本文主要是介绍【RocketMQ】Rebalance负载均衡机制详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、前言
二、RocketMQ消息消费
2.1、消息的流转过程
2.2、Consumer消费消息的流程
三、Rebalance负载均衡实现原理
3.1、概述
3.2、触发时机
3.3、执行流程
3.4、负载均衡策略原理
四、RocketMQ指定机器消费设计思路
参考
一、前言
在RocketMQ中,其中在消费者端,有一个重量级的组件:Rebalance负载均衡组件, 他负责相对均匀的给消费者分配需要拉取的队列信息。
我们此时可能会有以下问题:
-
一个Topic下可能会有很多逻辑队列,而消费者又有多个,这样不同的消费者到底消费哪个队列呢?
-
如果消费者或者队列扩缩容,Topic下的队列又该分配给谁呢?
这些时候负载均衡策略就有他的用武之地了。RocketMQ在处理上面的问题是统一处理的,也就是逻辑是一致的,它都是通过RebalanceService这个类来完成负载均衡的工作,看完本文我们就可以明白RocketMQ消费者负载均衡的核心逻辑。
二、RocketMQ消息消费
在进入Rebalance负载均衡组件学习前,咱们先来了解下RocketMQ整个的消息消费逻辑,有助于后续理解~
2.1、消息的流转过程
RocketMQ 支持两种消费模式:集群消费( Clustering )和广播消费( Broadcasting )。
集群消费:同一 Topic 下的一条消息只会被同一消费组中的一个消费者消费。也就是说,消息被负载均衡到了同一个消费组的多个消费者实例上。
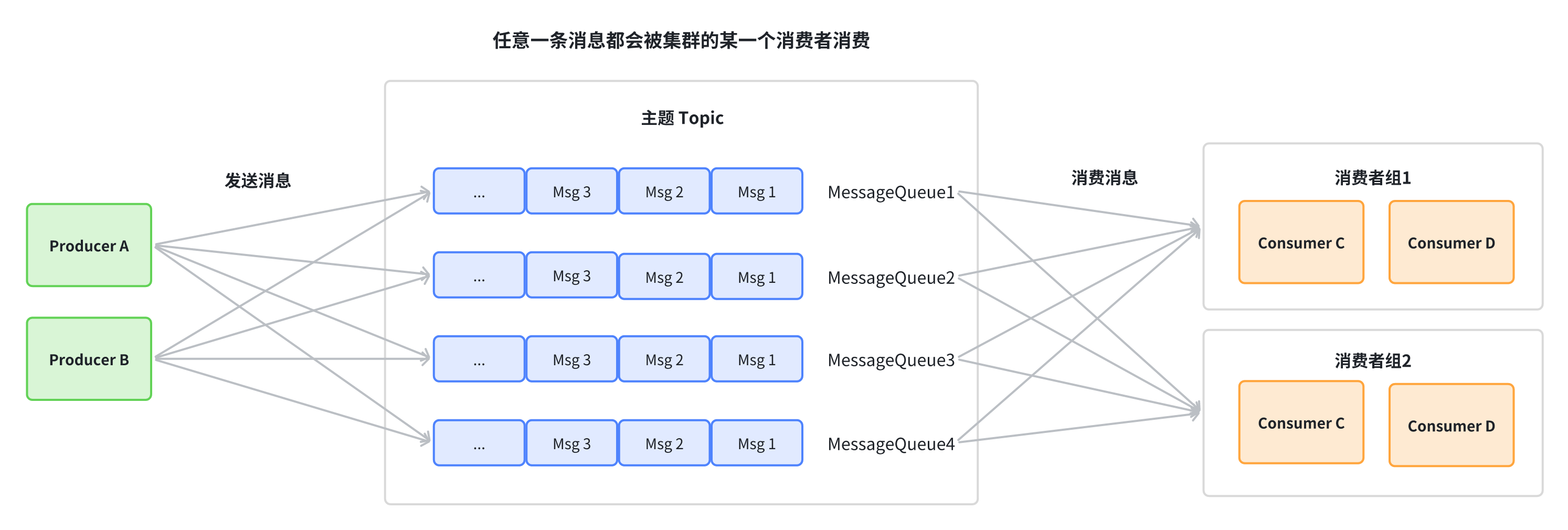
广播消费:当使用广播消费模式时,每条消息推送给集群内所有的消费者,保证消息至少被每个消费者消费一次。
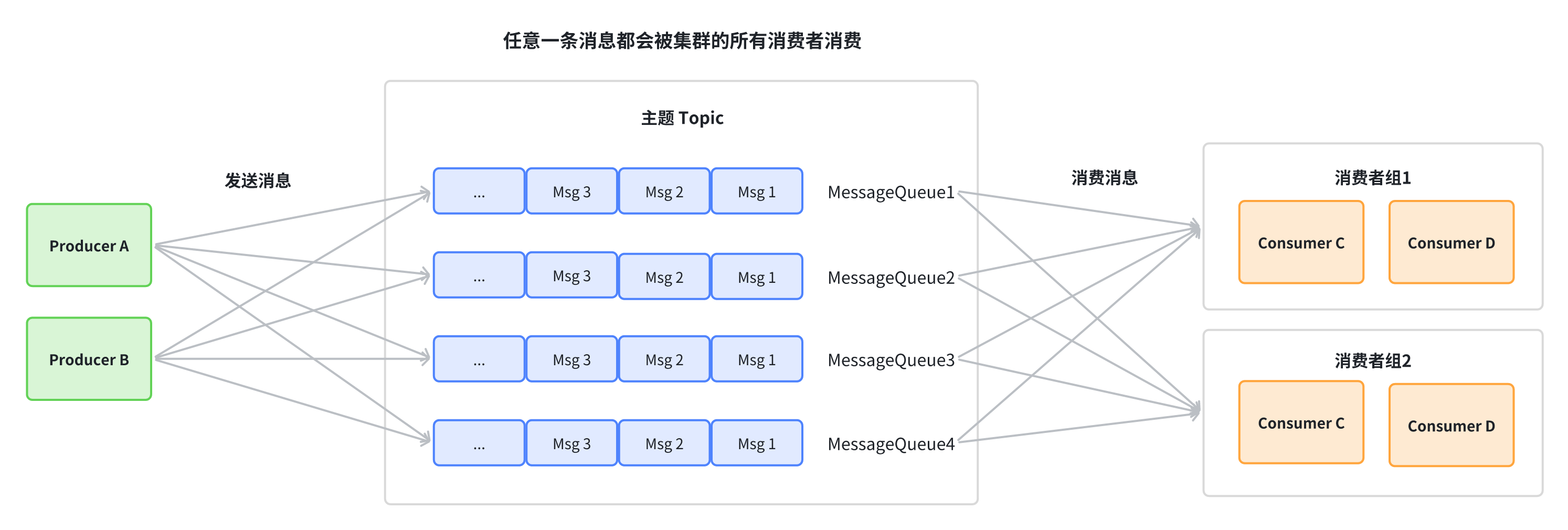
2.2、Consumer消费消息的流程

consumer消息消费过程:
-
consumer访问namesvr同步topic对应的路由信息。
-
consumer在本地解析远程路由信息并保存到本地。
-
