本文主要是介绍机器学习中的混沌工程:拥抱不可预测性以增强系统鲁棒性埃,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、介绍
在动态发展的技术世界中,机器学习 (ML) 已成为一股革命力量,推动各个领域的创新。然而,随着机器学习系统的复杂性不断增加,确保其可靠性和鲁棒性已成为首要问题。这就是混沌工程发挥作用的地方,混沌工程是一门旨在通过故意引入干扰来增强系统弹性的学科。在本文中,我们探讨了机器学习背景下的混沌工程概念、其意义、方法、挑战和未来影响。

拥抱混沌:在机器学习错综复杂的舞蹈中,在不确定性中采取的步骤编排了最具弹性的系统。
二、了解混沌工程
混沌工程最初是为分布式计算系统开发的,它是一种主动方法,可以在弱点表现为灾难性故障之前发现它们。通过有意地将故障或异常情况注入系统,它允许团队评估和改进对不可预见的中断的响应。在机器学习中,这不仅意味着测试软件基础设施,还意味着测试数据管道、算法和模型。
三、机器学习的意义
- 复杂性和不确定性:机器学习系统本质上是复杂的,具有多层算法、庞大的数据集和复杂的依赖关系。这种复杂性,再加上现实世界数据的不可预测性,使它们容易受到异常的影响,从而导致模型故障或性能下降。
- 确保鲁棒性:通过模拟中断,混沌工程能够识别和纠正机器学习系统中的弱点。这增强了它们的稳健性,确保它们在各种和意外的条件下可靠地运行。
- 建立信心:为了使机器学习系统值得信赖,特别是在医疗保健或自动驾驶汽车等关键应用中,利益相关者需要保证其弹性。混沌工程通过展示面对混乱的稳定性来实现这一点。
四、机器学习混沌工程方法论
- 数据扰动:在数据中引入噪声或错误,以测试机器学习模型针对低质量或对抗性输入的恢复能力。
- 模型压力测试:在极端或异常数据条件下对 ML 模型施加压力,以评估其性能边界。
- 依赖失败模拟:测试 ML 系统在依赖服务或资源失败时如何反应。
- 资源约束:限制计算资源以观察 ML 模型如何应对此类约束。
五、挑战和考虑因素
- 平衡风险和学习:故意引入故障需要仔细平衡,以确保学习不会造成重大损害或中断。
- 道德考虑:在医疗保健等高风险领域,任何形式的测试都必须在道德上合理,并且不应损害用户安全。
- 实现的复杂性:由于机器学习系统的复杂性,在机器学习系统中设计和执行混沌实验可能会很复杂。
- 解释结果:理解 ML 背景下的混沌实验的结果需要对该领域和 ML 系统的复杂性有深入的了解。
六、未来的影响
随着机器学习系统继续渗透到生活的各个方面,其稳健性和可靠性变得越来越重要。混沌工程提供了实现这一目标的途径,但它需要不断发展才能跟上机器学习领域的进步。未来的方向可能涉及自动化混沌实验、与人工智能集成以预测潜在故障,以及开发机器学习中混沌工程的标准化实践。
七、代码
为机器学习中的混沌工程创建完整的 Python 代码示例涉及几个步骤。我们将创建一个综合数据集,构建一个基本的机器学习模型,然后应用混沌工程原理来引入和可视化中断。这将有助于理解模型在各种压力条件下的行为。
第 1 步:创建综合数据集
我们将使用numpy和scikit-learn为分类问题创建一个简单的合成数据集。
第 2 步:构建基本的机器学习模型
scikit-learn为此,我们将使用一个基本分类器。
第三步:应用混沌工程原理
- 数据扰动:我们将向数据集引入噪声并观察模型的性能如何受到影响。
- 资源约束:我们将通过限制模型可用的数据大小或功能来模拟资源约束。
- 依赖失败模拟:这可以通过随机删除功能或样本来模拟。
第四步:可视化
我们将使用matplotlib或seaborn来可视化这些扰动对模型性能的影响。
让我们首先实现这些步骤的代码:
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt# Step 1: Create a Synthetic Dataset
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# Step 2: Build a Basic Machine Learning Model
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
initial_accuracy = accuracy_score(y_test, model.predict(X_test))# Function to apply chaos
