键词","-"*30)
cut8 = jieba.analyse.extract_tags(sentence,2)
print("cut函数返回类型:",type(cut8))
for cut in cut8:print(cut)
8 返回词语的位置
8.1 默认模式:返回词语的位置

print("-"*30,"默认模式:返回词语的位置","-"*30)
cut9 = jieba.tokenize(sentence)
print("cut函数返回类型:",type(cut9))
for cut in cut9:print(cut)8.2 搜索引擎模式,返回词语的位置

print("-"*30,"搜索引擎模式,返回词语的位置","-"*30)
cut10 = jieba.tokenize(sentence,mode="serach")
print("cut函数返回类型:",type(cut10))
for cut in cut10:print(cut)
print("")
9 红楼梦文本分词应用


红楼梦文本下载链接:一生只爱红楼梦
print("-"*30,"红楼梦文本分词应用","-"*30)
data = open("红楼梦.txt",'r',encoding='utf-8').read()
cut12 = jieba.analyse.extract_tags(data,30)
print(cut12)
发布:2020年5月21日
这篇关于1 文本分词与红楼梦文本分词应用 --- 机器学习之文本挖掘的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




