本文主要是介绍[Hadoop]MapReducer工作过程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 从输入到输出
一个MapReducer作业经过了input,map,combine,reduce,output五个阶段,其中combine阶段并不一定发生,map输出的中间结果被分到reduce的过程成为shuffle(数据清洗)。

在shuffle阶段还会发生copy(复制)和sort(排序)。
在MapReduce的过程中,一个作业被分成Map和Reducer两个计算阶段,它们由一个或者多个Map任务和Reduce任务组成。如下图所示,一个MapReduce作业从数据的流向可以分为Map任务和Reduce任务。当用户向Hadoop提交一个MapReduce作业时,JobTracker则会根据各个TaskTracker周期性发送过来的心跳信息综合考虑TaskTracker的资源剩余量,作业优先级,作业提交时间等因素,为TaskTracker分配合适的任务。Reduce任务默认会在Map任务数量完成5%后才开始启动。

Map任务的执行过程可以概括为:首先通过用户指定的InputFormat类中的getSplits方法和next方法将输入文件切片并解析成键值对作为map函数的输入。然后map函数经过处理之后将中间结果交给指定的Partitioner处理,确保中间结果分发到指定的Reduce任务处理,此时如果用户指定了Combiner,将执行combine操作。最后map函数将中间结果保存到本地。
Reduce任务的执行过程可以概括为:首先需要将已经完成Map任务的中间结果复制到Reduce任务所在的节点,待数据复制完成后,再以key进行排序,通过排序,将所有key相同的数据交给reduce函数处理,处理完成后,结果直接输出到HDFS上。
2. input
如果使用HDFS上的文件作为MapReduce的输入,MapReduce计算框架首先会用org.apache.hadoop.mapreduce.InputFomat类的子类FileInputFormat类将作为输入HDFS上的文件切分形成输入分片(InputSplit),每个InputSplit将作为一个Map任务的输入,再将InputSplit解析为键值对。InputSplit的大小和数量对于MaoReduce作业的性能有非常大的影响。
InputSplit只是逻辑上对输入数据进行分片,并不会将文件在磁盘上分成分片进行存储。InputSplit只是记录了分片的元数据节点信息,例如起始位置,长度以及所在的节点列表等。数据切分的算法需要确定InputSplit的个数,对于HDFS上的文件,FileInputFormat类使用computeSplitSize方法计算出InputSplit的大小,代码如下:
