本文主要是介绍大创项目推荐 医学大数据分析 - 心血管疾病分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1 前言
- 1 课题背景
- 2 数据处理
- 3 数据可视化
- 4 最后
1 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 基于大数据的心血管疾病分析
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题背景
本项目的任务是利用患者的检查结果预测心血管疾病(CVD)的存在与否。
2 数据处理
数据集包括年龄、性别、收缩压、舒张压等12个特征的患者数据记录7万份。
当患者有心血管疾病时,目标类“cardio”等于1,如果患者健康,则为0。
数据描述
有三种类型的输入特征:
- Objective: 客观事实;
- Examination: 体检检查结果;
- Subjective: 病人提供的信息
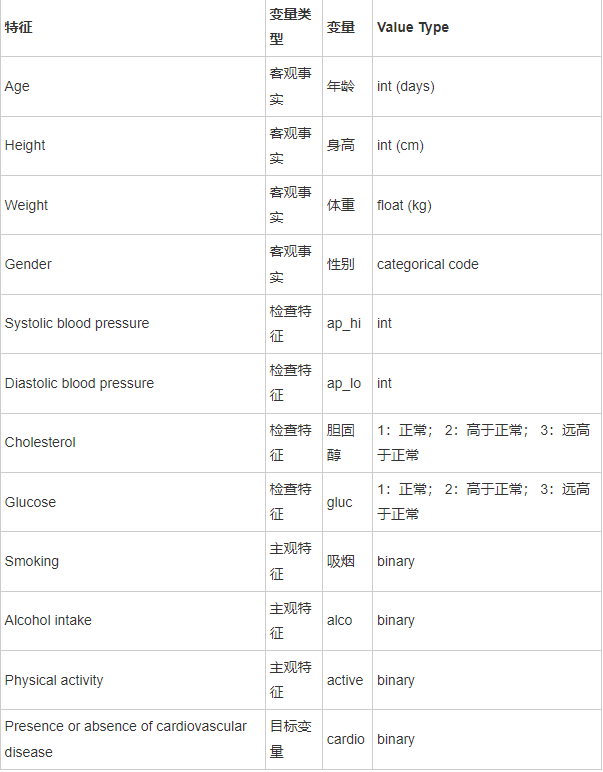
数据信息概览
import numpy as npimport pandas as pdimport seaborn as snsfrom matplotlib import pyplot as pltimport osdf.head()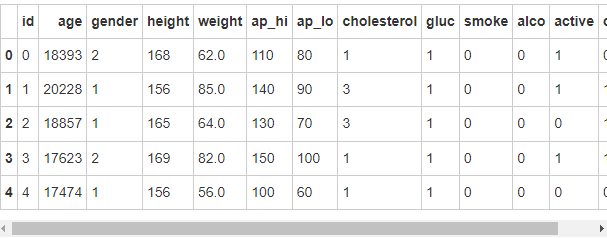
变量分析
df.info()
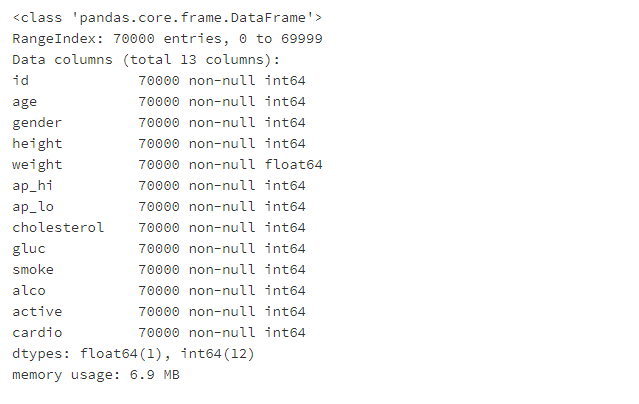
所有特征都是数字,12个整数和1个小数(权值)。第二列告诉我们数据集有多大,每个字段有多少非空值。
我们可以使用’ describe() ‘来显示每个属性的样本统计信息,比如’ min ‘、’ max ‘、’ mean ‘、’ std ':
评论
df.describe()
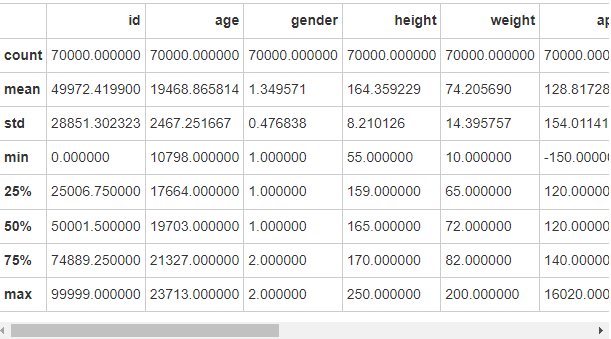
年龄以天为单位,身高以厘米为单位。
让我们看看数值变量以及它们是如何在目标类中分布的。
例如,什么年龄患有心血管疾病的人数超过没有心血管疾病的人数?
