本文主要是介绍【LSM tree 】Log-structured merge-tree 一种分层、有序、面向磁盘的数据结构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 基本原理
- 读写流程
- 写流程
- 读流程
- 写放大、读放大和空间放大
- 优化
前言
LSM Tree 全称是Log-structured merge-tree, 是一种分层,有序,面向磁盘的数据结构。其核心原理是磁盘批量顺序写比随机写性能高很多,可以通过围绕这一原理进行设计和优化,让写性能达到最优。相较于传统的B+树,它减少了磁盘随机读取的需求,从而在一定程度上改善了数据库的写能力,当然在一定程度上牺牲了数据库的读能力。LSM tree也是当今流行的各种NoSQL或NewSQL数据库最基础的底层数据结构,广泛使用在包括Hbase,Cassandra,Leveldb, RocksDB, TiDB等项目中。
基本原理
传统的B+树的缺陷就是在访问节点时涉及到了大量的磁盘随机读写,因为你无法保证节点常驻内存,尤其是当B+树管理的索引量很大的时候,这导致数据库读写性能急剧下降。
LSM tree 采取的做法就是通过引入多部件索引来减少磁盘随机读写的需求。在大量插入情况下我们周期性地选取两部分索引进行合并,并且把合并后的有序文件(或内存块)添加到磁盘尾部(或成为新文件),修改节点信息以保证索引树的正确和完善,并且周期性地回收失效索引。因此与其说LSM tree是一种树,不如说它是通过传统索引组织有序文件或内存块的一种方式。
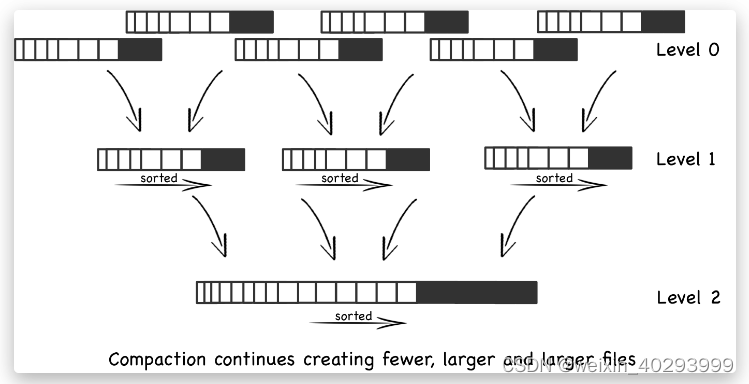
LSM tree的节点可以分为两种:
- MemTable: 保存在内存中的部分,一般可以是红黑树、跳跃表,甚至可以是B树。在HBase中使用的是跳表,在SQLite4中使用的是只能追加写入的红黑树。
- SSTable: 保存在磁盘上的部分,一般由多个内部KeyValue有序的文件组成,它的key和value都是任意的字节数组,并且了提供了按指定key查找和指定范围dekey区间迭代遍历的功能。SSTable内部包含了系列可匹配大小的Block块。关于这些Block块的index存储在SSTable的尾部,用于帮助快速查找。
写操作直接作用于MemTable,因此写入性能接近写内存。每层SSTable文件到达一定条件后,进行合并操作,然后放置到更高层。合并操作在实现上一般的策略驱动、可插件化的。
读写流程
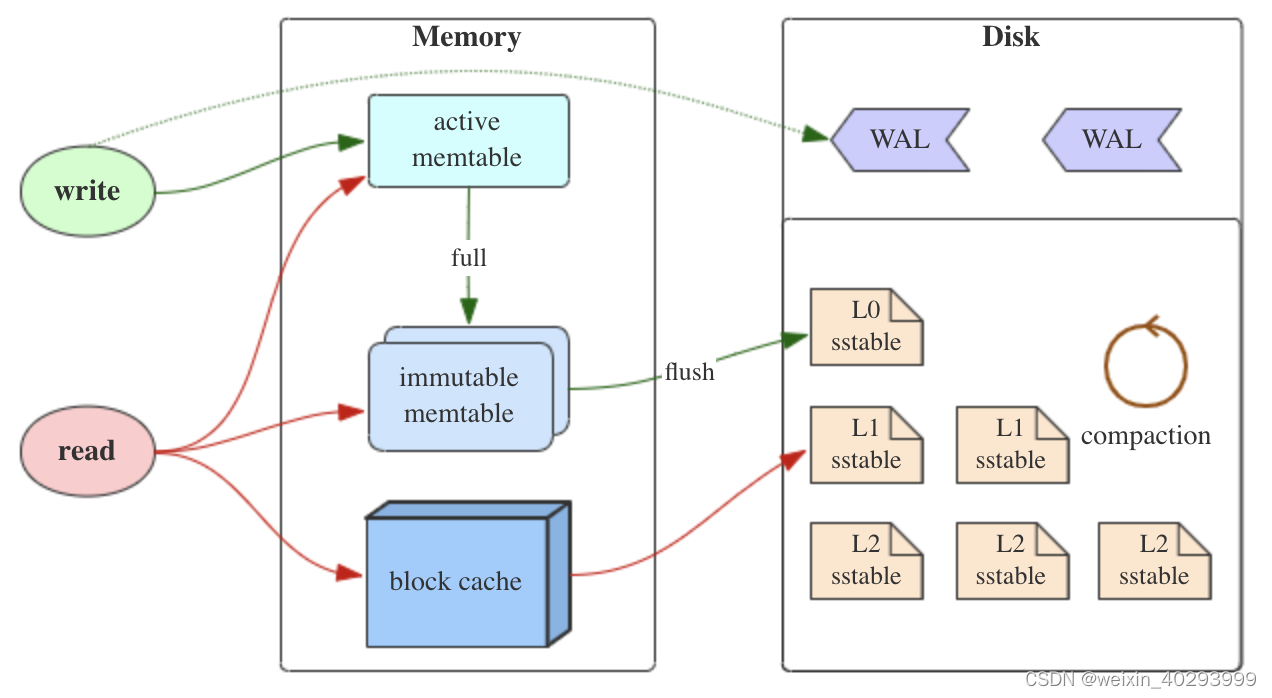
写流程
- 当收到一个写请求时,会先把该条数据记录在 WAL(Write-ahead logging)里面,用作故障恢复。