protected long computeSplitSize(long blockSize, long minSize, long maxSize) {return Math.max(minSize, Math.min(maxSize, blockSize));}
其中 minSize 由mapred-site.xml文件中的配置项mapred.min.split.size决定,默认为1;maxSize 由mapred-site.xml文件中的配置项mapred.max.split.size决定,默认为9223 372 036 854 775 807;而blockSize是由hdfs-site.xml文件中的配置项dfs.block.size决定,默认为67 108 864字节(64M)。所以InputSplit的大小确定公式为:
max(mapred.min.split.size, min(mapred.max.split.size, dfs.block.size));
一般来说,dfs.block.size的大小是确定不变的,所以得到目标InputSplit大小,只需改变mapred.min.split.size 和 mapred.max.split.size 的大小即可。InputSplit的数量为文件大小除以InputSplitSize。InputSplit的原数据信息会通过一下代码取得:
splits.add(new FileSplit(path, length - bytesRemaining, splitSize, blkLocations[blkIndex].getHosts()));
从上面的代码可以发现,元数据的信息由四部分组成:文件路径,文件开始位置,文件结束位置,数据块所在的host。
对于Map任务来说,处理的单位为一个InputSplit。而InputSplit是一个逻辑概念,InputSplit所包含的数据是仍然存储在HDFS的块里面,它们之间的关系如下图所示:
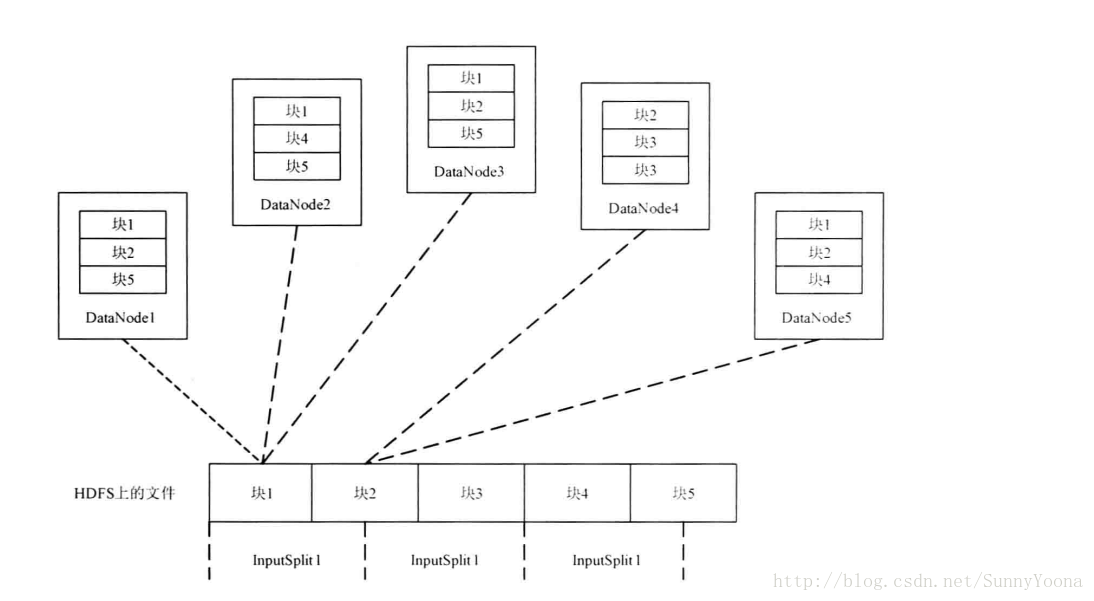
当输入文件切分为InputSplit后,由FileInputFormat的子类(如TextInputFormat)的createRecordReader方法将InputSplit解析为键值对,代码如下:
public RecordReader<LongWritable, Text>createRecordReader(InputSplit split,TaskAttemptContext context) {String delimiter = context.getConfiguration().get("textinputformat.record.delimiter");byte[] recordDelimiterBytes = null;if (null != delimiter)recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);return new LineRecordReader(recordDelimiterBytes);}