consumer在本地进行Reblance负载均衡确定本节点负责消费的MessageQueue。
-
consumer访问Broker消费指定的MessageQueue的消息。
三、Rebalance负载均衡实现原理
3.1、概述
消费端的负载均衡是指将 Broker 端中多个队列按照某种算法分配给同一个消费组中的不同消费者。
RocketMQ 5.0以前是按照队列粒度进行负载均衡的,5.0以后提供了按消息粒度进行负载均衡。
对于4.x/3.x的版本,包括DefaultPushConsumer、DefaultPullConsumer、LitePullConsumer等,默认且仅能使用队列粒度负载均衡策略。
队列粒度负载均衡策略中,同一消费者组内的多个消费者将按照队列粒度消费消息,每个队列只能被其中一个消费者消费。
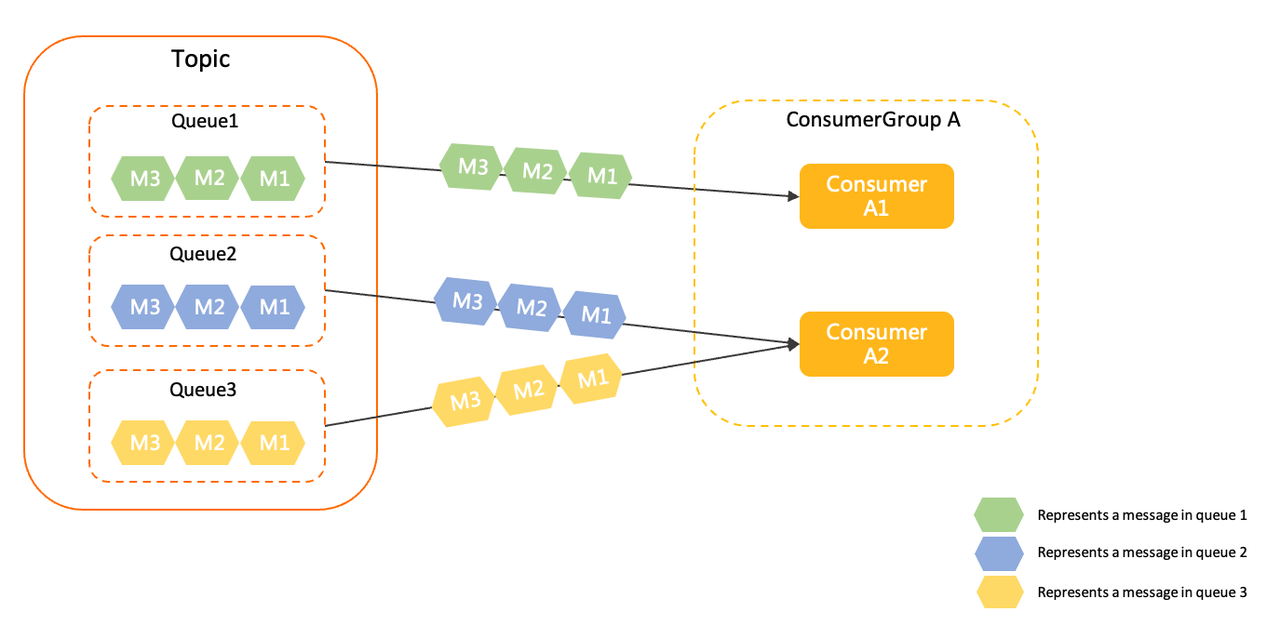
3.2、触发时机
消费端的负载均衡是指将 Broker 端中多个队列按照某种算法分配给同一个消费组中的不同消费者。
负载均衡是每个客户端独立进行计算,那么何时触发呢?
