本文主要是介绍页面装饰技术—SiteMesh,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一,基本概念
1,Sitemesh是一种页面装饰技术 :
 1 :它通过过滤器(filter)来拦截页面访问 2 :根据被访问页面的URL找到合适的装饰模板 3 :提取被访问页面的内容,放到装饰模板中合适的位置 4 :最终将装饰后的页面发送给客户端。
1 :它通过过滤器(filter)来拦截页面访问 2 :根据被访问页面的URL找到合适的装饰模板 3 :提取被访问页面的内容,放到装饰模板中合适的位置 4 :最终将装饰后的页面发送给客户端。
2,在sitemesh中,页面分为两种:装饰模板和普通页面。
1)装饰模板,是指用于修饰其它页面的页面。
2)普通页面,一般指各种应用页面。
3,接下来,我们通过一个简单的例子来说明一下sitemesh修饰网页的基本原理。
1)装饰模板,是指用于修饰其它页面的页面。
2)普通页面,一般指各种应用页面。
3,接下来,我们通过一个简单的例子来说明一下sitemesh修饰网页的基本原理。
二,模板修饰网页的原理
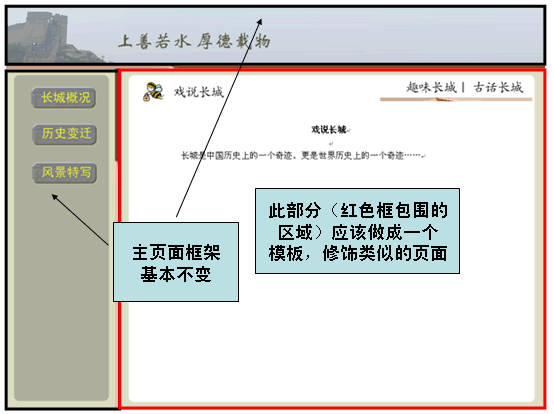
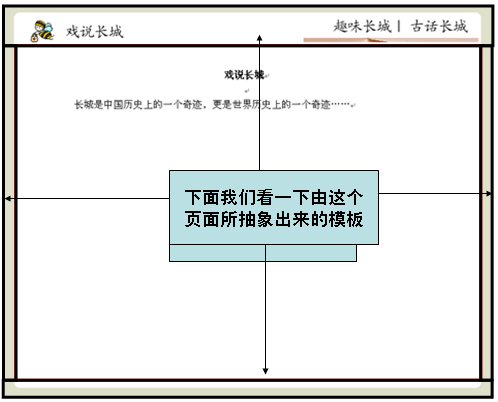
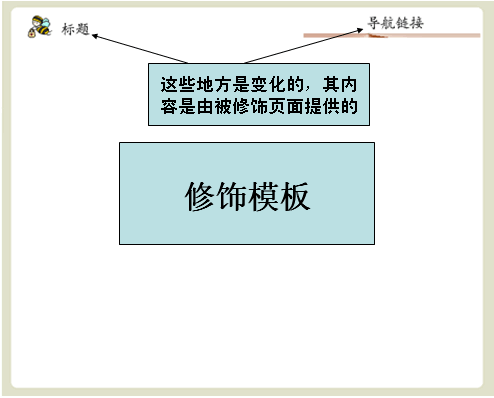
通过Sitemesh的注册机制,告诉Sitemesh,当访问该路径时使用XXX模板(假定使用前面那个模板)来修饰被访问页面。
通过Sitemesh的注册机制,告诉Sitemesh,当访问该路径时使用XXX模板(假定使用前面那个模板)来修饰被访问页面。
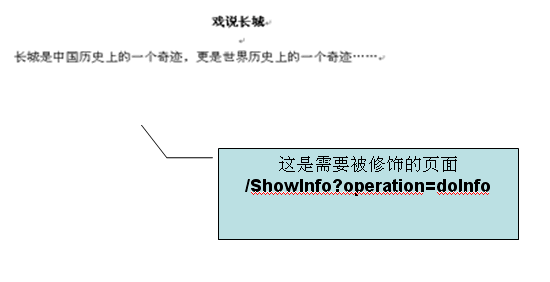
当用户在左边导航栏点击“戏说长城”( /ShowGreatWall.do)时,右边的“戏说长城”页面将会被指定的模板修饰
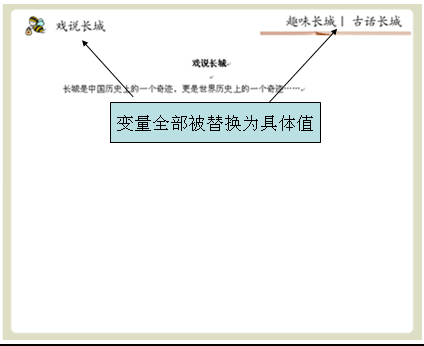
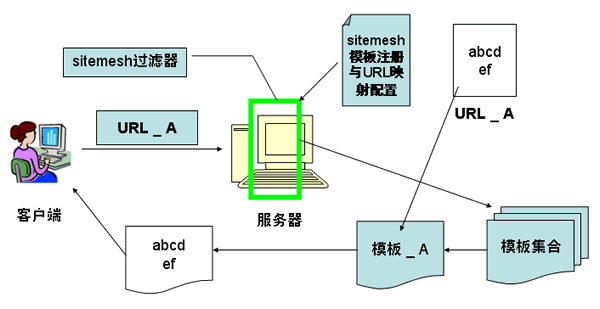
总结上面过程,Sitemesh修饰网页的基本原理,可以通过下面来说明:
三,Sitemesh的配置与使用
1)WEB-INF/web.xml中加入filter定义与sitemesh的taglib定义
< filter > < filter - name > sitemesh </ filter - name > < filter - class > com.opensymphony.module.sitemesh.filter.PageFilter </ filter - class > </ filter > < filter - mapping > < filter - name > sitemesh </ filter - name >  < url - pattern > /*</url-pattern>
< url - pattern > /*</url-pattern> </filter-mapping> <taglib> <taglib-uri>sitemesh-decorator</taglib-uri> <taglib-location>/WEB-INF/sitemesh-decorator.tld</taglib-location> </taglib> <taglib> <taglib-uri>sitemesh-page</taglib-uri> <taglib-location>/WEB-INF/sitemesh-page.tld</taglib-location> </taglib>
</filter-mapping> <taglib> <taglib-uri>sitemesh-decorator</taglib-uri> <taglib-location>/WEB-INF/sitemesh-decorator.tld</taglib-location> </taglib> <taglib> <taglib-uri>sitemesh-page</taglib-uri> <taglib-location>/WEB-INF/sitemesh-page.tld</taglib-location> </taglib>
