本文主要是介绍Re59:读论文 Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文名称:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
模型开源地址:https://huggingface.co/facebook/rag-token-nq
ArXiv下载地址:https://arxiv.org/abs/2005.11401
本文是2020年NeurIPS论文,属于RAG+LLM领域。作者来自Facebook
本文的研究背景也是说直接用LM存储的知识不够,且难以扩展和修正,有幻觉,还是得上检索(提供决策出处,可以更新知识)。
LM是预训练的seq2seq模型(BART),知识库是维基百科的稠密向量索引(用预训练的神经网络实现检索 Dense Passage Retriever (DPR))。要么一次检索一波(per-output basis),要么一个token检索一波(per-token basis)(这个见模型部分)。
其实看起来就是REALM的拓展版,将检索文档改成视为隐变量,然后拓展了下游任务,而且是全链路端到端的训练。
比REALM迟,参考文献里就有REALM。但是不用代价高昂的“salient span masking” pre-training
总之整个工作还是做得很全面的,实验充分,真羡慕啊。
文章目录
- 1. related work
- 2. 模型
- 3. 实验
1. related work
non-parametric memory除检索外的形式:
memory networks
stack-augmented networks
memory layers
RAG知识量大而且不需要额外训练
knowledge-intensive tasks:人们认为没有额外知识就没法做的任务,比如常识题(什么行测)
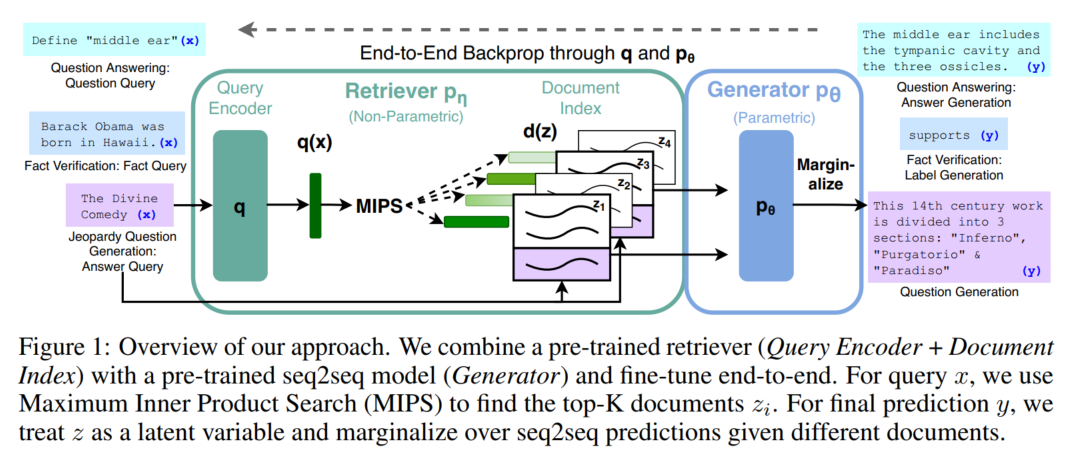
2. 模型
端到端训练:将检索到的文档视为隐变量
RAG-Sequence:对每一篇检索文档都预测完整的生成结果,加总

RAG-Token:每一个token都是大家的机会,每个token上重新检索一次
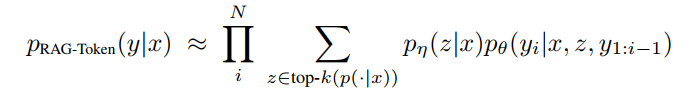
检索器DPR
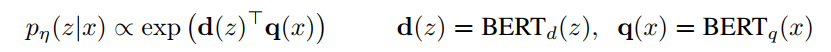
top k:Maximum Inner Product Search (MIPS)问题 ← FAISS
生成器BART
(在实验中只更新query encoder和生成器)
训练时没有检索文档的标注信息。
解码:
- RAG-Token:标准生成任务
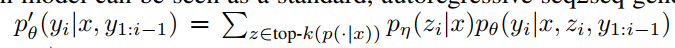
- RAG-Sequence:Thorough Decoding + Fast Decoding(没看懂其实,以后再看)
3. 实验
Jeopardy Question Generation指标这里用了一个Q-BLEU,以前我还真没见过

