本文主要是介绍python+selenium StaleElementReferenceException-- selenium烦人错误之二,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
StaleElementReferenceException,这也是一个比较让人头疼的异常。之前在写用例的时候,就遇到过这个问题,百度了好几遍看到的结果都是说是因为元素未加载,但其实我查看日志已经看到捕获的元素打印出来了。具体的情况还是以之前的问题为例,展开说一下。
(由于写这篇文章太晚,一些关键截图都已经丢失了,但解决代码还在,我尽量给大家描述清楚)
首先,我是获取一个页面相同属性的一些元素的文本,这是我的一个获取组元素文本的底层方法。
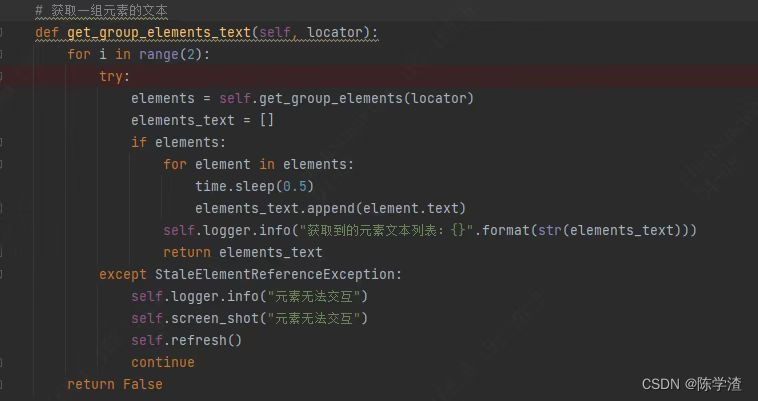
try部分应该可以理解,就是先获取元素组,然后遍历元素获取文本。其实这里可以看到,我以前也是遇到过这个异常的,所以加了StaleElementReferenceException的异常,在捕捉到异常后,我按照网上的解决方法,是再重新获取一次,但是问题依然没有解决。
这里的for循环就是为了重新获取,这个其实蛮重要的,基本所有获取元素的方法我都会加上,可以规避一些例如元素未加载完获取失败,或者说网络延时获取失败的问题,再给他一次获取的机会。如果想灵活控制是否循环获取,或者是否刷新,可以在参数里加上retry和refresh,然后检查参数判断是否刷新和循环获取即可,如果怕影响之前的方法调用,可以直接给这两个值加上默认值False。
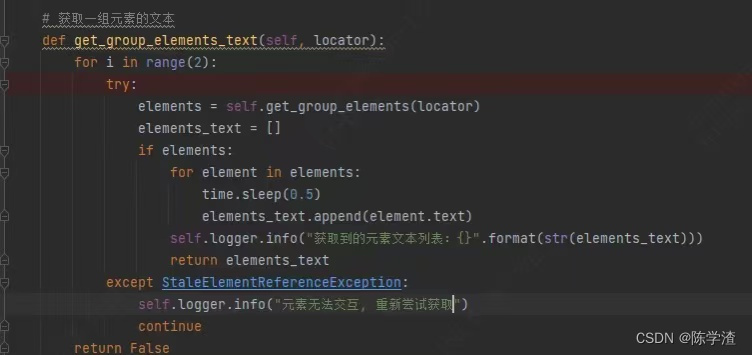
回到正题,这个地方困惑了我很久。后面我自己看日志的时候,突然想到,网上说的是这种情况也有可能是元素失效了,那我再获取一次不就可以了吗,但是为什么这里重新获取了还是失败呢。于是我自己脑补了一下执行步骤,终于找到了问题点!我是重新获取了,但是我为什么要在获取之前又刷新页面呢!!
