本文主要是介绍【莫凡PyTorch教程笔记】-2. 建造第一个神经网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关系拟合 (回归)
这次会来见证神经网络是如何通过简单的形式将一群数据用一条线条来表示. 或者说, 是如何在数据当中找到他们的关系, 然后用神经网络模型来建立一个可以代表他们关系的线条.
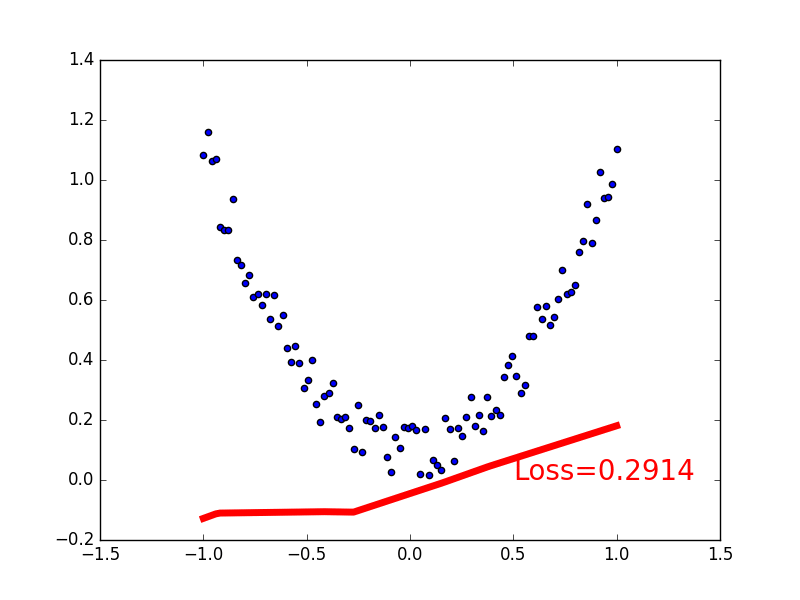