- 当写完 WAL 后,会把该条数据写入内存的 MemTable 里面(删除操作也通过写入实现,会写入一个删除标记;更新则是写入一条新记录)。
- 当 Memtable 超过一定的大小后,会在内存里面冻结,变成不可变的 Memtable,同时为了不阻塞写操作需要新生成一个 Memtable 继续提供服务。
- 把内存里面不可变的 Memtable 给 flush 到到硬盘上的 SSTable 层中,此步骤也称为 Minor Compaction,这里需要注意在 L0 层的 SSTable 是没有进行合并的,所以这里的 key range 在多个 SSTable 中可能会出现重叠,在层数大于 0 层之后的 SSTable,不存在重叠 key。
- 当每层的磁盘上的 SSTable 的体积超过一定的大小或者个数,也会周期的进行合并。此步骤也称为 Major Compaction。这个阶段会真正的清除掉被标记删除掉的数据以及多版本数据的合并,避免浪费空间,注意由于 SSTable 都是有序的,我们可以直接采用 merge sort 进行高效合并。
读流程
- 当收到一个读请求的时候,会直接先在内存里面查询,如果查询到就返回。
- 内存查询包括服务中的 Memtable 和不可变的 Memtable,也包括对于 SSTable 的缓存 block cache。
- 如果内存中没有查询到就会依次下沉查询 SSTable,直到把所有的层次的 SSTable 查询一遍得到最终结果。
写放大、读放大和空间放大
LSM Tree 将随机写转化为顺序写,而作为代价带来了大量的重复写入。由此会引起写放大、读放大和空间放大。
- 写放大(Write Amplification):
平均写入 1 个字节,引擎中在数据的声明周期内实际会写入 n 个字节,其写放大率是 n。如果业务方写入速度是 10MB/s,在引擎端或者操作系统层面能观察到的数据写入速度是 30MB/s,系统的写放大率就是 3。写放大过大会制约系统的实际吞吐。对于 SSD 来说,也会导致 SSD 寿命缩短。
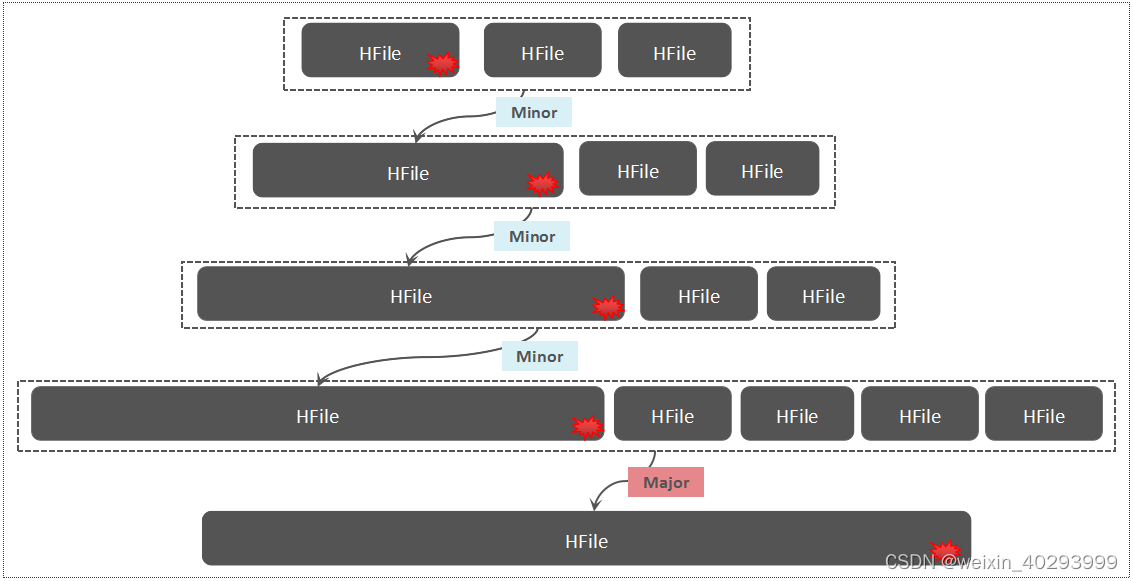
以下是 HBase 中的写放大示意图
- 读放大(Read Amplification):
一个读请求,系统所需要读 n 个页面来完成查询,其读放大率是 n。逻辑上的读操作可能会命中引擎内部的 cache 或者文件系统 cache,命中不了 cache 就会进行实际的磁盘 IO,命中 cache 的读取操作的代价虽然很低,但是也会消耗 CPU。
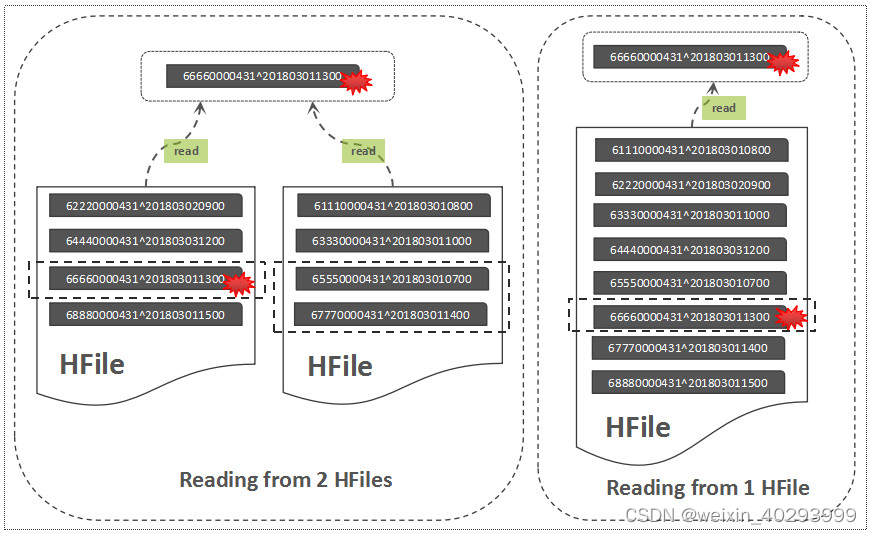
以下是 HBase 中的读放大示意图
- 空间放大(Space Amplification):
