本文主要是介绍自然语言处理NLP星空智能对话机器人系列:深入理解Transformer自然语言处理 位置编码(positional_encoding),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
自然语言处理NLP星空智能对话机器人系列:深入理解Transformer自然语言处理 位置编码(positional_encoding)
目录
- NLTK自然语言工具包
- NLTK数据集
- 位置编码(Positional encoding)
- Adding positional encoding to the embedding vector
- 星空智能对话机器人系列博客
NLTK自然语言工具包
NLTK是构建Python程序以处理人类语言数据的领先平台。它为50多个语料库和词汇资源(如WordNet)提供了易于使用的界面,以及一套用于分类、标记、词干、标记、解析和语义推理的文本处理库、工业级NLP库包装器和一个活跃的讨论论坛。NLTK适合语言学家、工程师、学生、教育工作者、研究人员和行业用户。NLTK可用于Windows、Mac OS X和Linux。最重要的是,NLTK是一个免费、开源、社区驱动的项目。NLTK被称为“使用Python进行计算语言学教学和工作的最佳工具”,以及“使用自然语言的最佳库”
Python的自然语言处理提供了语言处理编程的实用介绍。由NLTK的创作者编写,它指导读者完成编写Python程序、使用语料库、对文本进行分类、分析语言结构等基础知识。该书的在线版本已经针对Python 3和NLTK 3进行了更新。(Python2的原始版本在http://nltk.org/book_1ed.)

Natural Language Processing with Python
— Analyzing Text with the Natural Language Toolkit
Steven Bird, Ewan Klein, and Edward Loper
NLTK数据集
本文案例需使用nltk_data数据集,nltk_data数据集可以通过以下几种方式下载:
- 从nltk官网直接下载
- 通过nltk下载工具进行下载
- 从网盘下载nltk数据集
方法一:从nltk官网直接下载:登录nltk官网,单击到数据下载链接
http://www.nltk.org/data.html
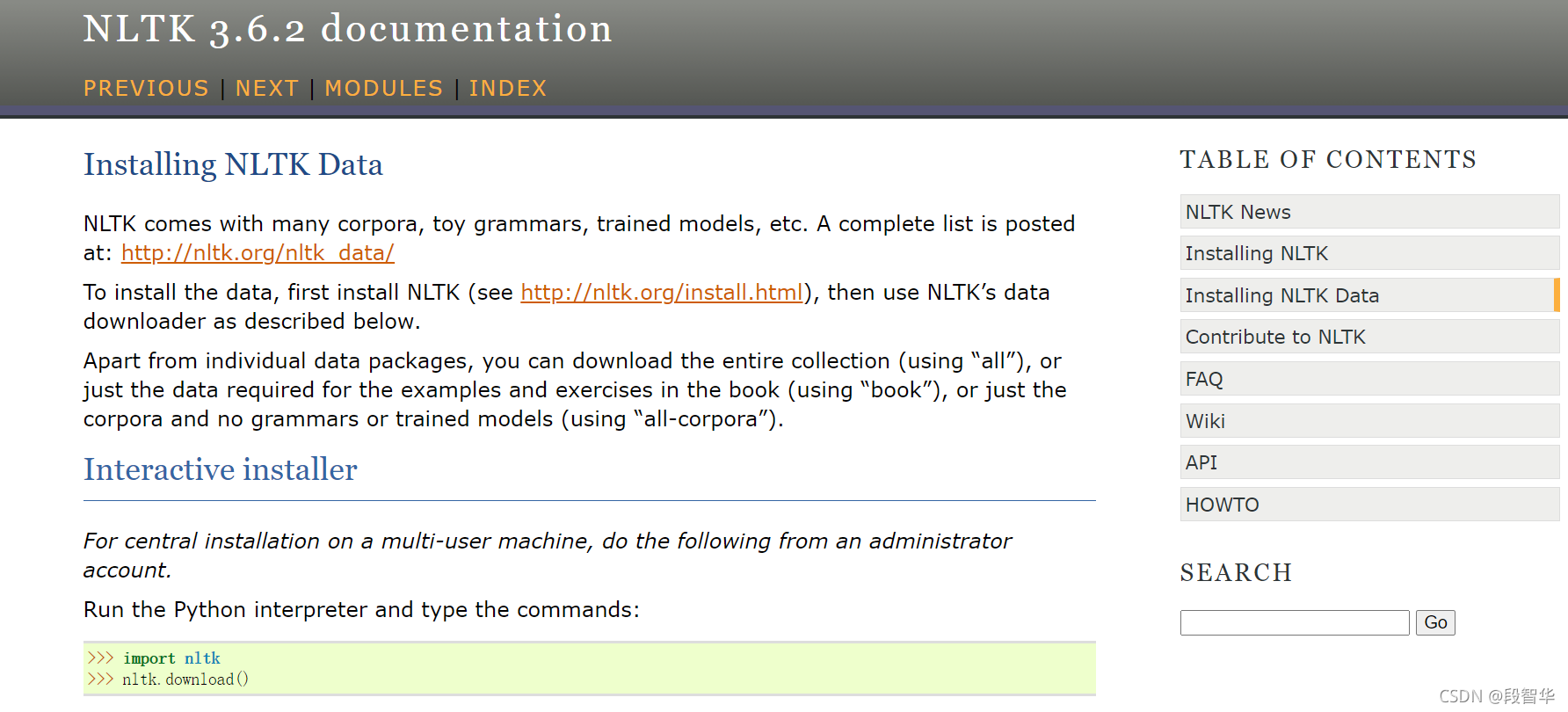
登录到nltk数据下载链接,单击download链接下载数据 。
http://www.nltk.org/nltk_data/

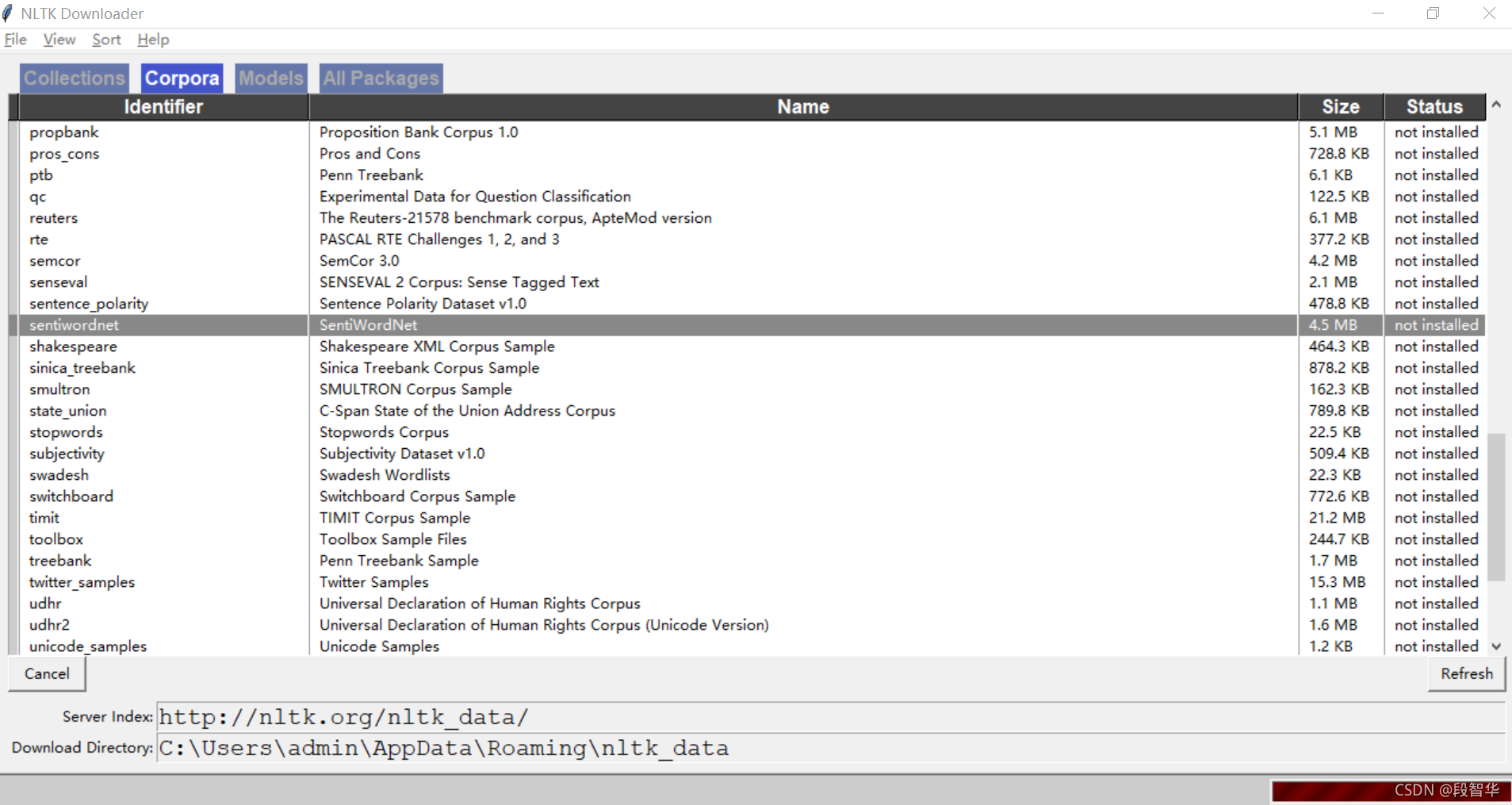
方法二:通过nltk下载工具进行下载
在python的交互提示符中输入命令import nltk 及 nltk.download(),在windows系统中会弹出 NLTK Downloader工具,设置Server Index的链接地址http://www.nltk.org/nltk_data/,选择数据集进行下载。
(base) C:\Users\admin>python
Python 3.8.8 (default, Apr 13 2021, 15:08:03) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import nltk
>>> nltk.download()
在jupyter notebook中下载nltk数据集 。
!pip install gensim==3.8.3
import torch
import nltk
nltk.download('punkt')
Requirement already satisfied: gensim==3.8.3 in e:\anaconda3\envs\my_star_space\lib\site-packages (3.8.3)
