本文主要是介绍c语言快速排序(霍尔法、挖坑法、双指针法)图文详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
快速排序介绍:
快速排序是一种非常常用的排序方法,它在1962由C. A. R. Hoare(霍尔)提的一种二叉树结构的交换排序方法,故因此它又被称为霍尔划分,它基于分治的思想,所以整体思路是递归进行的。
整体思路:
1.先选取一个key,关于key值的选取,一般是选数组第一个元素,数组中间元素,数组最后一个元素,这三个元素的中间值,并将这个元素与数组第一个元素进行交换。
2.将key放入整个区间中正确的位置,即为key左边的元素都比key小,右边的元素都比key要大,此时的key就是它排好序的位置,注意key左边的元素都比它小,但不一定有序,右边也是一样,然后根据递归的思想,再对key左边的区间进行上面一样的操作和key右边的区间进行上面一样的的操作,当区间不存在或者区间只有一个元素时返回。
如何将key放入正确的位置:
将key放入正确的位置正是每趟递归需要做的,那么具体该如何实现呢?
实现过程目前有三种方法,每种方法虽然写法不同,但总体思路一样,所以效率是相同的,只要完全理解快速排序,写哪种都一样。
1.霍尔版本(传统方法)
第一步:定义一个right从数组最后一个元素开始即数组的右边开始向左边遍历,如果找到比key小的值就停下来。
第二步:定义一个left从数组第一个元素开始即数组的左边开始向右遍历,如果找到比key大的值就停下来。
第三步:left和right都停下来之后,交换left和right的值,这一步的目的就是将比key小的值往左放,将比key大的值。
第四步:当left和right相遇后,将第一个元素(即为key的值)与它们相遇位置的值交换。
第五步:让他们相遇位置的左区间和右区间同样执行上述四步(即为递归)。
动态思路图:

代码实现:
void Swap(int* a, int* b)
{int tmp = 0;tmp = *a;*a = *b;*b = tmp;
}int GetMidi(int* a, int begin, int end)