于是我赶忙把refresh删掉,然后再重新尝试了一把,这一次果然成功了。
下面是修改后的代码和打印的日志。
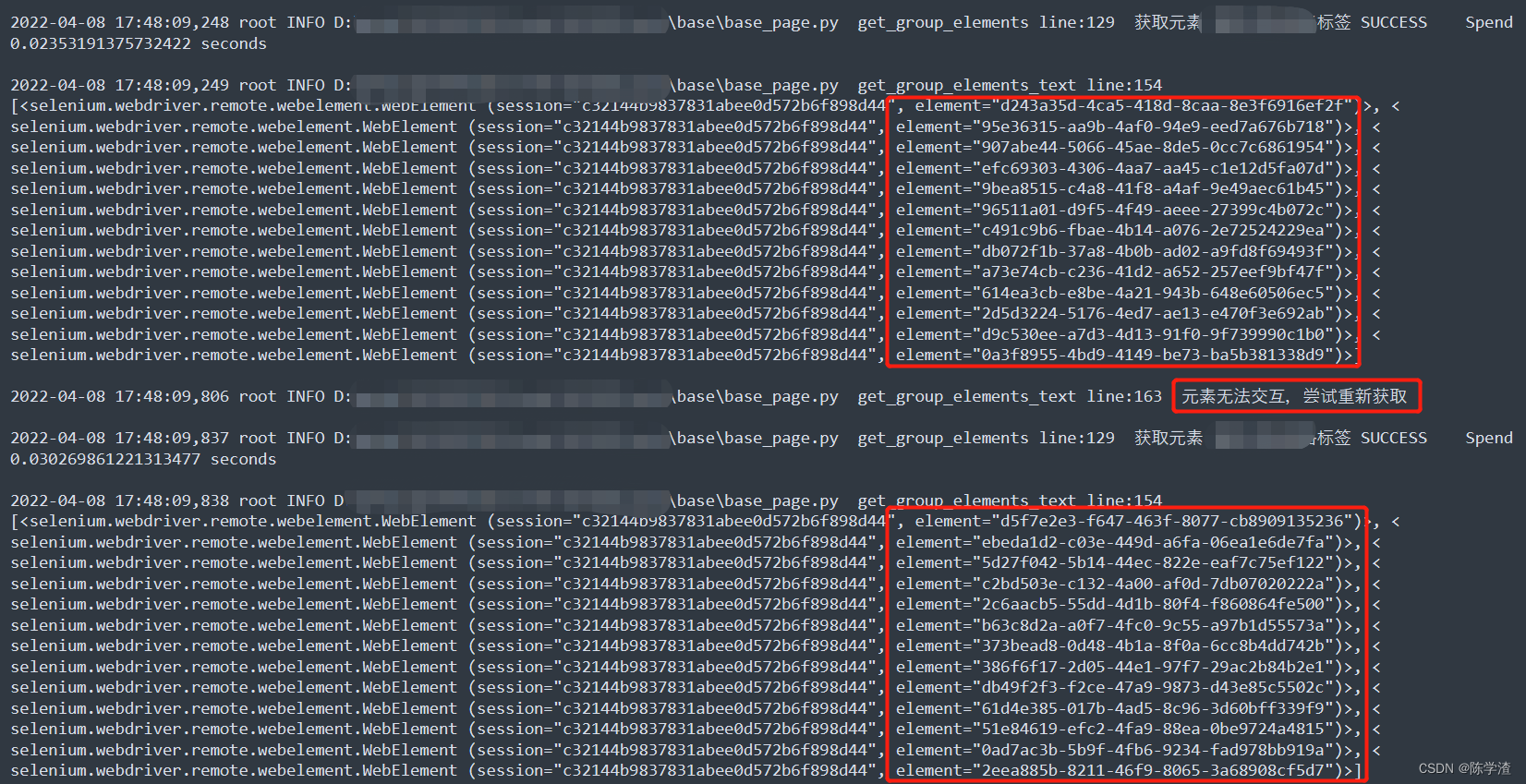
值得一提的是,日志里我们可以看到,这个方法确实循环了两次,因为第二个方框打印了无法交互,重新获取的日志。再仔细看看两次获取element的值,可以看到两组element确实是不一样的。
大家遇到这个问题的时候,可以尝试把element打印出来看看是不是不一样,如果不一样可以用我这个方法解决,如果解决不了可以在评论区留言或者私信我,我们一起研究讨论一下。
这篇关于python+selenium StaleElementReferenceException-- selenium烦人错误之二的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