3 数据可视化
from matplotlib import rcParams
rcParams['figure.figsize'] = 11, 8
df['years'] = (df['age'] / 365).round().astype('int')
sns.countplot(x='years', hue='cardio', data = df, palette="Set2");
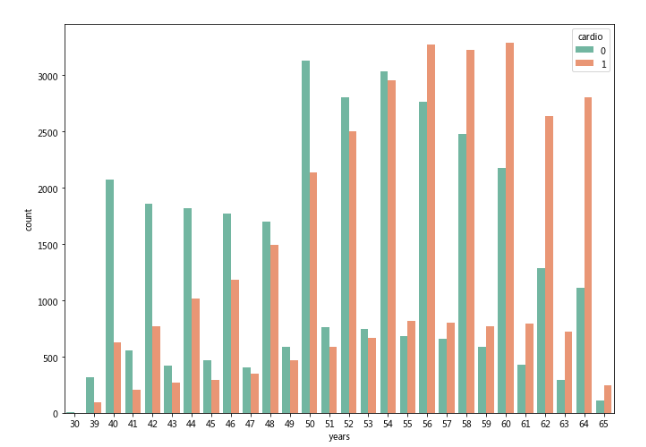
可以观察到55岁以上的人更容易得心血管疾病的。
从上面的表格中,我们可以看到ap_hi, ap_lo, weight 和height中有异常值。我们以后再处理。
让我们看看数据集中的分类变量及其分布:
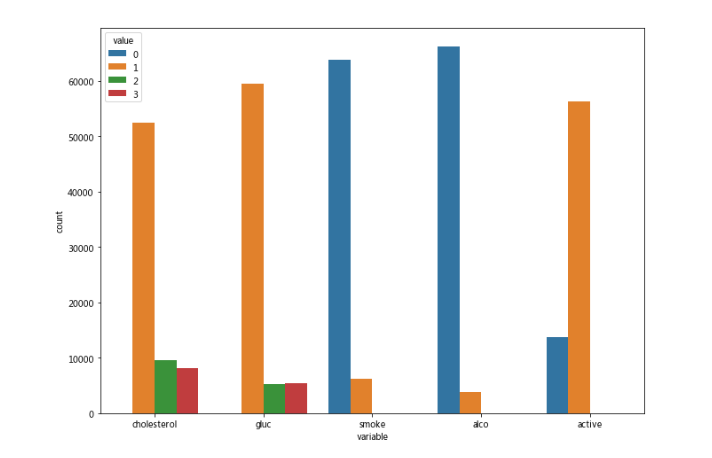
df_categorical = df.loc[:,['cholesterol','gluc', 'smoke', 'alco', 'active']]
sns.countplot(x="variable", hue="value",data= pd.melt(df_categorical));
df_long = pd.melt(df, id_vars=['cardio'], value_vars=['cholesterol','gluc', 'smoke', 'alco', 'active'])
sns.catplot(x="variable", hue="value", col="cardio",data=df_long, kind="count");
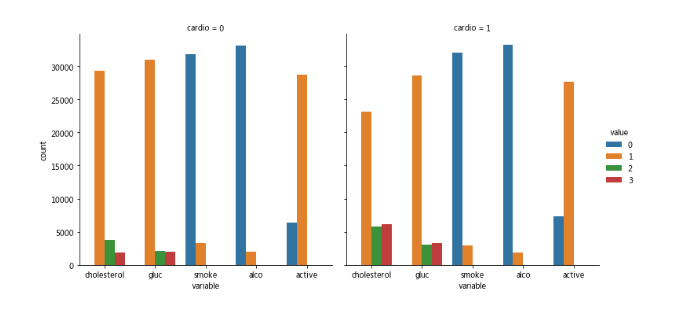
可以清楚地看到,CVD患者的胆固醇和血糖水平较高。而且一般来说不太活跃,运动少。
为了计算“1”在性别栏中代表女性还是男性,让我们计算每个性别的身高平均值。我们假设男人平均比女人高。
corr = df.corr()
cmap = sns.diverging_palette(220, 10, as_cmap=True)
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True# 设置matplotlib图
f, ax = plt.subplots(figsize=(11, 9))
# 画出热图,并校正长宽比
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,annot = True,square=True, linewidths=.5, cbar_kws={"shrink": .5});
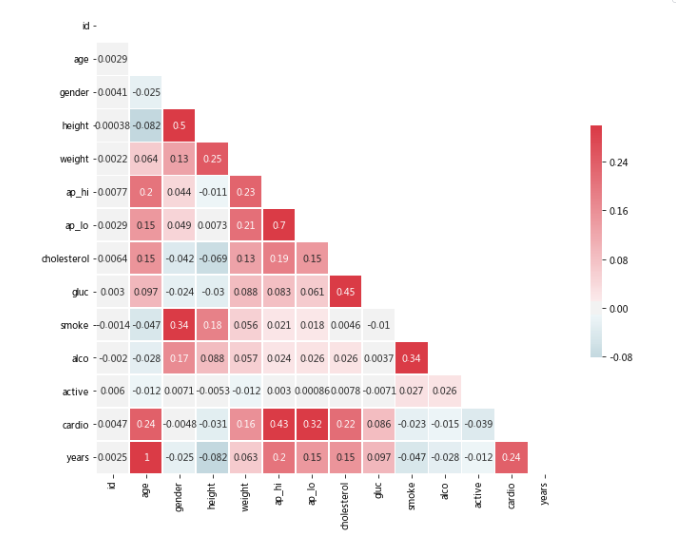
我们可以看到年龄和胆固醇有显著的影响,但与目标阶层的相关性不是很高。
.