def apply_chaos(X, y, model, chaos_type="noise", severity=1):X_chaos = X.copy() # Ensure we don't modify the original dataif chaos_type == "noise":noise = np.random.normal(0, severity, X.shape)X_chaos += noiseelif chaos_type == "feature_drop":# Randomly choose some features to set to zeron_features_to_drop = int(X.shape[1] * severity)features_to_drop = np.random.choice(X.shape[1], n_features_to_drop, replace=False)X_chaos[:, features_to_drop] = 0elif chaos_type == "drop_samples":# Randomly drop some samplesdrop_idx = np.random.choice(X.shape[0], int(X.shape[0] * severity), replace=False)X_chaos, y_chaos = np.delete(X, drop_idx, axis=0), np.delete(y, drop_idx)return accuracy_score(y_chaos, model.predict(X_chaos))return accuracy_score(y, model.predict(X_chaos))# Apply the adjusted chaos types
chaos_types = ["noise", "feature_drop", "drop_samples"]
severity_levels = np.linspace(0.1, 0.5, 5)
results = {chaos: [] for chaos in chaos_types}for chaos in chaos_types:for severity in severity_levels:acc = apply_chaos(X_test, y_test, model, chaos_type=chaos, severity=severity)results[chaos].append(acc)# Step 4: Visualization
plt.figure(figsize=(10, 6))
for chaos, accuracies in results.items():plt.plot(severity_levels, accuracies, label=f'{chaos} chaos')plt.axhline(y=initial_accuracy, color='r', linestyle='--', label='Initial Accuracy')
plt.xlabel('Severity of Chaos')
plt.ylabel('Model Accuracy')
plt.title('Effect of Chaos Engineering on Model Performance')
plt.legend()
plt.show()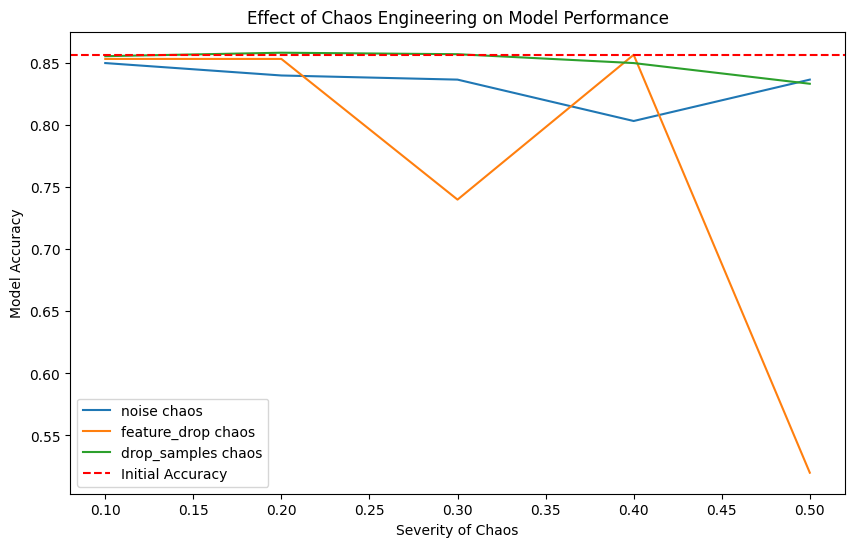
该脚本将可视化随机森林模型的准确性在不同严重程度的不同类型的混乱下如何波动。请记住,这是说明该概念的基本示例。现实世界的应用程序可能需要更复杂的方法。
八、结论
机器学习中的混沌工程代表了一种前瞻性的方法,可确保在不可预测性是唯一确定性的世界中系统的弹性。通过拥抱混乱,机器学习从业者可以构建不仅强大、可靠,而且成为我们技术领域值得信赖的组成部分的系统。这一学科虽然具有挑战性,但对于关键应用中机器学习系统的可持续增长和集成至关重要,从而塑造一个技术能够弹性地经受不可预测的世界考验的未来。
这篇关于机器学习中的混沌工程:拥抱不可预测性以增强系统鲁棒性埃的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