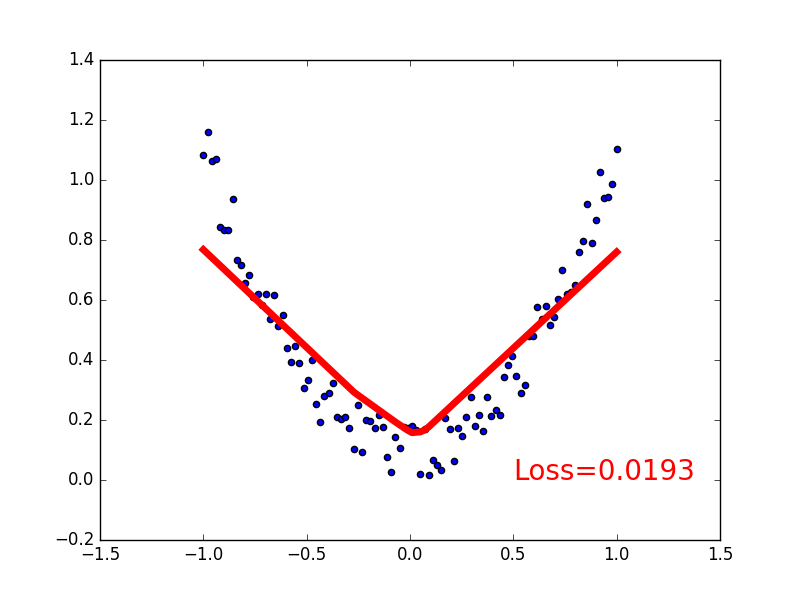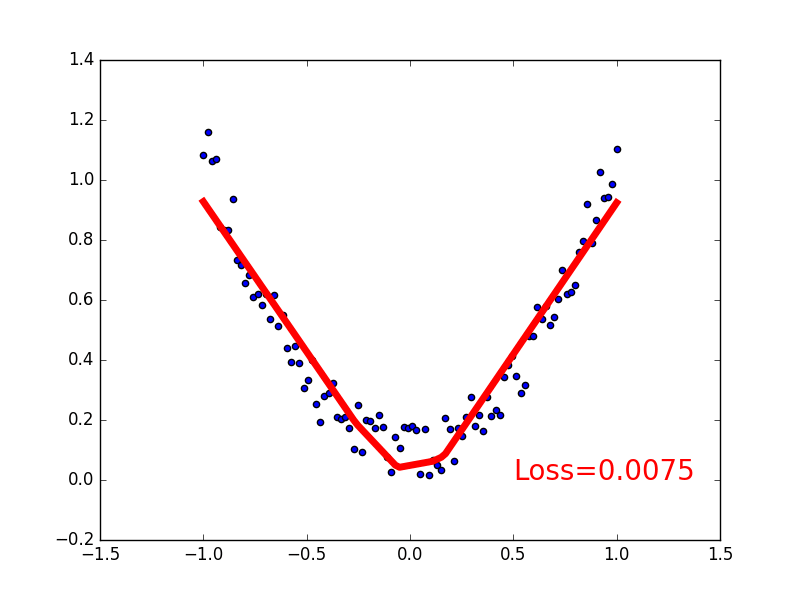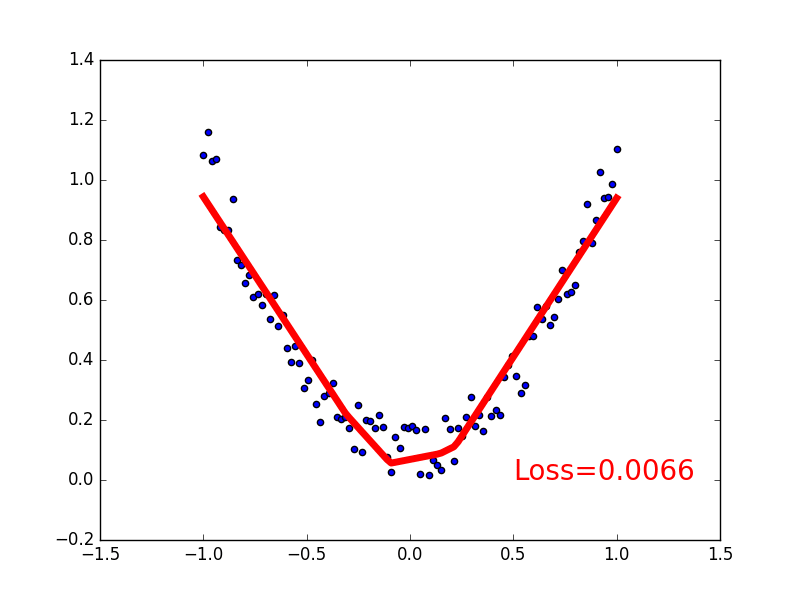
建立数据集
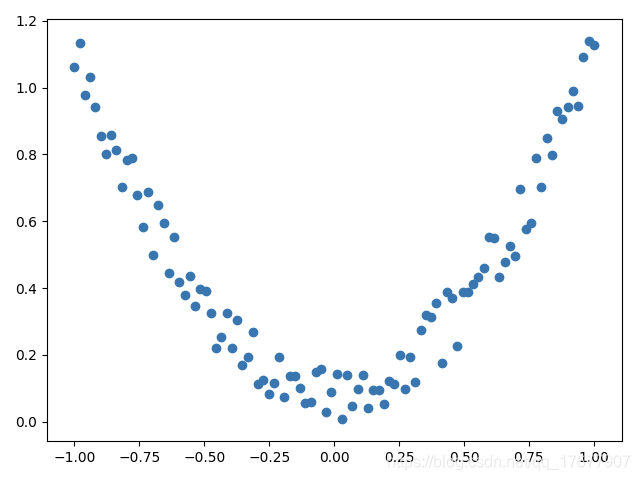
我们创建一些假数据来模拟真实的情况. 比如一个一元二次函数: y = a * x^2 + b, 我们给 y 数据加上一点噪声来更加真实的展示它.