Requirement already satisfied: six>=1.5.0 in e:\anaconda3\envs\my_star_space\lib\site-packages (from gensim==3.8.3) (1.15.0)
Requirement already satisfied: smart-open>=1.8.1 in e:\anaconda3\envs\my_star_space\lib\site-packages (from gensim==3.8.3) (5.2.1)
Requirement already satisfied: scipy>=0.18.1 in e:\anaconda3\envs\my_star_space\lib\site-packages (from gensim==3.8.3) (1.5.2)
Requirement already satisfied: Cython==0.29.14 in e:\anaconda3\envs\my_star_space\lib\site-packages (from gensim==3.8.3) (0.29.14)
Requirement already satisfied: numpy>=1.11.3 in e:\anaconda3\envs\my_star_space\lib\site-packages (from gensim==3.8.3) (1.19.5)
[nltk_data] Error loading punkt: <urlopen error [Errno 11004]
[nltk_data] getaddrinfo failed>
方法三:已从网上收集nltk_data.zip及sentiwordnet.zip,放到网盘里面,读者可以从网盘下载nltk数据集。
从AI studio环境收集nltk的sentiwordnet数据集
aistudio@jupyter-112853-2339160:~$
aistudio@jupyter-112853-2339160:~$ python
Python 3.7.4 (default, Aug 13 2019, 20:35:49)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import nltk
>>> nltk.download('sentiwordnet')
[nltk_data] Downloading package sentiwordnet to
[nltk_data] /home/aistudio/nltk_data...[nltk_data] Unzipping corpora/sentiwordnet.zip.
True
nltk_data 网盘数据集 下载
链接:https://pan.baidu.com/s/1t1mhl7Vob4Tmx49fzugDbQ
提取码:nfls
将nltk_data数据集下载到本地电脑,需确定数据集存放的文件目录,可以通过以下代码,从报错提示中查询python加载数据的目录信息,将下载的nltk数据集放到相应的目录就可以。
import nltk
nltk.word_tokenize("A pivot is the pin or the central point on which something balances or turns")
提示如下:
---------------------------------------------------------------------------
LookupError Traceback (most recent call last)
<ipython-input-2-1fa24f4409cc> in <module>1 import nltk