2)创建WEB-INF/decorators.xml,在该文件中配置有哪些模板,以及每个模板具体修饰哪些URL,另外也可以配置哪些URL不需要模板控制 , decorators.xml的一个例子如下:
< excludes > < pattern > /Login* </ pattern > </ excludes > < decorators defaultdir ="/decorators" > < decorator name ="main" page =“DecoratorMainPage.jsp"> <pattern > /* </ pattern > </ decorator > < decorator name =“pop" page =“PopPage.jsp"> <pattern > /showinfo.jsp* </ pattern > < pattern > /myModule/GreatWallDetailAction.do* </ pattern > </ decorator > </ decorators >
3)我们看一个修饰模板的例子
< %@page contentType ="text/html;?charset=GBK" % > < %@taglib uri ="sitemesh-decorator" ?prefix ="decorator" % > < html > < head > < title > < decorator:title /> </ title > <decorator:head/> </ head > < body > Hello World < hr /> <decorator:body/> </ body > </ html >
4)我们看一个被修饰的页面的例子:
< %@ page contentType ="text/html;?charset=GBK" % > < html > < head > < title > Hello World </ title > </ head > < body > < p > Decorated page goes here. </ p </body > </ html >
5)我们看一下装饰模板中可以使用的Sitemesh标签
< decorator:head />
取出被装饰页面的head标签中的内容。
< decorator:body />
取出被装饰页面的body标签中的内容。
< decorator:title default =" " />
" />
取出被装饰页面的title标签中的内容。default为默认值
< decorator:getProperty property ="" default ="" writeEntireProperty ="" />
取出被装饰页面相关标签的属性值。
writeEntireProperty表明,是显示属性的值还是显示“属性=值”
Html标签的属性
Body标签的属性
Meta标签的属性
Body标签的属性
Meta标签的属性
注意如果其content值中包含“>或 < ”会报错,需转码,例如< ;等等
default是默认值
< decorator:usePage id ="" />
将被装饰页面构造为一个对象,可以在装饰页面的JSP中直接引用。
6)看一个在装饰模板中使用标签的例子
< html lang =“ <decorator:getProperty property =‘lang’/> ”> <head > < title > <decorator:title default=“你好” /> </ title > <decorator:head /> </ head > < body <decorator:getProperty property=“body.onload" writeEntireProperty =“1"/> > 从meta中获取变量company的名称: <decorator:getProperty property =“meta.company”/> 下面是被修饰页面的body中的内容: <decorator:body /> <decorator:usePage id=“myPage" /> <%=myPage.getRequest().getAttribute(“username”)%> </ body > </ html >
7)看一下相应的在被修饰页面中的代码:
< html lang =“en”> <head > < title > 我的sitemesh </ title > < meta name =“company” content =“smartdot”/> <meta name =“Author” content =“zhangsan”/> <script > function count(){return 10;} </ script > </ head > < body onload =“count()”> <p > 这是一个被修饰页面 </ p > </ body > </ html >
四,总结
1,Sitemesh最为重要的就是做用于修饰的模板,并在decorators.xml中配置这些模板用于修饰哪些页面。因此使用Sitemesh的主要过程就是: 做装饰模板,然后 在decorators.xml中配置URL Pattern
2,分析整个工程,看哪些页面需要抽象成模板,例如二级页面、三级页面、弹出窗口等等可能都需要做成相应的模板,一般来说,一个大型的OA系统,模板不会超过8个。
1,Sitemesh最为重要的就是做用于修饰的模板,并在decorators.xml中配置这些模板用于修饰哪些页面。因此使用Sitemesh的主要过程就是: 做装饰模板,然后 在decorators.xml中配置URL Pattern
2,分析整个工程,看哪些页面需要抽象成模板,例如二级页面、三级页面、弹出窗口等等可能都需要做成相应的模板,一般来说,一个大型的OA系统,模板不会超过8个。
— — —— — — — — — — — — — — — — — — — — — — — — —
如果某个特殊的需求请求路径在过滤器的范围内,但又不想使用模板怎么办?
你总不能这么不讲道理吧!
大家放心吧,SiteMesh早就考虑到这一点了,上面第5步说道的decorators.xml这个时候就起到作用了!
你总不能这么不讲道理吧!
大家放心吧,SiteMesh早就考虑到这一点了,上面第5步说道的decorators.xml这个时候就起到作用了!
下面是我的decorators.xml:
<? xml version ="1.0" encoding ="ISO-8859-1" ?>
< decorators defaultdir ="/decorators" >
<!-- Any urls that are excluded will never be decorated by Sitemesh -->
< excludes >
< pattern >/index.jsp* </ pattern >
< pattern >/login/* </ pattern >
</ excludes >
< decorator name ="main" page ="main.jsp" >
< pattern >/* </ pattern >
</ decorator >
</ decorators >
< decorators defaultdir ="/decorators" >
<!-- Any urls that are excluded will never be decorated by Sitemesh -->
< excludes >
< pattern >/index.jsp* </ pattern >
< pattern >/login/* </ pattern >
</ excludes >
< decorator name ="main" page ="main.jsp" >
< pattern >/* </ pattern >
</ decorator >
</ decorators >
decorators.xml有两个主要的结点:
decorator结点指定了模板的位置和文件名,通过pattern来指定哪些路径引用哪个模板
excludes结点则指定了哪些路径的请求不使用任何模板
decorator结点指定了模板的位置和文件名,通过pattern来指定哪些路径引用哪个模板
excludes结点则指定了哪些路径的请求不使用任何模板
如上面代码,/index.jsp和凡是以/login/开头的请求路径一律不使用模板;
另外还有一点要注意的是:decorators结点的defaultdir属性指定了模板文件存放的目录;
这篇关于页面装饰技术—SiteMesh的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