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # x data (tensor), shape=(100, 1)
"""
这里的unsqueeze(tensor,1)将一维tensor分解为
tensor([[ 1],[ 2],[ 3],[ 4]])
"""
y = x.pow(2) + 0.2*torch.rand(x.size()) # noisy y data (tensor), shape=(100, 1)
建立神经网络
建立一个神经网络我们可以直接运用 torch 中的体系. 先定义所有的层属性(init()), 然后再一层层搭建(forward(x))层于层的关系链接. 建立关系的时候, 我们会用到激励函数
import torch.nn.functional as F # 激励函数都在这
class Net(torch.nn.Module): # 继承 torch 的 Moduledef __init__(self, n_feature, n_hidden, n_output):super(Net, self).__init__() # 继承 __init__ 功能# 定义每层用什么样的形式self.hidden = torch.nn.Linear(n_feature, n_hidden) # 隐藏层线性输出self.predict = torch.nn.Linear(n_hidden, n_output) # 输出层线性输出def forward(self, x): # 这同时也是 Module 中的 forward 功能# 正向传播输入值, 神经网络分析出输出值x = F.relu(self.hidden(x)) # 激励函数(隐藏层的线性值)x = self.predict(x) # 输出值return xnet = Net(n_feature=1, n_hidden=10, n_output=1)print(net) # net 的结构
"""
Net((hidden): Linear(in_features=1, out_features=10, bias=True)(predict): Linear(in_features=10, out_features=1, bias=True)
)
"""
训练网络
训练的步骤很简单, 如下:
# optimizer 是训练的工具
optimizer = torch.optim.SGD(net.parameters(), lr=0.2) # 传入 net 的所有参数, 学习率 这里使用常见的SGD
loss_func = torch.nn.MSELoss() # 预测值和真实值的误差计算公式 (均方差)# 迭代更新100轮参数
for t in range(100):prediction = net(x) # 喂给 net 训练数据 x, 输出预测值loss = loss_func(prediction, y) # 计算两者的误差# 下面这三步基本是标配optimizer.zero_grad() # 清空上一步的残余更新参数值loss.backward() # 误差反向传播, 计算参数更新值optimizer.step() # 将参数更新值施加到 net 的 parameters 上
下面是可视化结果
区分类型 (分类)
建立数据集
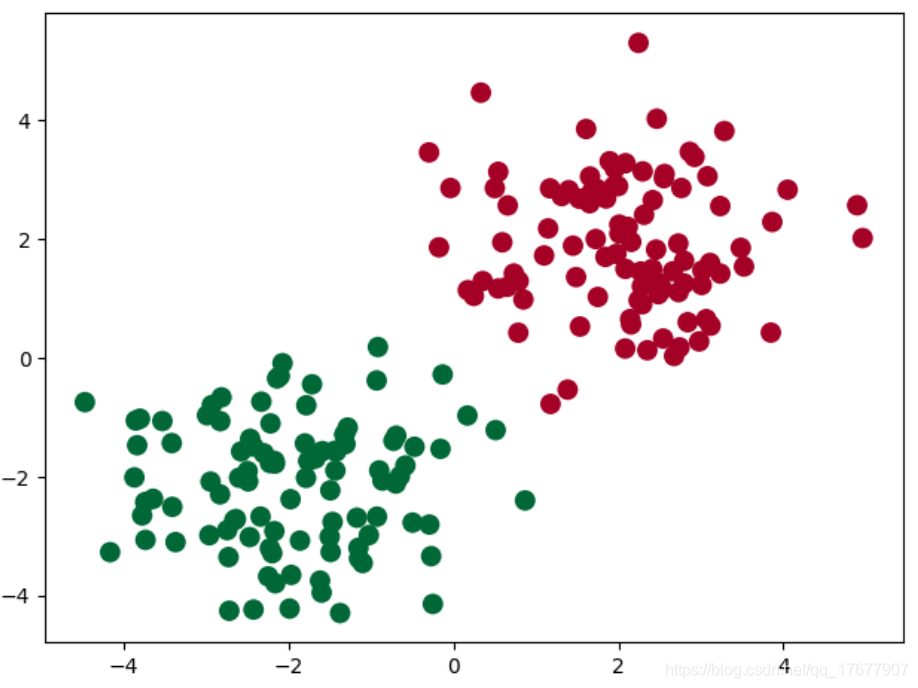
我们创建一些假数据来模拟真实的情况. 比如两个二次分布的数据, 不过他们的均值都不一样.