----> 2 nltk.word_tokenize("A pivot is the pin or the central point on which something balances or turns")e:\anaconda3\envs\my_star_space\lib\site-packages\nltk\tokenize\__init__.py in word_tokenize(text, language, preserve_line)128 :type preserve_line: bool129 """
.......e:\anaconda3\envs\my_star_space\lib\site-packages\nltk\data.py in _open(resource_url)873 874 if protocol is None or protocol.lower() == "nltk":
--> 875 return find(path_, path + [""]).open()876 elif protocol.lower() == "file":877 # urllib might not use mode='rb', so handle this one ourselves:e:\anaconda3\envs\my_star_space\lib\site-packages\nltk\data.py in find(resource_name, paths)581 sep = "*" * 70582 resource_not_found = "\n%s\n%s\n%s\n" % (sep, msg, sep)
--> 583 raise LookupError(resource_not_found)584 585 LookupError:
**********************************************************************Resource punkt not found.Please use the NLTK Downloader to obtain the resource:>>> import nltk>>> nltk.download('punkt')For more information see: https://www.nltk.org/data.htmlAttempted to load tokenizers/punkt/english.pickleSearched in:- 'C:\\Users\\admin/nltk_data'- 'e:\\anaconda3\\envs\\my_star_space\\nltk_data'- 'e:\\anaconda3\\envs\\my_star_space\\share\\nltk_data'- 'e:\\anaconda3\\envs\\my_star_space\\lib\\nltk_data'- 'C:\\Users\\admin\\AppData\\Roaming\\nltk_data'- 'C:\\nltk_data'- 'D:\\nltk_data'- 'E:\\nltk_data'- ''
**********************************************************************将nltk_data解压文件放到相应的目录E:\anaconda3\envs\my_star_space\nltk_data
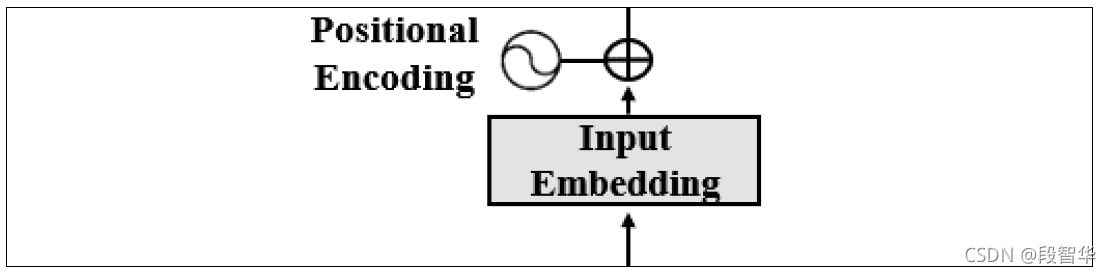
位置编码(Positional encoding)
我们输入Transformer的位置编码函数时不知道单词在序列中的位置:
- 我们无法创建独立的位置向量,对于Transformer的训练速度导致较高的成本,使注意子层非常复杂。
- Transformer的思想是向输入中添加位置编码值,而不是用额外的向量来描述序列中标记的位置。
- Transformer需要一个固定大小的dmodel=512(或其他维度),位置编码函数输出的每个向量的值。
