本文主要是介绍12.10多种编码方式,编码方案选择策略(递归级联),PDE,RLE代码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者如何选择和设计编码方案,以实现高效的解压缩和高压缩比?BtrBlocks是否适用于所有类型的数据?
选择和设计编码方案:
- 结合多种高效编码方案:BtrBlocks 通过选择一组针对不同数据分布的高效编码方案,实现高压缩比和快速高效的解压缩。
- 基于采样的方案选择:BtrBlocks 对每个编码方案在样本上进行测试,并选择表现最佳的方案。采样算法在保持相邻元组的局部性和准确表示整个数据范围方面取得了平衡。
- 级联应用方案:BtrBlocks 的递归应用方法将一个方案应用于另一个方案的输出,直至达到最大递归深度。
BtrBlocks 适用于所有类型的数据:
- 支持各种数据类型:BtrBlocks 用于处理有符号整数、双精度浮点数和可变长度字符串等类型的数据。
- 针对浮点数的伪十进制编码:BtrBlocks 引入了针对二进制浮点数的伪十进制编码,以提高浮点数数据的压缩效果。
总之,作者通过结合多种高效编码方案、使用基于采样的方案选择和递归应用方法,实现了高效的解压缩和高压缩比。BtrBlocks 适用于各种数据类型,包括有符号整数、双精度浮点数和可变长度字符串。
级联
级联是指将多个设备或系统按照一定的顺序连接起来,形成一个整体,使得每个设备或系统的输出作为下一个设备或系统的输入,实现功能的递进和互补。
举个例子,我们可以考虑一个音响系统的级联。假设有一个音乐播放器和一个音箱,我们可以将它们级联起来。首先,将音乐播放器的音频输出连接到音箱的音频输入接口上。这样,在播放音乐时,音乐播放器会将音频信号发送到音箱进行放大和输出,从而可以听到更大声音的音乐。在这个例子中,音乐播放器是级联系统中的第一个设备,音箱是第二个设备,它们通过级联连接起来,实现了音频信号的输出和放大。
当我们连接多个电视机或显示器来同时播放相同的内容时,就可以将它们级联。其中一个电视机或显示器作为主机,其他的电视机或显示器作为从机,它们通过HDMI或VGA线连接在一起,主机的信号输出被发送到从机,实现内容的同时播放。
在计算机网络中,我们也可以将多个路由器级联起来。每个路由器连接着不同的局域网,并且将数据包根据目标地址进行路由转发,最终将数据包发送到正确的目标设备。
电子商务中的供应链管理也可以看作是级联的一个例子。产品从供应商到制造商,再到批发商,最后到零售商,形成一个供应链网络,每个环节都在前一环节的基础上进行加工、组装、配送等,最终将产品送到消费者手中。
这些例子中,级联的设备或系统能够实现信息、信号或物流的流动,从而达到更高的功能或效果。
编码方案
RLE & One Value。Run-length Encoding (RLE)是一种普遍的技术,它对相等值的连续序列进行压缩。例如,连续的序列{42, 42, 42},存储为(42, 3)。One Value是针对只有一个唯一值的列进行特殊优化。