import torch
import matplotlib.pyplot as plt# 假数据
n_data = torch.ones(100, 2) # 数据的基本形态 ones会创建100行2列的矩阵 元素全是1
x0 = torch.normal(2*n_data, 1) # 类型0 x data (tensor), shape=(100, 2) normal(mean, std)返回均值是mean,标准差是std的正太分布
y0 = torch.zeros(100) # 类型0 y data (tensor), shape=(1, 100) zeros(100) 返回包含100个0的列表
x1 = torch.normal(-2*n_data, 1) # 类型1 x data (tensor), shape=(100, 2)
y1 = torch.ones(100) # 类型1 y data (tensor), shape=(1, 100) ones(100) 返回包含100个1的列表# print('x0', x1) # (100,2)# 注意 x, y 数据的数据形式是一定要像下面一样 (torch.cat 是在合并数据)
x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # cat用于合并两个size相同的tensor 0表示横着合并
y = torch.cat((y0, y1), ).type(torch.LongTensor) # cat的维度默认是0 横着拼
建立神经网络
建立一个神经网络我们可以直接运用 torch 中的体系. 先定义所有的层属性(_init_()), 然后再一层层搭建(forward(x))层于层的关系链接. 这个和我们在前面 regression 的时候的神经网络基本没差. 建立关系的时候, 我们会用到激励函数
import torch
import torch.nn.functional as F # 激励函数都在这class Net(torch.nn.Module): # 继承 torch 的 Moduledef __init__(self, n_feature, n_hidden, n_output):super(Net, self).__init__() # 继承 __init__ 功能self.hidden = torch.nn.Linear(n_feature, n_hidden) # 隐藏层线性输出self.out = torch.nn.Linear(n_hidden, n_output) # 输出层线性输出def forward(self, x):# 正向传播输入值, 神经网络分析出输出值x = F.relu(self.hidden(x)) # 激励函数(隐藏层的线性值)x = self.out(x) # 输出值, 但是这个不是预测值, 预测值还需要再另外计算return xnet = Net(n_feature=2, n_hidden=10, n_output=2) # 几个类别就几个 outputprint(net) # net 的结构
"""
Net((hidden): Linear(in_features=2, out_features=10, bias=True)(out): Linear(in_features=10, out_features=2, bias=True)
)
"""
训练网络
训练的步骤很简单, 如下:
# optimizer 是训练的工具
optimizer = torch.optim.SGD(net.parameters(), lr=0.02) # 传入 net 的所有参数, 学习率
# 算误差的时候, 注意真实值!不是! one-hot 形式的, 而是1D Tensor, (batch,)
# 但是预测值是2D tensor (batch, n_classes)
loss_func = torch.nn.CrossEntropyLoss()for t in range(100):out = net(x) # 喂给 net 训练数据 x, 输出分析值loss = loss_func(out, y) # 计算两者的误差optimizer.zero_grad() # 清空上一步的残余更新参数值loss.backward() # 误差反向传播, 计算参数更新值optimizer.step() # 将参数更新值施加到 net 的 parameters 上
快速搭建法
我们先看看之前写神经网络时用到的步骤. 我们用 net1 代表这种方式搭建的神经网络.
class Net(torch.nn.Module):def __init__(self, n_feature, n_hidden, n_output):super(Net, self).__init__()self.hidden = torch.nn.Linear(n_feature, n_hidden)self.predict = torch.nn.Linear(n_hidden, n_output)def forward(self, x):x = F.relu(self.hidden(x))x = self.predict(x)return xnet1 = Net(1, 10, 1) # 这是我们用这种方式搭建的 net1
我们用 class 继承了一个 torch 中的神经网络结构, 然后对其进行了修改, 不过还有更快的一招, 用一句话就概括了上面所有的内容!
net2 = torch.nn.Sequential(torch.nn.Linear(1, 10),torch.nn.ReLU(),torch.nn.Linear(10, 1)
)
我们再对比一下两者的结构:
print(net1)
"""
Net ((hidden): Linear (1 -> 10)(predict): Linear (10 -> 1)
)
"""
print(net2)
"""
Sequential ((0): Linear (1 -> 10)(1): ReLU ()(2): Linear (10 -> 1)
)
"""
我们会发现 net2 多显示了一些内容, 这是为什么呢? 原来他把激励函数也一同纳入进去了, 但是 net1 中, 激励函数实际上是在 forward() 功能中才被调用的. 这也就说明了, 相比 net2, net1 的好处就是, 你可以根据你的个人需要更加个性化你自己的前向传播过程, 比如(RNN). 不过如果你不需要七七八八的过程, 相信 net2 这种形式更适合你.
保存提取
训练好了一个模型, 我们当然想要保存它, 留到下次要用的时候直接提取直接用, 这就是这节的内容啦. 我们用回归的神经网络举例实现保存提取.
