本文主要是介绍【Linux系统化学习】进程地址空间 | 虚拟地址和物理地址的关系,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
=========================================================================
个人主页点击直达:小白不是程序媛
Linux专栏:Linux系统化学习
代码仓库:Gitee
=========================================================================
目录
虚拟地址和物理地址
页表
进程地址空间
进程地址空间存在的意义
虚拟地址和物理地址
我们在学习C/C++的时候肯定都见过下面这张有关于内存分布的图片:
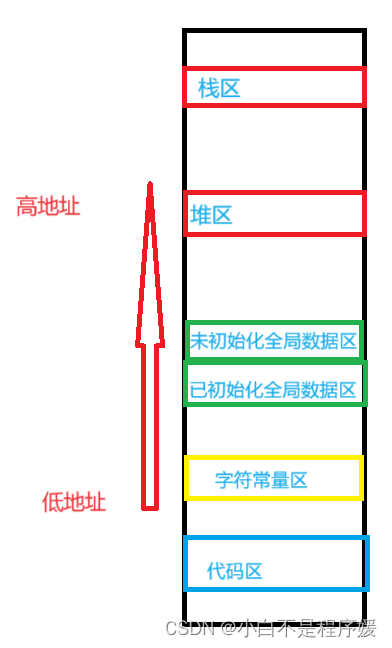
在来段代码理解感受下:
1 #include<stdio.h>2 #include<stdlib.h>3 //未初始化常量4 int un_gval;5 //初始化常量6 int init_gval=100;7 int main()8 {9 //代码区地址10 printf("code addr: %p\n",main);11 //字符常量12 const char *str="hellolinux!";13 14 //常量区地址15 printf("read only char addr : %p\n",str);16 //已初始化全局数据区17 printf("init global value addr: %p\n",&init_gval);18 //未初始化全局数据区19 printf("uninit global value addr: %p\n",&un_gval);20 21 char *heap1=(char*)malloc(100);22 char *heap2=(char*)malloc(100);23 char *heap3=(char*)malloc(100);24 char *heap4=(char*)malloc(100);25 static int a=0;26 printf("heap1 addr:%p\n",heap1); 27 printf("heap2 addr:%p\n",heap2);28 printf("heap3 addr:%p\n",heap3);29 printf("heap4 addr:%p\n",heap4);30 31 printf("stack addr:%p\n",&str);32 printf("stack addr:%p\n",&heap1);33 printf("stack addr:%p\n",&heap2);34 printf("stack addr:%p\n",&heap3);35 printf("stack addr:%p\n",&heap4);36 printf("a addr:%p\n",&a);37 38 return 0;39 }

通过上面这段代码,我们好像不仅验证了上面的空间分布图片,而且还发现了栈区和堆区相向而生的内存开辟特点。
上两篇文章我们介绍了命令行参数和环境变量,其实这两个就储存在栈区之上的空间,来段代码验证下:
1 #include<stdio.h>
W> 2 int main(int argc , char *argv[], char *env[])3 {4 int i=0;5 printf("i addr:%p\n",&i); 6 for(;argv[i];i++)7 {8 printf("argv[%d]:%p\n",i,argv[i]);9 }10 for(i=0;env[i];i++)11 {12 printf("env[%d]:%p\n",i,env[i]);13 }14 return 0;15 }~

验证完这些,话说回来其实我们之前学的对内存的概念就上面所介绍的内容其实都不是真正意义上的内存是虚拟内存,不是我们真正意义上的内存物理地址。
1 #include<stdio.h>2 #include<unistd.h>3 #include<stdlib.h> 4 int g_val = 100;5 6 int main()7 {8 pid_t id = fork();9 if(id == 0)10 {11 //child12 int cnt = 5;13 while(1)14 {15 printf("child, Pid: %d, Ppid: %d, g_val: %d, &g_val=%p\n", getpid(), getppid(), g_val, &g_val);16 sleep(1);17 if(cnt == 0)18 {19 g_val=200;20 printf("child change g_val: 100->200\n");21 }22 cnt--;23 }24 }25 else26 {27 //father28 while(1)29 {30 printf("father, Pid: %d, Ppid: %d, g_val: %d, &g_val=%p\n", getpid(), getppid(), g_val, &g_val);31 sleep(1);32 }33 }34 35 sleep(100);36 return 0;37 }
我们发现,父子进程,输出地址是一致的,但是变量内容不一样!能得出如下结论:
- 变量内容不一样,所以父子进程输出的变量绝对不是同一个变量
- 但地址值是一样的,说明,该地址绝对不是物理地址!
