本文主要是介绍Git使用基础---git init 与git init --bare的区别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在使用git的过程中,遇到很多疑问的地方,经过一段血泪史之后,才慢慢填平遇到的坑。作为git小白,总结一下分享给也同样处在迷惑中的你!(大佬们请移步吧,后面的故事都so easy)
文章目录
- 1.网上查到的解释:
- 2.git init --bare 的特点
- 3.git init 的特点
- 4.git init容易产生冲突的地方
- 5.以git init为例的后续操作
- 1.先提交部分内容,跟踪这些文件
- 2.新建一个分支(避免git init 分支冲突)
- 3.本地先git pull 最新代码,再修改提交git push代码
1.网上查到的解释:
- git init 创建的工作仓库(working repository)适合于实际编辑生产过程中,在工作目录下,你将可以进行实际的编码、文件管理操作和保存项目在本地工作。如果你开始创建一个项目将包含有源代码和和版本跟踪记录的时候你可以使用”git init”.或者,如果你克隆”git clone”一个已经存在的版本库的时候,你也可以得到一个working repository,它也将包含”.git”目录和源文件的拷贝。(也就是说,在远程仓库上代码,是否需要编辑和执行,如果需要执行,就使用git init)
- git init --bare创建的裸仓库(bare repository)主要是用作分享版本库。开发者使用bare repository可以向其他人分享存储在本地的版本库,以便于实时分享代码更新和团队协作 。通过使用”git push”命令,你可以将你的本地更新提交至“中心版本库”(其他开发者可访问的中心库)。其他开发者可以使用“git pull”命令者接受你提交的版本更新。如果你正在一个多人协作的项目团队或者同一个项目需要在不同电脑上面完成的时候,bare repository可以满足你的分布式开发需求。(也就是说,大家都把内容分享到中心仓库,然后每个人都可以获取其他人的修改信息的过程,但中心仓库没有代码文件)
2.git init --bare 的特点
- 使用命令"git init --bare"(bare汉语意思是:裸,裸的)初始化的版本库(暂且称为bare repository),会生成多个记录版本信息的文件。
- 这种方式,不会包含实际项目源文件的拷贝,所以该版本库不能称为工作目录(working tree);
初始化的目录下面:

3.git init 的特点
git init 的特点
- 会生成一个.git(隐藏文件夹),在这个文件夹里面有多个版本历史记录文件。
- 使用–bare选项时,不再生成.git目录,而是只生成.git目录下面的版本历史记录文件。这些版本历史记录文件也不再存放在.git目录下面,而是直接存放在版本库的根目录下面
初始化的目录下面:(.git文件夹下面,就是不同版本历史记录文件)

4.git init容易产生冲突的地方
git init 容易产生冲突的地方
- 因为远端仓库的用户正在master的分支上操作,而你又要把更新提交到这个master分支上,当然就出错了。
- 但如果是往远端仓库中空闲的分支上提交还是可以的,比如git push origin master:b1 还是可以成功的。
https://www.cnblogs.com/langren1992/p/10161538.html
通过如上的解释,我们基本清楚了git init --bare是不包含工作目录的(代码源文件目录),git init是包含工作目录的(代码源文件目录)。如果使用git init,不能向工作中的分支上提交信息,否则会产生冲突。嗯,感觉看明白了,挺容易理解的嘛。但是,后续很快就遇到问题了
遇到问题的过程-1(可忽略):
后续我在服务器上使用git init初始化的仓库地址,在本地也能拉取下来,但是本地仓库再修改一下,然后再提交(修改本地文件—git add xxx文件----git commit -m “xxx信息”-----git push -u origin master)。最终发现,服务器上的文件根本就没有更新。考虑到如上可能产生冲突了,我再次把服务器上终端输入框关闭了,这样服务器上的master分支就肯定没有在工作了,但是最终结果还是一样。每次在服务器上使用git log可以查看到本地提交的信息commit简介,但是代码文件就是没更新。
遇到问题的过程-2(可忽略):
最初以为,本地分支和服务器分支,是不是不一致呀。通过git branch校验发现,本地和服务器都是master分支(这个因素排除了)
以上内容中,有关git init容易产生冲突的理解其实是错误的,请看:
先说结论:
如果使用了git init初始化,则远程仓库的目录下,也包含work tree,当本地仓库向远程仓库push时, 如果远程仓库正在push的分支上(如果当时不在push的分支,就没有问题), 那么push后的结果不会反应在work tree上, 即在远程仓库的目录下对应的文件还是之前的内容,必须得使用git reset --hard 回退到此时HAED知道的位置才能看到push后的内容.
https://blog.csdn.net/wzg_inspur/article/details/82255493
后续,我在服务器上新建了一个分支,然后把服务器上的分支切换到新的分支上(git checkout newbranch),然后在本地的master分支上,向服务器的master分支上push内容的话,修改之后的代码文件就立马在服务器仓库上显示出来了。
如果服务器仓库在master分支上,且在本地master分支刚好向服务器master分支上push了。就使用git reset --hard 版本号(前6位或完整版本号都行)
git log命令

commit 后面一串16进制的字符,就是这个版本号
git reset --hard fa770f 这个即可回退到当前版本,本地代码文件即可更新过来
5.以git init为例的后续操作
1.先提交部分内容,跟踪这些文件
初试化git仓库之后,如果我们操作 git branch(查看目前所处的分支),发现啥也没有,新建一个分支也不行,显示效果如下:

虽然上图没有显示master,但使用git bash就能显示出master分支标识。只是git branch只有在存在commit记录的时候才会显示master分支。

此处感谢【XW-YYDS】大佬的提示,git init就有了master分支
上新建一个文件,添加一点内容,然后提交到临时仓库
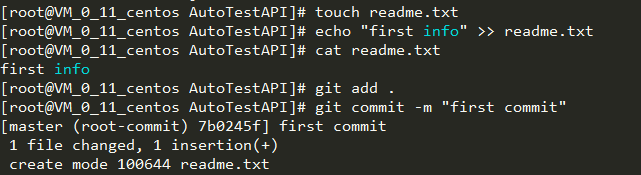

2.新建一个分支(避免git init 分支冲突)
# 新建一个分支,暂定叫做newbranch
git branch newbranch# 切换到新分支上去
git checkout newbranch
3.本地先git pull 最新代码,再修改提交git push代码
# 如果本地没有任何代码,可以先拉去远程仓库的最新代码
git pull origin master:master # 拉去远程仓库master分支到本地master分支
# 如果本地仓库已经有代码,可以执行拉去最新的代码git pull origin master --allow-unrelated-histories # ( 把两段不相干的 分支进行强行合并)最终可以修改部分代码,然后git push即可
修改部分代码,并保存git add .git commit -m '提交说明'# 将本地master分支的信息,提交到远程master分支
git push -u origin master:master这篇关于Git使用基础---git init 与git init --bare的区别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