保存
我们快速地建造数据, 搭建网络:
torch.manual_seed(1) # reproducible# 假数据
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # x data (tensor), shape=(100, 1)
y = x.pow(2) + 0.2*torch.rand(x.size()) # noisy y data (tensor), shape=(100, 1)def save():# 建网络net1 = torch.nn.Sequential(torch.nn.Linear(1, 10),torch.nn.ReLU(),torch.nn.Linear(10, 1))optimizer = torch.optim.SGD(net1.parameters(), lr=0.5)loss_func = torch.nn.MSELoss()# 训练for t in range(100):prediction = net1(x)loss = loss_func(prediction, y)optimizer.zero_grad()loss.backward()optimizer.step()
接下来我们有两种途径来保存
torch.save(net1, 'net.pkl') # 保存整个网络torch.save(net1.state_dict(), 'net_params.pkl') # 只保存网络中的参数 (速度快, 占内存少)
提取网络
这种方式将会提取整个神经网络, 网络大的时候可能会比较慢.
def restore_net():# restore entire net1 to net2net2 = torch.load('net.pkl')prediction = net2(x)
只提取网络参数
这种方式将会提取所有的参数, 然后再放到你的新建网络中.
def restore_params():# 新建 net3net3 = torch.nn.Sequential(torch.nn.Linear(1, 10),torch.nn.ReLU(),torch.nn.Linear(10, 1))# 将保存的参数复制到 net3net3.load_state_dict(torch.load('net_params.pkl'))prediction = net3(x)
批训练
Torch 中提供了一种帮你整理你的数据结构的好东西, 叫做 DataLoader, 我们能用它来包装自己的数据, 进行批训练. 而且批训练可以有很多种途径,
DataLoader
DataLoader 是 torch 给你用来包装你的数据的工具. 所以你要讲自己的 (numpy array 或其他) 数据形式装换成 Tensor, 然后再放进这个包装器中. 使用 DataLoader 有什么好处呢? 就是他们帮你有效地迭代数据, 举例:
import torch
import torch.utils.data as Data
torch.manual_seed(1) # reproducibleBATCH_SIZE = 5 # 批训练的数据个数x = torch.linspace(1, 10, 10) # x data (torch tensor)
y = torch.linspace(10, 1, 10) # y data (torch tensor)# 先转换成 torch 能识别的 Dataset
torch_dataset = Data.TensorDataset(x, y) # 把 dataset 放入 DataLoader
loader = Data.DataLoader(dataset=torch_dataset, # torch TensorDataset formatbatch_size=BATCH_SIZE, # mini batch sizeshuffle=True, # 要不要打乱数据 (打乱比较好)num_workers=2, # 多线程来读数据
)for epoch in range(3): # 训练所有!整套!数据 3 次for step, (batch_x, batch_y) in enumerate(loader): # 每一步 loader 释放一小批数据用来学习 step表示可以取几次的batch# 假设这里就是你训练的地方...# 打出来一些数据print('Epoch: ', epoch, '| Step: ', step, '| batch x: ',batch_x.numpy(), '| batch y: ', batch_y.numpy())"""
Epoch: 0 | Step: 0 | batch x: [ 5. 7. 10. 3. 4.] | batch y: [6. 4. 1. 8. 7.]
Epoch: 0 | Step: 1 | batch x: [2. 1. 8. 9. 6.] | batch y: [ 9. 10. 3. 2. 5.]
Epoch: 1 | Step: 0 | batch x: [ 4. 6. 7. 10. 8.] | batch y: [7. 5. 4. 1. 3.]
Epoch: 1 | Step: 1 | batch x: [5. 3. 2. 1. 9.] | batch y: [ 6. 8. 9. 10. 2.]
Epoch: 2 | Step: 0 | batch x: [ 4. 2. 5. 6. 10.] | batch y: [7. 9. 6. 5. 1.]
Epoch: 2 | Step: 1 | batch x: [3. 9. 1. 8. 7.] | batch y: [ 8. 2. 10. 3. 4.]
"""
可以看出, 每步都导出了5个数据进行学习. 然后每个 epoch 的导出数据都是先打乱了以后再导出.