-回到单词嵌入子层中使用的句子,我们可以看到黑色black 和棕色brown 可能相似,但它们相距甚远。
The black cat sat on the couch and the brown dog slept on the rug.
- 问题是要找到一种方法为每个单词的单词嵌入增加一个值,这样就有了位置信息。但是,我们需要向dmodel=512添加一个值,对于每个单词嵌入向量,找到一种方法, 对于范围为(0,512)维的单词嵌入向量的每个i向量提供相应的信息。
- 实现这一目标有很多方法,论文作者找到了一种巧妙的使用方法,用正弦和余弦值表示位置编码,非常小,但非常有用。
- Vaswani et al. (2017) 提供正弦和余弦函数,以便生成每个位置的位置编码(PE,positional encoding) dmodel=512

-
如果我们从单词嵌入向量的起始位置开始,以常数(512),i=0,以i=511结束。这意味着正弦函数将应用于偶数,余弦函数应用于奇数。
-
一些实现方式有所不同,在这种情况下,正弦函数的域可以是
i ∈ [0,255],余弦函数的域是 i∈ [256,512]. 这将产生类似的结果。 -
在本文中,我们将按照Vaswani描述的方式(Vaswani
et al. (2017).)使用这些函数
def positional_encoding(pos,pe):for i in range(0, 512,2):pe[0][i] = math.sin(pos / (10000 ** ((2 * i)/d_model)))pe[0][i+1] = math.cos(pos / (10000 ** ((2 * i)/d_model)))return pe
在python中使用正弦函数,测试一下官网的实例
import math
t=[]
m=[]
for x in range(-100, 100,1):#print(x)t.append(x)y=math.sin(2/10000**(2*x/512)) m.append(y)
plt.plot(t,m,'-r')
plt.show()
pos=2运行结果如下:

pos=10的运行结果
import math
t=[]
m=[]
for x in range(-100, 100,1):#print(x)t.append(x)y=math.sin(10/10000**(2*x/512)) m.append(y)
plt.plot(t,m,'-r')
plt.show()

自己测试一下各种组合方法,按奇数 偶数 分别使用正弦、余弦计算
import math
t=[]
m=[]
for x in range(0, 100,2):#print(x)t.append(x)t.append(x+1) y= math.sin(2 / (10000 ** ((2 * x)/512)))y_1 = math.cos(2 / (10000 ** ((2 * x)/512))) m.append(y)m.append(y_1)
plt.plot(t,m,'-r')
plt.show()
打印结果如下:

测试一下只使用正弦函数的情况
import math
t=[]
m=[]
for x in range(0, 100,2):#print(x)t.append(x)t.append(x+1) y= math.sin(2 / (10000 ** ((2 * x)/512))) #y_1 = math.cos(2 / (10000 ** ((2 * a/512))) m.append(y)m.append(y_1)
plt.plot(t,m,'-r')
plt.show()
运行结果如下

回到本文中分析的句子,我们可以看到黑色(black)是在位置2处,棕色(brown)在位置10处:
The black cat sat on the couch and the brown dog slept on the rug.