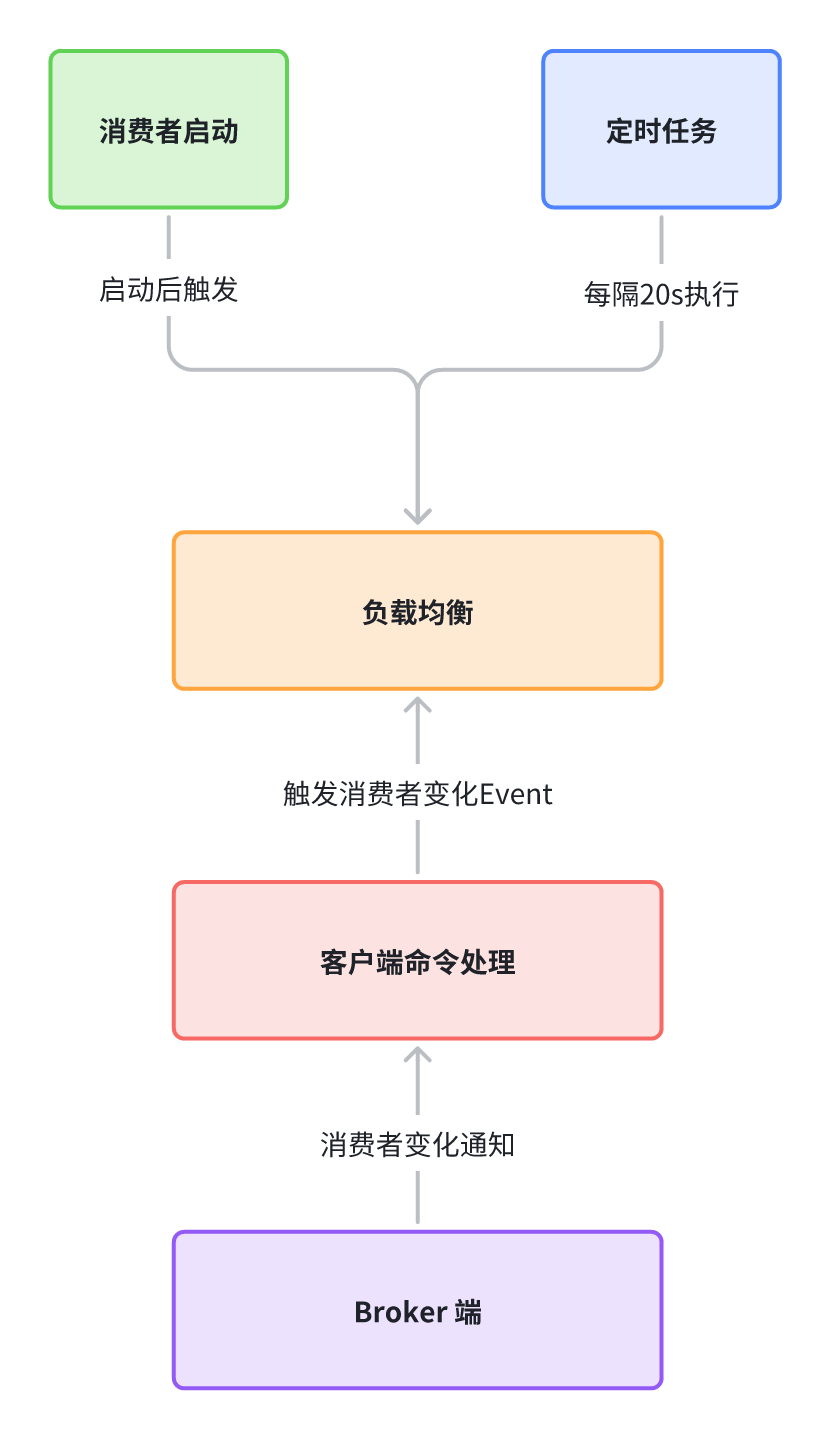
由上图可知,负载均衡机制主要由以下几点触发:
-
消费端启动时,立即进行负载均衡;
-
消费端定时任务每隔 20 秒触发负载均衡;
-
消费者上下线,Broker 端通知消费者触发负载均衡。
3.3、执行流程
负载均衡服务执行逻辑在doRebalance函数,里面会对每个消费者组执行负载均衡操作。 也就是一个负载均衡服务是对一个消费者组负责的,那么我们可以想到对不同的消费者组使用不同负载均衡策略。consumerTable这个map对象里存储了消费者组对应的的消费者实例。
private ConcurrentMap<String/* group */, MQConsumerInner> consumerTable = new ConcurrentHashMap<String, MQConsumerInner>();public void doRebalance() {//每个消费者组都有负载均衡for (Map.Entry<String, MQConsumerInner> entry : this.consumerTable.entrySet()) {MQConsumerInner impl = entry.getValue();if (impl != null) {try {impl.doRebalance();} catch (Throwable e) {log.error("doRebalance exception", e);}}}
}由于每个消费者组可能会消费很多topic,每个topic都有自己的不同队列,所以最终是按topic的维度进行负载均衡。
public void doRebalance(final boolean isOrder) {Map<String, SubscriptionData> subTable = this.getSubscriptionInner();if (subTable != null) {for (final Map.Entry<String, SubscriptionData> entry : subTable.entrySet()) {final String topic = entry.getKey();try {//按topic维度执行负载均衡this.rebalanceByTopic(topic, isOrder);} catch (Throwable e) {if (!topic.startsWith(MixAll.RETRY_GROUP_TOPIC_PREFIX)) {log.warn("rebalanceByTopic Exception", e);}}}}this.truncateMessageQueueNotMyTopic();