Dictionary。字典编码是另一种简单但有效的方案,它使用(较短的)编码替换输入中的不同值。一个查找结构(即字典)将每个编码映射到原始的不同值。用于实现字典的数据结构由编码类型确定,字典通常是压缩字符串的唯一方式。
Frequency。在真实世界的数据集中,通常会有一些多次出现的值,形成了偏斜分布。DB2 BLU提出了一种基于数据频率的频率编码,使用多个代码长度。例如,一个一位编码可以表示两个最频繁的值,一个三位代码可以表示接下来的八个最频繁的值,依此类推。通常,一列只有一个主导的频繁值,其次频繁的值出现的频率呈指数下降。本文针对这种情况进行了优化,只存储:1)最频繁的值,2)标记哪些值是最频繁值的位图,3)不是最顶部值的异常值。
FOR & Bit-packing。对于整数,参考框架(Frame of Reference,FOR)将每个值编码为相对于选定基值的增量。例如,序列{105, 101, 113},我们可以选择基值为100,然后存储{5, 1, 13}。这在与Bit-packing结合使用时很有用,后者截断不必要的前导位,可以使用4位而不是8位对每个值进行Bit-packing。但是,基本的FOR方案在处理离群值时效果不佳。例如,向示例序列添加118,这种情况下每一个值都需要5位来表示。因此,Patched FOR (PFOR)将这些离群值存储为异常,并保留其余值的较小位宽。SIMD-FastPFOR和SIMD-FastBP128构建在这个想法上,并专门为SIMD(单指令多数据)优化了算法和布局。在BtrBlocks中使用这些现有的高性能实现。
FSST。Fast Static Symbol Table (FSST)是一种用于字符串的轻量级压缩方案,因为真实世界中大部分的数据都以字符串形式存储。FSST通过将长度最多为8个字节的频繁出现的子字符串替换为1个字节的编码来实现压缩。这些编码在一个固定大小的255条目字典(符号表)中进行跟踪。符号表是不可变的,并且用于整个字符串块。解压缩是简单且快速的但是压缩时需要找到一个合适的符号表,所以较为复杂。
NULL Storage Using Roaring Bitmaps。BtrBlocks使用Roaring Bitmap存储每列的NULL值。Roaring 的背后思想是根据位的局部密度使用不同的数据结构,这使得它对于许多数据分布非常高效。BtrBlocks使用一个针对现代硬件进行了优化的开源C++库来实现Roaring Bitmaps。除了追踪NULL值之外,BtrBlocks还使用Roaring Bitmaps来追踪内部编码方案(例如频率编码)的异常情况。
三. 方案选择和压缩
方案选择算法。针对不同数据类型本文提供了不同的编码方案,以适合各种不同的数据分布。但存在一些挑战:一种更好的编码方案选择是使用抽样。为了更好的压缩,样本必须捕获与压缩相关的数据集特征。例如,随机抽样可能不能很好地检测RLE是否有效。另一方面,简单地取第一个k个元组,就可能会得到一个有偏差的样本。方案选择算法的另一个挑战是要考虑级联,即它必须决定是否对已经编码的数据进行二次编码。(编码后的数据作为新的输入,然后尝试是否可以继续编码)