- 在Linux地址下,这种地址叫做 虚拟地址
- 我们在用C/C++语言所看到的地址,全部都是虚拟地址!物理地址,用户一概看不到,由OS统一管理OS必须负责将 虚拟地址 转化成 物理地址
我们再将同一个可执行程序同时运行也会发现两个进程的获取到的地址竟然也是一样的。
 话又说回来,我们的可执行程序运行时肯定会加载到内存中,因此虚拟地址和物理地址一定有关联,这个关联就是页表。
话又说回来,我们的可执行程序运行时肯定会加载到内存中,因此虚拟地址和物理地址一定有关联,这个关联就是页表。
页表
页表就是将虚拟地址和物理地址联系起来的一种模型,其中还包括变量是否可以被修改,进程的状态等诸多信息。
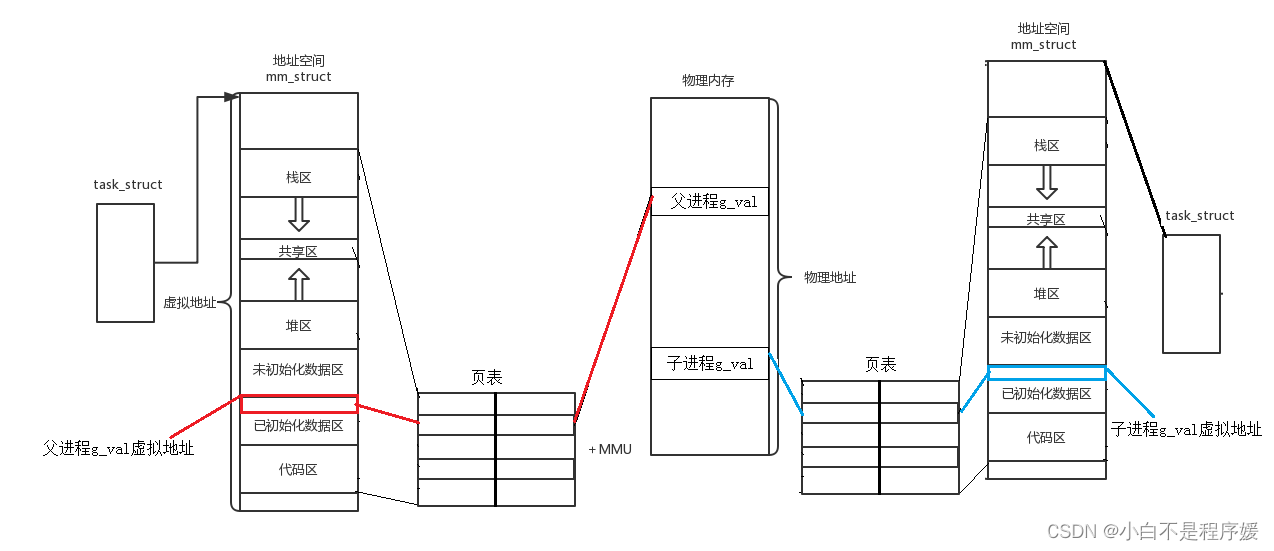
上面的图就足矣说名问题,同一个变量,地址相同,其实是虚拟地址相同,内容不同其实是被映射到了不同的物理地址!
每个进程的页表的物理地址存在与CPU中CR3的寄存器中
进程地址空间
进程地址空间其实我们可以使用内存大小的一个范围,以我们32位总线的机器为例:它的范围为0000 0000 -> ffff ffff ,也就是0到2^32次方(我们所谓的4GB)。模拟其物理空间大小进行区域划分后形成栈区、堆区等等的虚拟地址,操作系统通过结构体将每个区域的起始和结束统计记录起来,进程的PCB中含有指向这个结构体的指针。
因此,每当新的进程创建时会形成对应的PCB,PCB和PCB中的虚拟地址结构体指针和页表关联起来,对真正上的物理地址进行使用。
进程地址空间存在的意义
- 让进程以统一的视角看待内存,所以任意一个进程,可以通过地址空间和页表可以将乱序的内存数据,变成有序,分门别类的规划好
- 存在虚拟地址空间,可以有效的进行进程访问内存的安全检查
- 将进程管理和内存管理进行解耦,通过页表让进程映射到不同的物理内存处,从而实现进程的独立性。
今天对Linux下进程地址空间的介绍分享到这就结束了,希望大家读完后有很大的收获,也可以在评论区点评文章中的内容和分享自己的看法。您三连的支持就是我前进的动力,感谢大家的支持!!!
这篇关于【Linux系统化学习】进程地址空间 | 虚拟地址和物理地址的关系的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