}最终负载均衡逻辑处理的实现在org.apache.rocketmq.client.impl.consumer.RebalanceImpl#rebalanceByTopic,其中分为广播消息和集群消息模型两种情况处理。由于广播消息是每个消费者实例都需要消费到,因此逻辑会简单点(不需要分配哪个队列给哪个消费者),我们主要关注集群消息模式。
private void rebalanceByTopic(final String topic, final boolean isOrder) {switch (messageModel) {//广播模型case BROADCASTING: {Set<MessageQueue> mqSet = this.topicSubscribeInfoTable.get(topic);if (mqSet != null) {boolean changed = this.updateProcessQueueTableInRebalance(topic, mqSet, isOrder);if (changed) {this.messageQueueChanged(topic, mqSet, mqSet);}}break;}//集群模型case CLUSTERING: {//查topic下的消息队列Set<MessageQueue> mqSet = this.topicSubscribeInfoTable.get(topic);//查询topic下的所有消费者List<String> cidAll = this.mQClientFactory.findConsumerIdList(topic, consumerGroup);if (null == mqSet) {if (!topic.startsWith(MixAll.RETRY_GROUP_TOPIC_PREFIX)) {log.warn("doRebalance, {}, but the topic[{}] not exist.", consumerGroup, topic);}}if (mqSet != null && cidAll != null) {List<MessageQueue> mqAll = new ArrayList<MessageQueue>();mqAll.addAll(mqSet);Collections.sort(mqAll);Collections.sort(cidAll);//负载均衡组件AllocateMessageQueueStrategy strategy = this.allocateMessageQueueStrategy;//负载均衡结果List<MessageQueue> allocateResult = strategy.allocate(this.consumerGroup,this.mQClientFactory.getClientId(),mqAll,cidAll);Set<MessageQueue> allocateResultSet = new HashSet<MessageQueue>();if (allocateResult != null) {allocateResultSet.addAll(allocateResult);}//负载均衡执行结束后,判断是否有新的消费策略变化,更新拉取策略boolean changed = this.updateProcessQueueTableInRebalance(topic, allocateResultSet, isOrder);if (changed) {//发送更新通知this.messageQueueChanged(topic, mqSet, allocateResultSet);}}break;}default:break;}}代码逻辑可以看出负载均衡核心功能的主流程,主要做了4件事情:

其中比较重要的是具体的负载均衡策略,关系着哪些队列是当前消费者需要消费的。下面我们看下负载均衡策略的具体实现。
3.4、负载均衡策略原理
看负载均衡策略的具体实现前,我们看下RocketMQ中的负载均衡策略顶层接口
/*** Strategy Algorithm for message allocating between consumers*/
public interface AllocateMessageQueueStrategy {/*** Allocating by consumer id* 给消费者id分配消费队列*/List<MessageQueue> allocate(final String consumerGroup, //消费者组final String currentCID, //当前消费者idfinal List<MessageQueue> mqAll, //所有的队列final List<String> cidAll //所有的消费者);}他默认共有7种负载均衡策略实现。
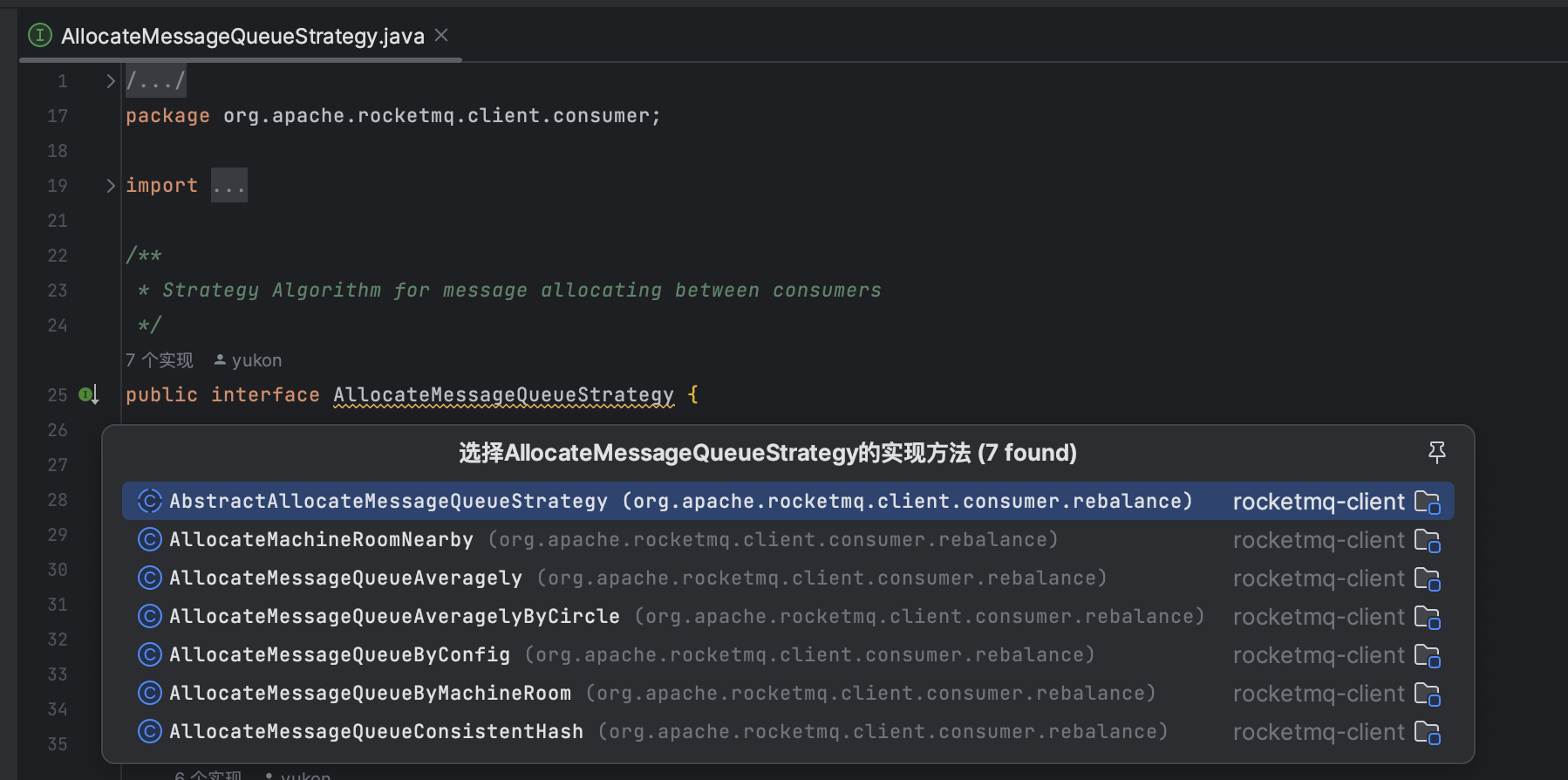
其中最常用的两种平均分配算法。
-
AllocateMessageQueueAveragely 平均分配
-
AllocateMessageQueueAveragelyByCircle 轮流平均分配
为了说明这两种分配算法的分配规则,现在对16 个队列,进行编号,用 q0-q15 表示, 消费者用 c0~c2 表示。
AllocateMessageQueueAveragely 分配算法的队列负载机制如下:
c0: q0 q1 q2 q3 q4 q5
c1: q6 q7 q8 q9 q10
c2: q11 q12 q13 q14 q15
其算法的特点是用总数除以消费者个数,余数按消费者顺序分配给消费者,故 c0 会多分配一个队列,而且队列分配是连续的.