解决方案。在BtrBlocks中将在每一个样本中测试每种编码方案并且选择性能最好的方案。给定一个要压缩的数据块,每个递归级别都执行以下步骤:
(1)收集有关该块的简单统计信息。
(2)基于这些统计数据,过滤不可行的编码方案。
(3)对于每个可行的方案,使用数据中的一个样本来估计压缩比。
(4)选择观测压缩比最高的方案,并以此压缩整个块。
(5)如果压缩的输出为可压缩格式,则重复步骤(1)。
3.1 样本压缩率评估
为了让每个数据块选择最佳方案,样本必须代表数据的特征。主要是需要保留空间局部性以及捕捉到唯一值的分布,而且开销尽可能要低。如图1所示,文章从数据的非重叠部分的随机位置选择多个小runs。对于64,000个值的块大小,文章使用每个包含64个值的10个runs,从而得到1%数据的样本大小。
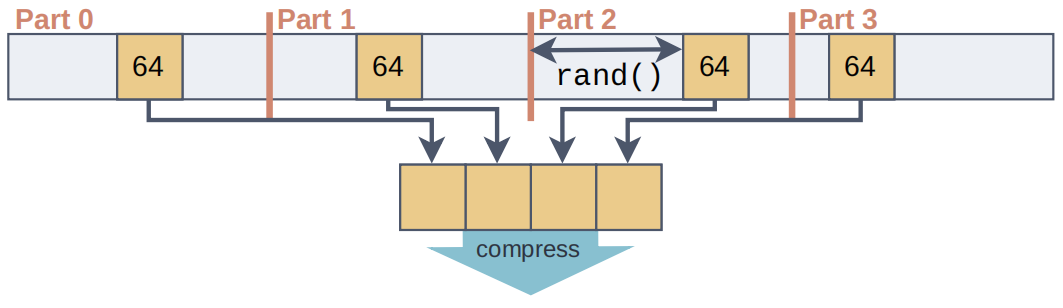
图1 从一个列块中选择一个随机的样本
估计压缩比。BtrBlocks首先通过一次遍历收集诸如𝑚𝑖𝑛、𝑚𝑎𝑥、唯一计数和平均运行长度等统计数据。基于这些统计数据,然后应用启发式方法来排除不可行的方案。然后,BtrBlocks使用每个可行的编码方案对样本进行压缩,以估计每个方案的压缩比。
3.2 级联
递归应用方案。在选择了一个压缩算法之后,压缩后的数据(或其中的一部分)可能会使用不同的方案进行压缩。如图所示,递归点表示额外的可能压缩步骤。用于额外步骤的方案再次使用我们的压缩比估算算法进行选择。递归的最大次数默认为3。一旦达到这个递归深度,BtrBlocks 将不再进行压缩。
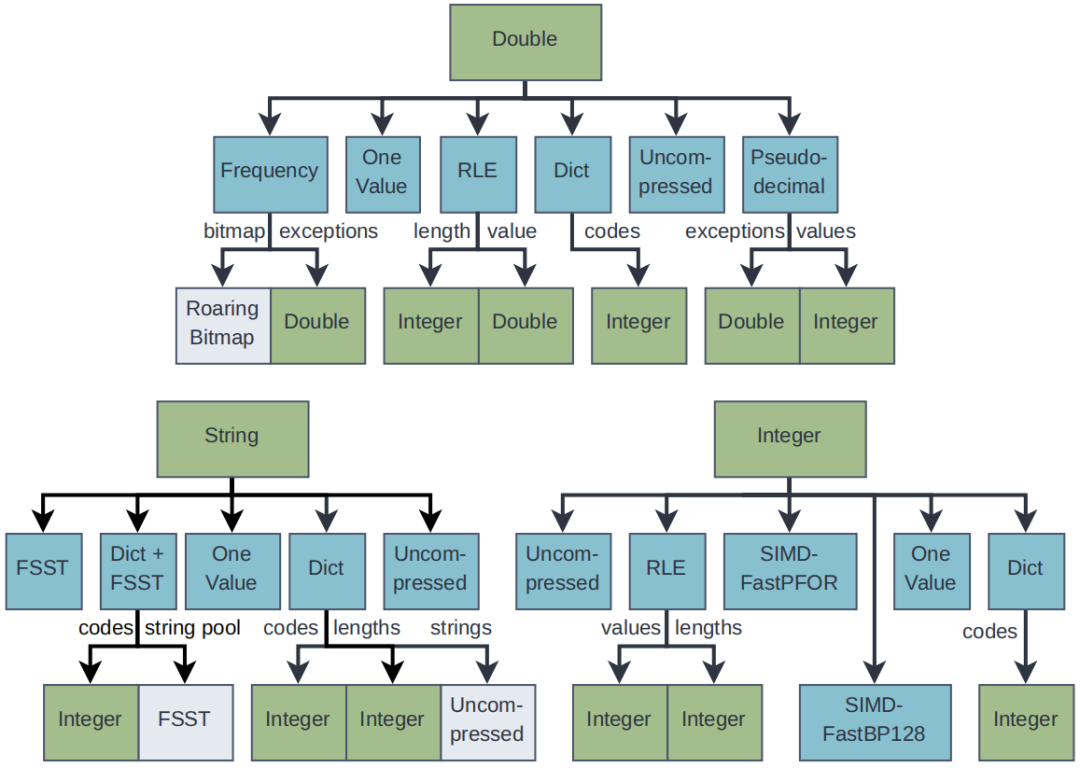
图2 递归应用的编码方案决策树
编码方案池。结果是一个通用的、可扩展的级联压缩框架,它从任意编码方案的池中进行选择。方案池显著影响BtrBlocks的整体效果:有了更多的方案,压缩速度变慢,因为需要评估更多的样本,但压缩比增加。添加更多的重型方案可能也会提高压缩比,但减慢解压缩速度。
意思就是说,D,S,I等三种类型是可以继续压缩的,在递归中会遇到不可压缩的,为递归终点,以及递归深度超过3时,自动终止
四. 伪十进制编码
过去对关系型数据库中浮点压缩的研究非常少。这有一个历史原因:关系系统通常将实数表示为小数或数值,可以物理地存储为整数。然而,随着数据湖的转移以及随后与非关系系统的集成,这种情况正在改变,例如,Tableau的内部分析DBMS将所有实数编码为浮点数,而机器学习系统几乎完全依赖浮点数。
文章设计了一种专门为二进制浮点数设计的压缩方案,即伪十进制编码(Pseudodecimal Encoding)。
4.1 压缩浮点数
挑战:1)物理上的IEEE 754表示,导致许多压缩方法不适合;2)一些十进制数,不能用二进制精确表示,如0.99实际存储的值是0.98999...。
浮点数表示为整数元组。伪十进制编码使用十进制表示法对双精度浮点数进行编码。它使用两个整数进行表示:带符号的有效数字和指数。例如,3.25变为(+325, 2),就像325 × 10^(-2)一样;对于0.99只需要存(99, 2)而不用存(98999...,17)。