此处默认是将行号作为键。解析出来的键值对将被用来作为map函数的输入。至此input阶段结束。
3. map及中间结果的输出
InputSplit将解析好的键值对交给用户编写的map函数处理,处理后的中间结果会写到本地磁盘上,在刷写磁盘的过程中,还做了partition(分区)和 sort(排序)的操作。
map函数产生输出时,并不是简单的刷写磁盘。为了保证I/O效率,采取了先写到内存的环形内存缓冲区,并做一次预排序,如下图所示:
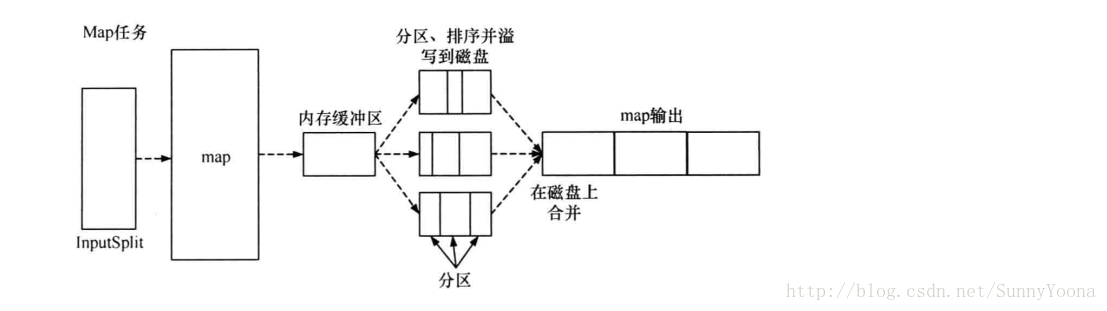
每个Map任务都有一个环形内存缓冲区,用于存储map函数的输出。默认情况下,缓冲区大小是100M,该值可以通过mapred-site.xml文件中的io.sort.mb的配置项配置。一旦缓冲区内容达到阈值(由mapred-site.xml文件的io.sort.spill.percent的值决定,默认为0.80 或者 80%),一个后台线程便会将缓冲区的内容溢写到磁盘中。再写磁盘的过程中,map函数的输出继续被写到缓冲区,但如果在此期间缓冲区被填满,map会阻塞直到写磁盘过程完成。写磁盘会以轮询的方式写到mapred.local.dir(mapred-site.xml文件的配置项)配置的作业特定目录下。
在写磁盘之前,线程会根据数据最终要传入到的Reducer把缓冲区的数据划分成(默认是按照键)相应的分区。在每个分区中,后台线程按照建进行内排序,此时如果有一个Combiner,它会在排序后的输出上运行。
一旦内存缓冲区达到溢出的阈值,就会新建一个溢出写文件,因此在Map任务完成最后一个输出记录之后,会有若干个溢出写文件。在Map任务完成之前,溢出写文件被合并成一个已分区且已排序的输出文件作为map输出的中间结果,这也是Map任务的输出结果。
如果已经指定Combiner且溢出写次数至少为3时,Combiner就会在输出文件写到磁盘之前运行。如前文所述,Combiner可以多次运行,并不影响输出结果。运行Combiner的意义在于使map输出的中间结果更紧凑,使得写到本地磁盘和传给Reducer的数据更少。
为了提高磁盘IO性能,可以考虑压缩map的输出,这样会写磁盘的速度更快,节约磁盘空间,从而使传送给Reducer的数据量减少。默认情况下,map的输出是不压缩的,但只要将mapred-site.xml文件的配置项mapred.compress.map.output设为true即可开启压缩功能。使用的压缩库由mapred-site.xml文件的配置项mapred.map.output.compression.codec
指定,如下列出了目前hadoop支持的压缩格式:
| 压缩格式 | 工具 | 算法 | 文件扩展名 | 是否包含多个文件 | 是否可切分 |
|---|---|---|---|---|---|
| DEFLATE* | N/A | DEFLATE | .deflate | 否 | 否 |