{int midi = (begin + end) / 2;if (a[begin] > a[midi]){if (a[midi] > a[end]){return midi;}else if (a[end] > a[begin]){return begin;}else{return end;}}else{if (a[begin] > a[end]){return begin;}else if (a[end] > a[midi]){return midi;}else{return end;}}
}void QuickSortHoare(int* a, int begin, int end)
{int left = begin;int right = end;if (left >= right){return;}int midi = GetMidi(a, begin, end);Swap(&a[begin], &a[midi]);int keyi = begin;while (left < right){while (left < right && a[right] >= a[keyi]){right--;}while (left < right && a[left] < a[keyi]){left++;}Swap(&a[left], &a[right]);}Swap(&a[left], &a[keyi]);keyi = left;QuickSortHoare(a, begin, keyi - 1);QuickSortHoare(a, keyi + 1, end);
}2.挖坑法:
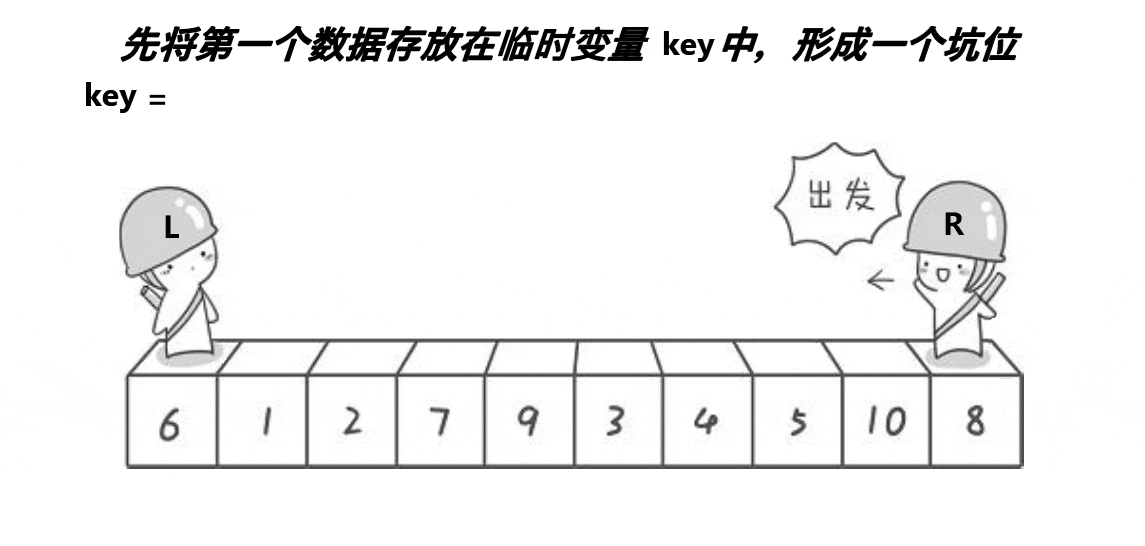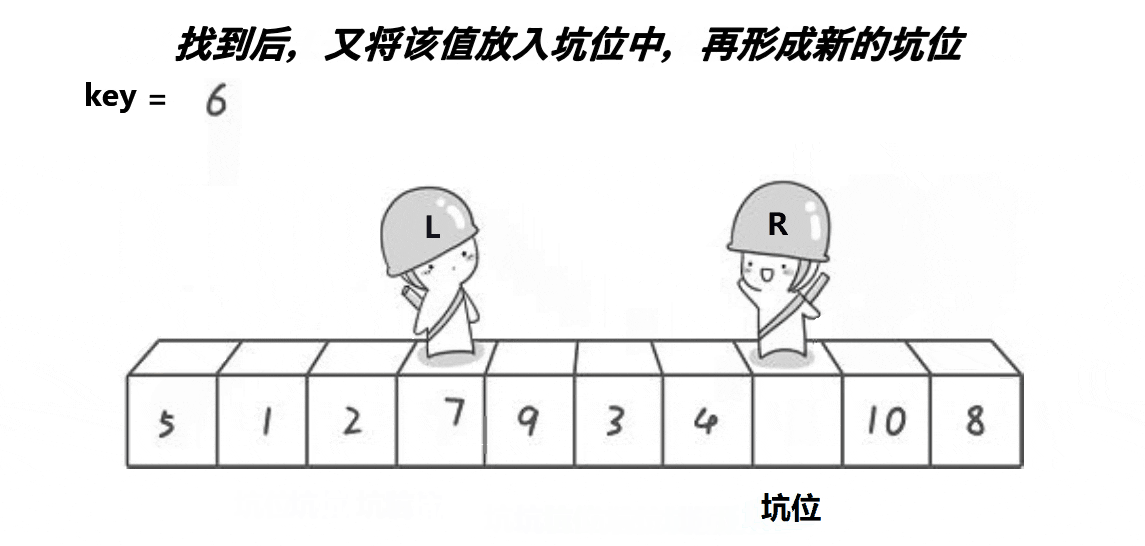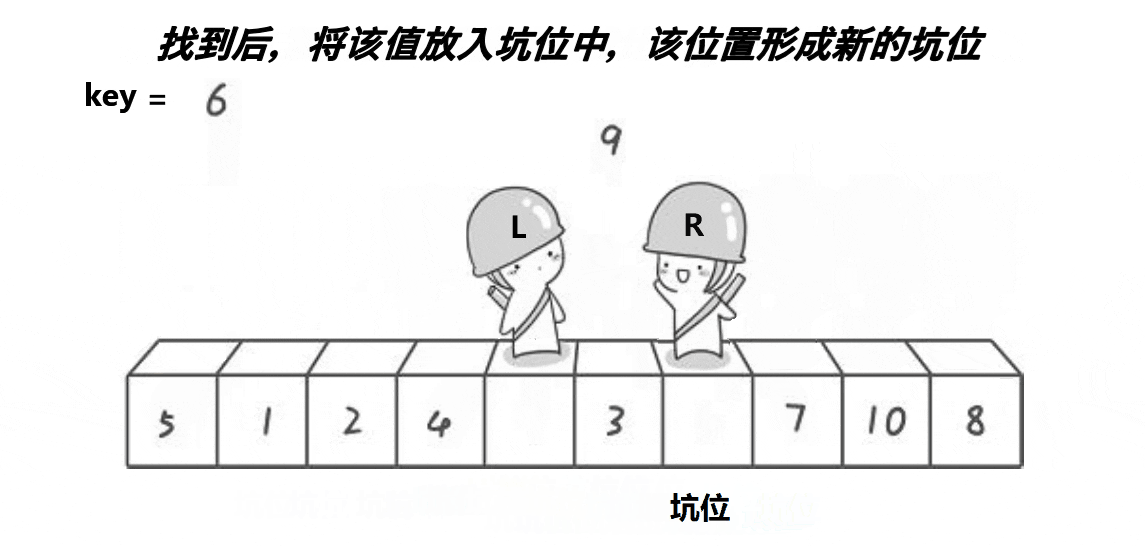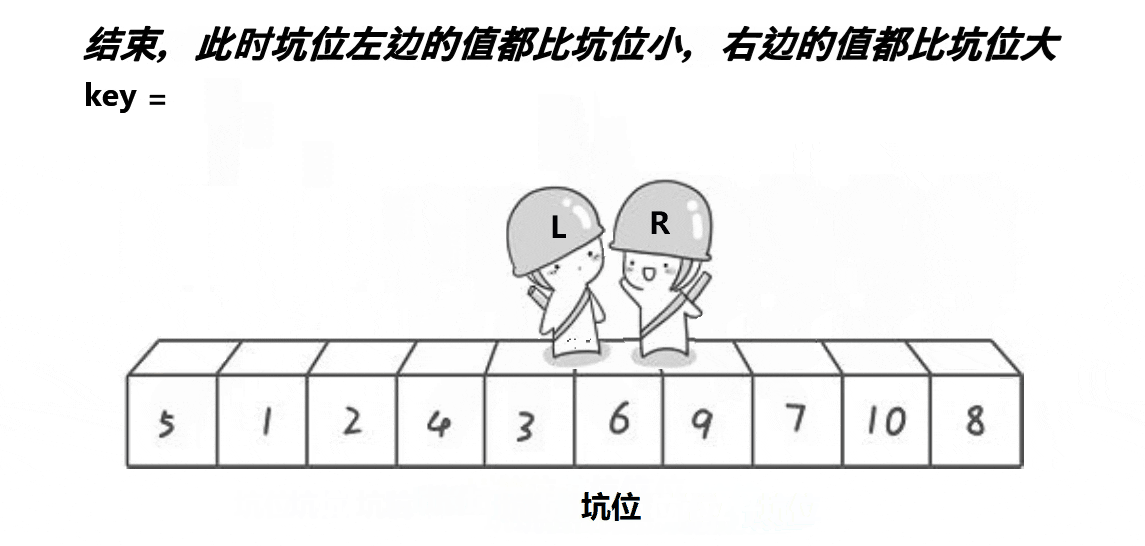
第一步:将key的位置(即为第一个元素的位置)作为第一个坑位,将key的值一直保存在变量key中。
第二步:定义一个right从数组最后一个元素开始即为数组右边开始向左遍历,如果找到比key小的值,right停下来,将right下标访问的元素赋值到上一个坑位,并将right作为新的坑位。
第三步:定义一个left从数组第一个元素开始即为数组左边开始向右遍历,如果找到比key大的值,left停下来,将left下标访问的元素赋值到上一个坑位,并将left作为新的坑位。
第四步:当right和left相遇时,此时它们访问的元素绝对是坑位,只需将key里保存的key值放入坑位即可。