算法细节。伪十进制编码算法通过测试所有10的幂并检查它们是否正确地将双精度浮点数乘以一个整数值来确定紧凑的十进制表示。首先在一个静态表中存储10的幂的倒数,以避免为每个数字重新计算它们。其次为解决-0、lnf和NaN问题,算法将其作为补丁存储。同时将数字和指数的位数限制为32和5。这些属性确保编码比特位相同。
4.2 BtrBlocks中的伪十进制编码
级联到整数编码方案。伪十进制编码将一个浮点数列转换为两个整数列和一个小的异常列。BtrBlocks可能会再次使用级联压缩对这些列进行编码:
图3 伪十进制编码示例
图中所示的级联压缩选择只是示例,而不是固定的;BtrBlocks使用其先前描述的采样算法来选择方案。
何时使用伪十进制编码。有些数据不适合使用伪十进制编码,比如包含许多异常值的列:伪十进制编码略微提高了压缩比,但由于存在许多异常值,解压缩速度较慢。因此,BtrBlocks对那些具有超过50%不可编码异常值的列禁用该方案。同样,具有很少唯一值的列通常使用字典几乎可以实现同样好的压缩效果,而字典具有更高的解压缩速度。因此,在BtrBlocks的上下文中,选择在具有少于10%唯一值的列中排除伪十进制编码。
RLE代码
import java.util.*;public class Main {private static List<Map.Entry<Integer, Integer>> RLE(int[] nums) {if (nums == null || nums.length == 0) {return new ArrayList<>();}List<Map.Entry<Integer, Integer>> result = new ArrayList<>();int count = 1;for (int i = 1; i < nums.length; i++) {if (nums[i] == nums[i - 1]) {count++;} else {result.add(new AbstractMap.SimpleEntry<>(nums[i - 1], count));count = 1;}}result.add(new AbstractMap.SimpleEntry<>(nums[nums.length - 1], count));return result;}public static void main(String[] args) {int[] nums = {11, 11, 10, 999, 999, 999};List<Map.Entry<Integer, Integer>> encoding = RLE(nums);for (Map.Entry<Integer, Integer> entry : encoding) {System.out.println("(" + entry.getKey() + "," + entry.getValue() + ")");}}
}这篇关于12.10多种编码方式,编码方案选择策略(递归级联),PDE,RLE代码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