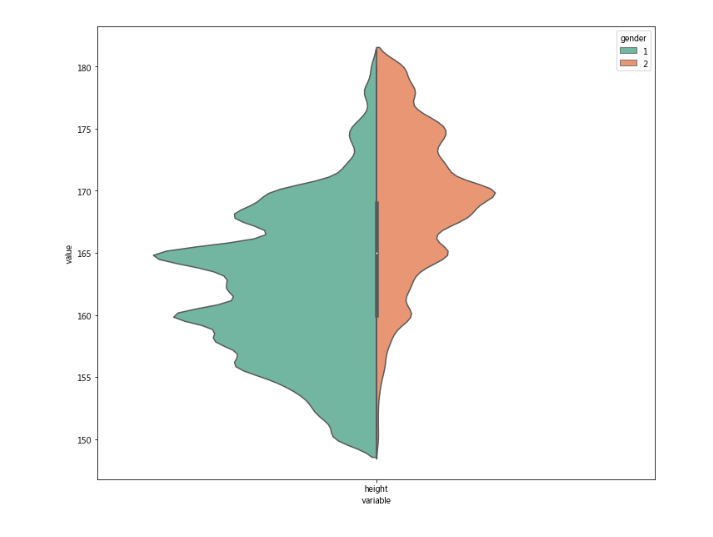
让我们创建violinplot来显示不同性别的身高分布。
查看每个性别特征值的身高和体重的平均值可能不足以决定1是男性还是女性。
import warnings
warnings.filterwarnings("ignore")
df_melt = pd.melt(frame=df, value_vars=['height'], id_vars=['gender'])
plt.figure(figsize=(12, 10))
ax = sns.violinplot(x='variable', y='value', hue='gender', split=True, data=df_melt, scale='count',scale_hue=False,palette="Set2");
让我们创造一个新的特征-身体质量指数(BMI):

比较健康人的平均BMI和病人的平均BMI。正常的BMI值在18.5到25之间。
df['BMI'] = df['weight']/((df['height']/100)**2)
sns.catplot(x="gender", y="BMI", hue="alco", col="cardio", data=df, color = "yellow",kind="box", height=10, aspect=.7);
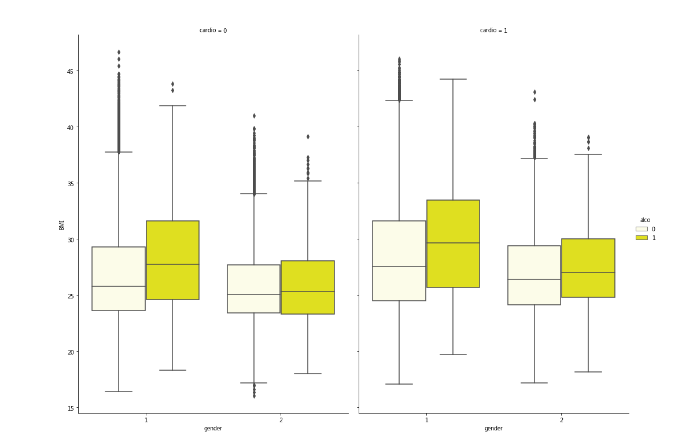
根据女性的BMI,喝酒的女性比喝酒的男性有更高的心血管疾病风险。
4 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
这篇关于大创项目推荐 医学大数据分析 - 心血管疾病分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