AlocateMessageQueueAveragelyByCircle 分配算法的队列负载机制如下:
c0: q0 q3 q6 q9 q12 q15
c1: q1 q4 q7 q10 q13
c2: q2 q5 q8 q11 q14
该分配算法的特点就是轮流一个一个分配。
温馨提示:如果 topic 的队列个数小于消费者的个数,那有些消费者无法分配到消息。 在RocketMQ 中一个 topic 的队列数直接决定了最大消费者的个数,但 topic 队列个数的增加对 RocketMQ 的性能不会产生影响。
在实际过程中,对主题进行扩容(增加队列个数)或者对消费者进行扩容、缩容是一件非常寻常的事情,那如果新增一个消费者,该消费者消费哪些队列呢?这就涉及到消息消费队列的重新分配,即消费队列重平衡机制。
在RocketMQ 客户端中会每隔 20s 去查询当前 topic 的所有队列、消费者的个数,运用队列负载算法进行重新分配,然后与上一次的分配结果进行对比,如果发生了变化,则进行队列重新分配;如果没有发生变化,则忽略。
队列分配好之后,会更新到本地注册表,这时候就是当前消费者最新需要消费的队列。
更新本地注册表后,主要是移除老的拉取消息任务,新增新的拉取消息任务。
四、RocketMQ指定机器消费设计思路
日常测试环境当中会存在多台consumer进行消费,但实际开发当中某台consumer新上了功能后希望消息只由该机器进行消费进行逻辑覆盖,这个时候consumerGroup的集群模式就会给我们造成困扰,因为消费负载均衡的原因不确定消息具体由那台consumer进行消费。当然我们可以通过介入consumer的负载均衡机制来实现指定机器消费。
public class AllocateMessageQueueAveragely implements AllocateMessageQueueStrategy {private final InternalLogger log = ClientLogger.getLog();@Overridepublic List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,List<String> cidAll) {List<MessageQueue> result = new ArrayList<MessageQueue>();// 通过改写这部分逻辑,增加判断是否是指定IP的机器,如果不是直接返回空列表表示该机器不负责消费if (!cidAll.contains(currentCID)) {return result;}int index = cidAll.indexOf(currentCID);int mod = mqAll.size() % cidAll.size();int averageSize =mqAll.size() <= cidAll.size() ? 1 : (mod > 0 && index < mod ? mqAll.size() / cidAll.size()+ 1 : mqAll.size() / cidAll.size());int startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod;int range = Math.min(averageSize, mqAll.size() - startIndex);for (int i = 0; i < range; i++) {result.add(mqAll.get((startIndex + i) % mqAll.size()));}return result;}
}consumer负载均衡策略改写:
-
通过改写负载均衡策略AllocateMessageQueueAveragely的allocate机制保证只有指定IP的机器能够进行消费。
-
通过IP进行判断是基于RocketMQ的cid格式是192.168.0.6@15956,其中前面的IP地址就是对于的消费机器的ip地址,整个方案可行且可以实际落地。
参考
-
vivo互联网技术|深入剖析 RocketMQ 源码 - 负载均衡机制
-
万字长文讲透 RocketMQ 的消费逻辑
-
RocketMQ消费者负载均衡内核是这样设计的
-
【RocketMQ】【源码】负载均衡源码分析
这篇关于【RocketMQ】Rebalance负载均衡机制详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