优化器
这节内容主要是用 Torch 实践几种优化器
伪数据
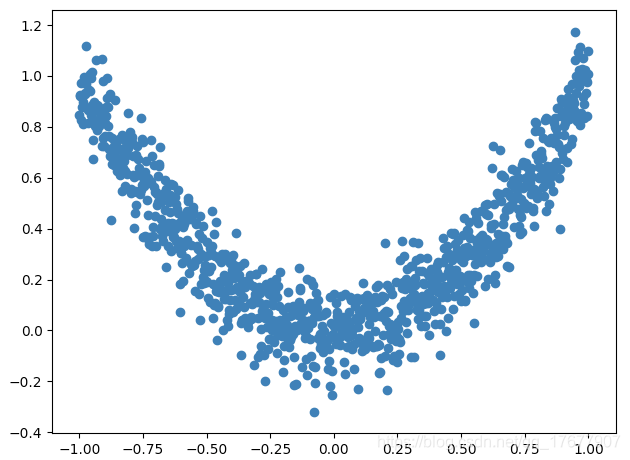
为了对比各种优化器的效果, 我们需要有一些数据, 今天我们还是自己编一些伪数据, 这批数据是这样的:
import torch
import torch.utils.data as Data
import torch.nn.functional as F
import matplotlib.pyplot as plttorch.manual_seed(1) # reproducibleLR = 0.01
BATCH_SIZE = 32
EPOCH = 12# fake dataset
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))# plot dataset
plt.scatter(x.numpy(), y.numpy())
plt.show()# 使用上节内容提到的 data loader
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2,)
每个优化器优化一个神经网络
为了对比每一种优化器, 我们给他们各自创建一个神经网络, 但这个神经网络都来自同一个 Net 形式.
# 默认的 network 形式
class Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.hidden = torch.nn.Linear(1, 20) # hidden layerself.predict = torch.nn.Linear(20, 1) # output layerdef forward(self, x):x = F.relu(self.hidden(x)) # activation function for hidden layerx = self.predict(x) # linear outputreturn x# 为每个优化器创建一个 net
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
优化器 Optimizer
接下来创建不同的优化器, 用来训练不同的网络. 并创建一个 loss_func 用来计算误差. 我们用几种常见的优化器, SGD, Momentum, RMSprop, Adam.
# different optimizers
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]loss_func = torch.nn.MSELoss()
losses_his = [[], [], [], []] # 记录 training 时不同神经网络的 loss
训练/出图
接下来训练和 loss 画图.
for epoch in range(EPOCH):print('Epoch: ', epoch)for step, (b_x, b_y) in enumerate(loader):# 对每个优化器, 优化属于他的神经网络for net, opt, l_his in zip(nets, optimizers, losses_his):output = net(b_x) # get output for every netloss = loss_func(output, b_y) # compute loss for every netopt.zero_grad() # clear gradients for next trainloss.backward() # backpropagation, compute gradientsopt.step() # apply gradientsl_his.append(loss.data.numpy()) # loss recoder
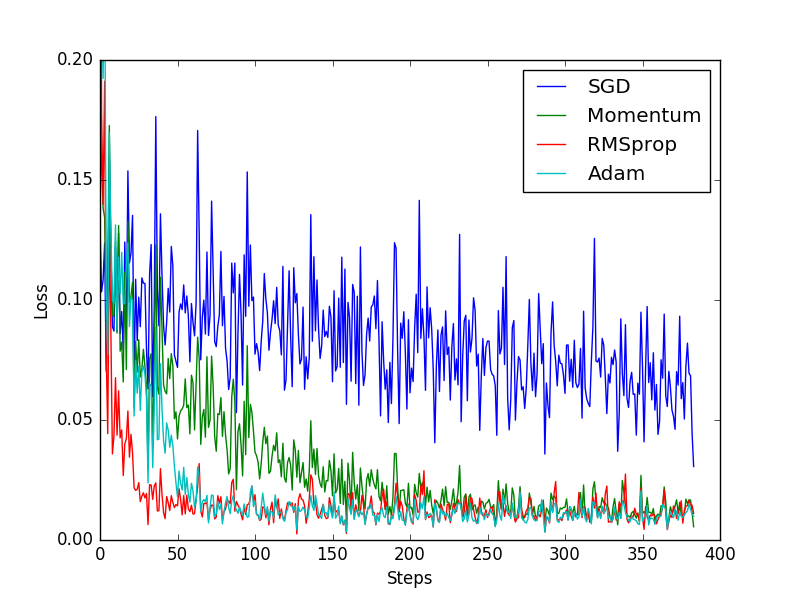
SGD 是最普通的优化器, 也可以说没有加速效果, 而 Momentum 是 SGD 的改良版, 它加入了动量原则. 后面的 RMSprop 又是 Momentum 的升级版. 而 Adam 又是 RMSprop 的升级版. 不过从这个结果中我们看到, Adam 的效果似乎比 RMSprop 要差一点. 所以说并不是越先进的优化器, 结果越佳. 我们在自己的试验中可以尝试不同的优化器, 找到那个最适合你数据/网络的优化器.
这篇关于【莫凡PyTorch教程笔记】-2. 建造第一个神经网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