平均存储 1 个字节的数据,在存储引擎内部所占用的磁盘空间 n 个字节,其空间放大是 n。比如写入 10MB 的数据,磁盘上实际占用了 100MB,这是空间放大率就是 10。空间放大和写放大在调优的时候往往是排斥的,空间放大越大,那么数据可能不需要频繁的 compaction,其写放大就会降低;如果空间放大率设置的小,那么数据就需要频繁的 compaction 来释放存储空间,导致写放大增大
优化
LSM tree 一般从以下几个方面进行优化:
- 压缩
SSTable 是可以启用压缩功能的,并且这种压缩不是将整个 SSTable 一起压缩,而是根据 locality 将数据分组,每个组分别压缩,这样的好处当读取数据的时候,我们不需要解压缩整个文件而是解压缩部分 Group 就可以读取。
- 缓存
因为 SSTable 在写入磁盘后,除了 Compaction 之外,是不会变化的,所以我可以将 Scan 的 Block 进行缓存,从而提高检索的效率。
- Bloom filter
正常情况下,一个读操作是需要读取所有的 SSTable 将结果合并后返回的,但是对于某些 key 而言,有些 SSTable 是根本不包含对应数据的,因此,我们可以对每一个 SSTable 添加 Bloom Filter,因为 Bloom Filter 在判断一个 SSTable 不存在某个 key 的时候,那么就一定不会存在,利用这个特性可以减少不必要的磁盘扫描。
- 合并
通过定期合并瘦身, 可以有效的清除无效数据,缩短读取路径,提高磁盘利用空间。但 Compaction 操作是非常消耗 CPU 和磁盘 IO 的,尤其是在业务高峰期,如果发生了 Major Compaction,则会降低整个系统的吞吐量,这也是在使用一些 NoSQL 数据库时,比如 Hbase,常常会禁用 Major Compaction,并在凌晨业务低峰期进行合并的原因。
ref:https://popesaga.github.io/2020/09/25/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%92%8C%E7%AE%97%E6%B3%95%EF%BC%9ALSM%20tree/#%E5%86%99%E6%94%BE%E5%A4%A7%E3%80%81%E8%AF%BB%E6%94%BE%E5%A4%A7%E5%92%8C%E7%A9%BA%E9%97%B4%E6%94%BE%E5%A4%A7
这篇关于【LSM tree 】Log-structured merge-tree 一种分层、有序、面向磁盘的数据结构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