第五步:让他们相遇位置的左区间和右区间同样执行上述四步(即为递归)。
思路图:
代码实现:
void Swap(int* a, int* b)
{int tmp = 0;tmp = *a;*a = *b;*b = tmp;
}int GetMidi(int* a, int begin, int end)
{int midi = (begin + end) / 2;if (a[begin] > a[midi]){if (a[midi] > a[end]){return midi;}else if (a[end] > a[begin]){return begin;}else{return end;}}else{if (a[begin] > a[end]){return begin;}else if (a[end] > a[midi]){return midi;}else{return end;}}
}
void QuickSortHole(int* a, int begin, int end)
{int left = begin;int right = end;if (begin >= end){return;}int midi = GetMidi(a, begin, end);Swap(&a[begin], &a[midi]);int key = a[begin];int hole = begin;while (left < right){while (left < right && a[right] >= key){right--;}a[hole] = a[right];hole = right;while (left < right && a[left] <= key){left++;}a[hole] = a[left];hole = left;}a[hole] = key;int keyi = hole;QuickSortHole(a, begin, keyi - 1);QuickSortHole(a, keyi + 1, end);
}3.双指针法(新手推荐)
第一步:定义两根指针cur和prev,初始位置如下图所示:
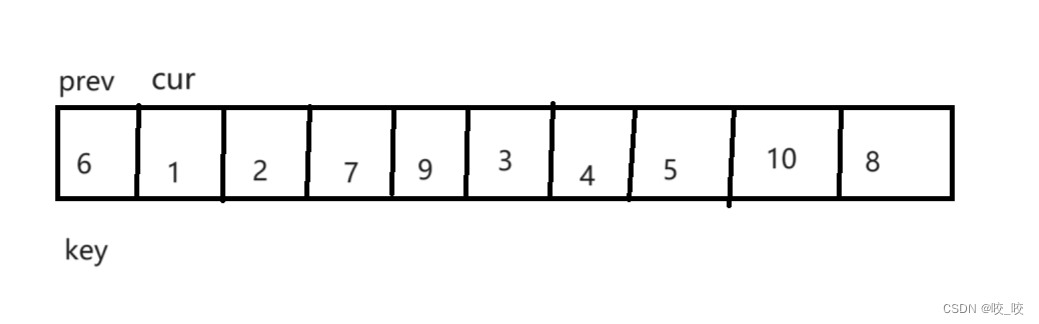
第二步:cur开始往后走,如果遇到比key小的值,则++prev,然后交换prev和cur指向的元素,再++cur,如果遇到比key大的值,则只++cur。