| Gzip | gzip | DEFLATE | .gz | 否 | 否 |
| bzip2 | bzip2 | bzip2 | .bz2 | 否 | 是 |
| LZO | Lzop | LZO | .lzo | 否 | 否 |
map输出的中间结果存储的格式为IFile,IFile是一种支持航压缩的存储格式,支持上述压缩算法。
Reducer通过Http方式得到输出文件的分区。将map输出的中间结果发送到Reducer的工作线程的数量由mapred-site.xml文件的tasktracker.http.threds配置项决定,此配置针对每个节点,而不是每个Map任务,默认是40,可以根据作业大小,集群规模以及节点的计算能力而增大。
4. shuffle
shuffle,也叫数据清洗。在某些语境下,代表map函数产生输出到reduce的消化输入的整个过程。
4.1 copy阶段
Map任务输出的结果位于Map任务的TaskTracker所在的节点的本地磁盘上。TaskTracker需要为这些分区文件(map输出)运行Reduce任务。但是,Reduce任务可能需要多个Map任务的输出作为其特殊的分区文件。每个Map任务的完成时间可能不同,当只要有一个任务完成,Reduce任务就开始复制其输出。这就是shuffle的copy阶段。如下图所示,Reduce任务有少量复制线程,可以并行取得Map任务的输出,默认值为5个线程,该值可以通过设置mapred-site.xml的mapred.reduce.parallel.copies的配置项来改变。
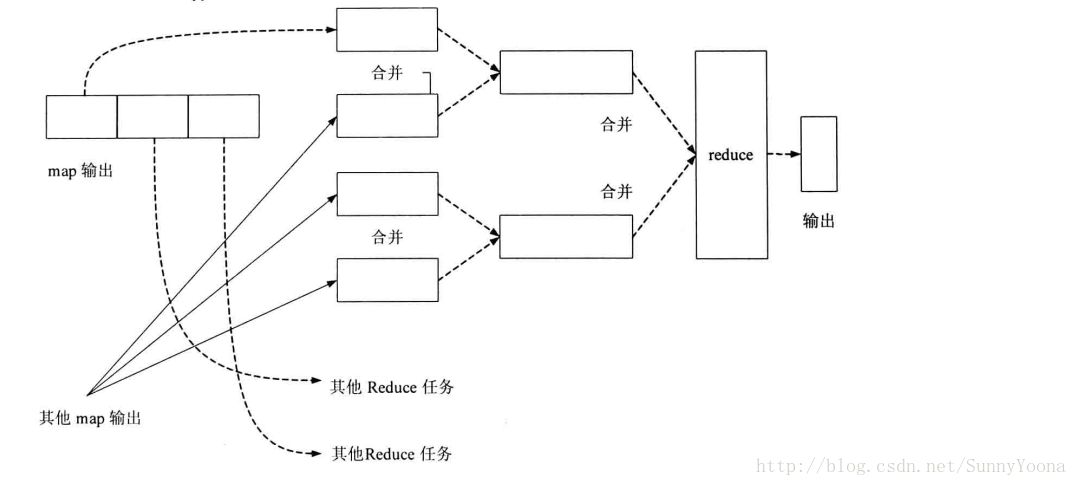
如果map输出相当小,则会被复制到Reduce所在TaskTracker的内存的缓冲区中,缓冲区的大小由mapred-site.xml文件中的mapred.job.shuffle.input.buffer.percent配置项指定。否则,map输出将会被复制到磁盘。一旦内存缓冲区达到阈值大小(由mapred-site.xml文件mapred.job.shuffle.merge.percent配置项决定)或缓冲区的文件数达到阈值大小(由mapred-site.xml文件mapred.inmem.merge.threshold配置项决定),则合并后溢写到磁盘中。
4.2 sort阶段
随着溢写到磁盘的文件增多,shuffle进行sort阶段。这个阶段将合并map的输出文件,并维持其顺序排序,其实做的是归并排序。排序的过程是循环进行,如果有50个map的输出文件,而合并因子(由mapred-site.xml文件的io.sort.factor配置项决定,默认为10)为10,合并操作将进行5次,每次将10个文件合并成一个文件,最后有5个文件,这5个文件由于不满足合并条件(文件数小于合并因子),则不会进行合并,将会直接把5个文件交给Reduce函数处理。到此shuffle阶段完成。