还有一条是生成能获得原文中没有的结果
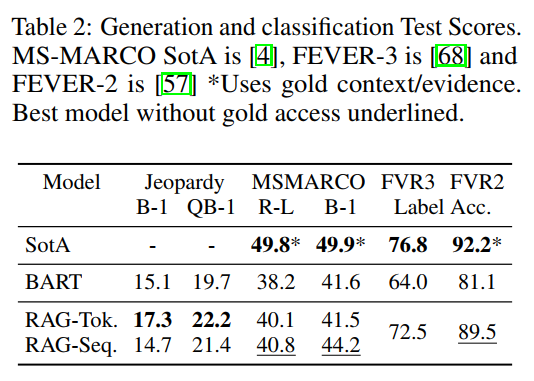
在生成方面还有一些别的优势,略。
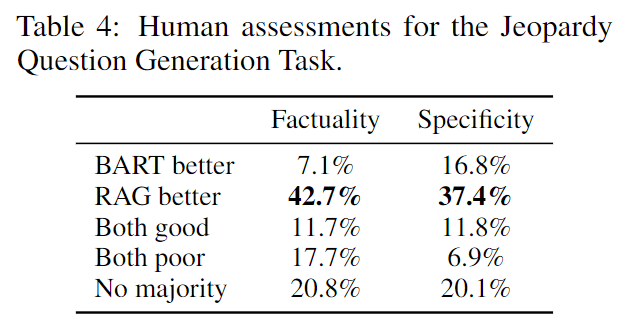

RAG-Token的后验概率可视化:

这里面这个太阳照常升起和永别了武器都是在开头概率高了点,后面就平了,论文里提及认为这里时因为模型内置信息能够自己填完了,还做了个小实验。
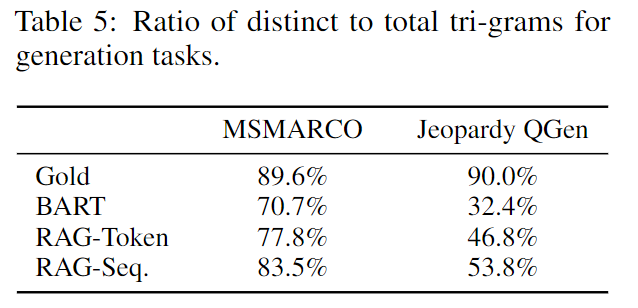
生成的多样性:
冻结检索器的消融实验:
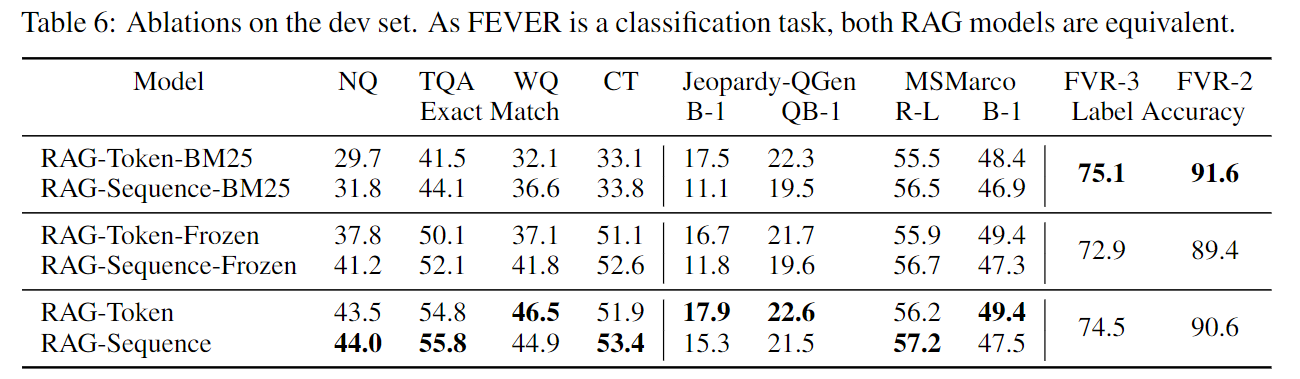
更新知识的实验
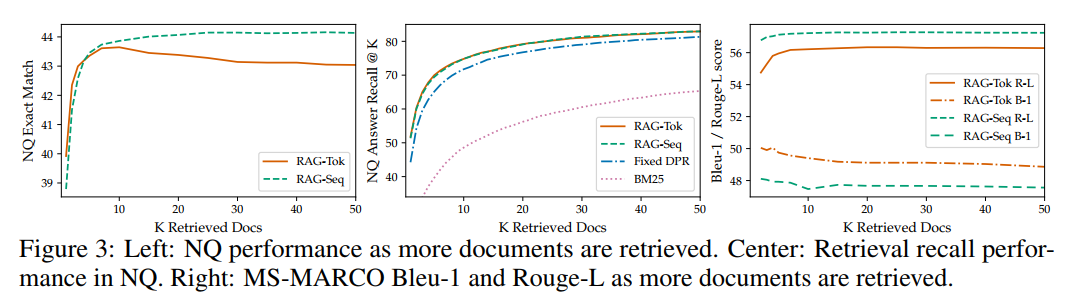
检索文档数(K)的影响:
这篇关于Re59:读论文 Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)