第三步:当cur访问过最后一个元素后,将key的元素与prve访问的元素交换位置。cur访问完整个数组后的各元素位置如下图所示:
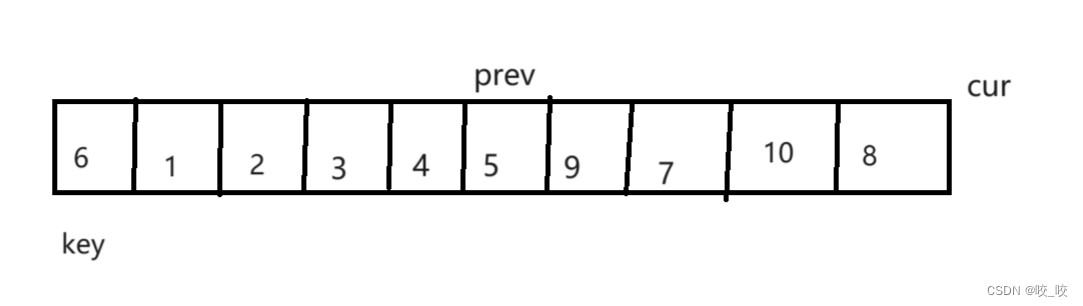
第四步:让prev的左区间和右区间同样执行上述三步(即为递归)。
代码实现:
void Swap(int* a, int* b)
{int tmp = 0;tmp = *a;*a = *b;*b = tmp;
}int GetMidi(int* a, int begin, int end)
{int midi = (begin + end) / 2;if (a[begin] > a[midi]){if (a[midi] > a[end]){return midi;}else if (a[end] > a[begin]){return begin;}else{return end;}}else{if (a[begin] > a[end]){return begin;}else if (a[end] > a[midi]){return midi;}else{return end;}}
}void QuickSortD(int* a, int begin, int end)
{if (begin >= end){return;}int midi = GetMidi(a, begin, end);Swap(&a[begin], &a[midi]);int keyi = begin;int prev = begin;int cur = begin + 1;while (cur <= end){if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[cur], &a[prev]);}cur++;}Swap(&a[keyi], &a[prev]);keyi = prev;QuickSortD(a, begin, keyi - 1);QuickSortD(a, keyi + 1, end);
}下期预告:非递归
这期讲的三种快速排序方法均是采用递归的方法来实现的,那么如何使用非递归来实现快速排序呢?下期我将发布快速排序的非递归法。
这篇关于c语言快速排序(霍尔法、挖坑法、双指针法)图文详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