从shuffle的过程可以看出,Map任务处理的是一个InputSplit,而Reduce任务处理的是所有Map任务同一个分区的中间结果。
5. reduce及最后结果的输出
reduce阶段操作的实质就是对经过shuffle处理后的文件调用reduce函数处理。由于经过了shuffle的处理,文件都是按键分区且有序,对相同分区的文件调用一次reduce函数处理。
与map的中间结果不同的是,reduce的输出一般为HDFS。
6. sort
排序贯穿于Map任务和Reduce任务,排序操作属于MapReduce计算框架的默认行为,不管流程是否需要,都会进行排序。在MapReduce计算框架中,主要用到了两种排序算法:快速排序和归并排序。
在Map任务和Reduce任务的过程中,一共发生了3次排序操作。
(1)当map函数产生输出时,会首先写入内存的环形缓冲区,当达到设定的阈值,在刷写磁盘之前,后台线程会将缓冲区的数据划分相应的分区。在每个分区中,后台线程按键进行内排序。如下图所示。
(2)在Map任务完成之前,磁盘上存在多个已经分好区,并排好序,大小和缓冲区一样的溢写文件,这时溢写文件将被合并成一个已分区且已排序的输出文件。由于溢写文件已经经过一次排序,所以合并文件时只需再做一次排序就可使输出文件整体有序。如下图所示。
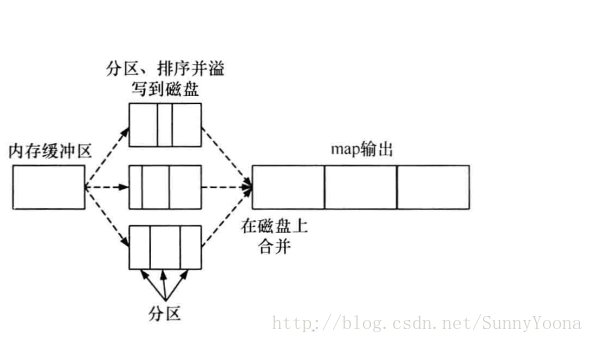
(3)在shuffle阶段,需要将多个Map任务的输出文件合并,由于经过第二次排序,所以合并文件时只需在做一次排序就可以使输出文件整体有序。
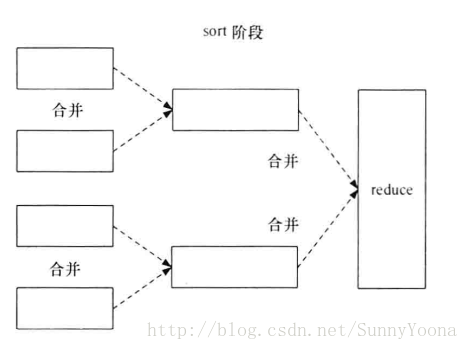
在这3次排序中第一次是在内存缓冲区做的内排序,使用的算法是快速排序;第二次排序和第三次排序都是在文件合并阶段发生的,使用的是归并排序。
7. 作业的进度组成
一个MapReduce作业在Hadoop上运行时,客户端的屏幕通常会打印作业日志,如下:
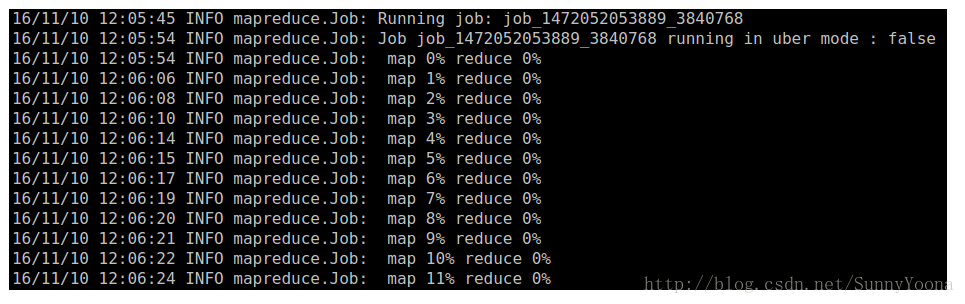
对于一个大型的MapReduce作业来说,执行时间可能会比较比较长,通过日志了解作业的运行状态和作业进度是非常重要的。对于Map来说,进度代表实际处理输入所占比例,例如 map 60% reduce 0% 表示Map任务已经处理了作业输入文件的60%,而Reduce任务还没有开始。而对于Reduce的进度来说,情况比较复杂,从前面得知,reduce阶段分为copy,sort 和 reduce,这三个步骤共同组成了reduce的进度,各占1/3。如果reduce已经处理了2/3的输入,那么整个reduce的进度应该为1/3 + 1/3 + 1/3 * (2/3) = 5/9 ,因为reduce开始处理时,copy和sort已经完成。
这篇关于[Hadoop]MapReducer工作过程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