如果我们将正弦和余弦函数应用于pos=2,则得到的大小为512位置编码向量:
PE(2)=
[[ 9.09297407e-01 -4.16146845e-01 9.58144367e-01 -2.86285430e-01
9.87046242e-01 -1.60435960e-01 9.99164224e-01 -4.08766568e-02
9.97479975e-01 7.09482506e-02 9.84703004e-01 1.74241230e-01
9.63226616e-01 2.68690288e-01 9.35118318e-01 3.54335666e-01
9.02130723e-01 4.31462824e-01 8.65725577e-01 5.00518918e-01
8.27103794e-01 5.62049210e-01 7.87237823e-01 6.16649508e-01
7.46903539e-01 6.64932430e-01 7.06710517e-01 7.07502782e-01
…
5.47683925e-08 1.00000000e+00 5.09659337e-08 1.00000000e+00
4.74274735e-08 1.00000000e+00 4.41346799e-08 1.00000000e+00
4.10704999e-08 1.00000000e+00 3.82190599e-08 1.00000000e+00
3.55655878e-08 1.00000000e+00 3.30963417e-08 1.00000000e+00
3.07985317e-08 1.00000000e+00 2.86602511e-08 1.00000000e+00
2.66704294e-08 1.00000000e+00 2.48187551e-08 1.00000000e+00
2.30956392e-08 1.00000000e+00 2.14921574e-08 1.00000000e+00]]
也可获得位置10的位置编码向量 size=512, 位置=10:
PE(10)=
[[-5.44021130e-01 -8.39071512e-01 1.18776485e-01 -9.92920995e-01
6.92634165e-01 -7.21289039e-01 9.79174793e-01 -2.03019097e-01
9.37632740e-01 3.47627431e-01 6.40478015e-01 7.67976522e-01
2.09077001e-01 9.77899194e-01 -2.37917677e-01 9.71285343e-01
-6.12936735e-01 7.90131986e-01 -8.67519796e-01 4.97402608e-01
-9.87655997e-01 1.56638563e-01 -9.83699203e-01 -1.79821849e-01
…
2.73841977e-07 1.00000000e+00 2.54829672e-07 1.00000000e+00
2.37137371e-07 1.00000000e+00 2.20673414e-07 1.00000000e+00
2.05352507e-07 1.00000000e+00 1.91095296e-07 1.00000000e+00
1.77827943e-07 1.00000000e+00 1.65481708e-07 1.00000000e+00
1.53992659e-07 1.00000000e+00 1.43301250e-07 1.00000000e+00
1.33352145e-07 1.00000000e+00 1.24093773e-07 1.00000000e+00
1.15478201e-07 1.00000000e+00 1.07460785e-07 1.00000000e+00]]
用于单词嵌入的余弦相似函数非常方便,更好地显示位置的接近程度
cosine_similarity(pos(2), pos(10)= [[0.8600013]]
black和brown两个词的位置相似性与词汇的相似性(组合在一起的词组) 不同:
cosine_similarity(black, brown)= [[0.9998901]]
位置的编码显示出比单词更低的相似度值,位置编码将这些单词分开,单词嵌入的词向量会因用于训练它们的语料库而不同。现在的问题是如何将位置编码添加到单词嵌入向量中。
Adding positional encoding to the embedding vector
Transformer的作者找到了一种简单的方法,只需添加位置编码向量到单词嵌入向量:

星空智能对话机器人系列博客
-
NLP星空智能对话机器人系列:第二次星空智能对话机器人Zoom线上演示安排
-
NLP星空智能对话机器人系列:StarSpace: Embed All The Things
-
NLP星空智能对话机器人系列:Facebook StarSpace框架初体验
-
NLP星空智能对话机器人系列:Facebook StarSpace框架案例数据加载
-
NLP星空智能对话机器人系列:深入理解Transformer自然语言处理 多头注意力架构-通过Python实例计算Q, K, V
-
NLP星空智能对话机器人系列:深入理解Transformer自然语言处理 多头注意力架构 Q K V注意力评分
-
NLP星空智能对话机器人系列:深入理解Transformer自然语言处理 多头注意力架构 Concatenation of the output of the heads
这篇关于自然语言处理NLP星空智能对话机器人系列:深入理解Transformer自然语言处理 位置编码(positional_encoding)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






