本文主要是介绍ubuntu64位hadoop2.2.0全分布安装部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、安装完ubuntu系统后,激活root账户
sudo passwd root(参考网址:http://www.aboutyun.com/blog-61-121.html)
2、增加用户
用命令sudo adduser aboutyun
(注:ubuntu建用户最好用adduser,虽然adduser和useradd是一样的在别的linux糸统下,但是我在ubuntu下用useradd时,参考网址:http://www.aboutyun.com/blog-61-121.html)
两次输入aboutyun的初始密码123456,出现的信息如下
passwd: password updated successfullyChanging the user information for aboutyunEnter the new value, or press ENTER for the defaultFull Name []:Room Number []:Work Phone []:Home Phone []:Other []:Full Name []:这个信息是否正确? [Y/n] y
到此,用户添加成功。如果需要让此用户有root权限,执行命令:
root@ubuntu:~# sudo vim /etc/sudoers
修改文件如下:
# User privilege specificationroot ALL=(ALL) ALLaboutyun ALL=(ALL) ALL保存退出,aboutyun用户就拥有了root权限。(注:如果sudoers为只读文件,用chmod 600 /etc/sudoers命令修改文件权限)
3、搭建集群
这里我们搭建一个由三台机器组成的集群(参考网址:http://www.aboutyun.com/thread-7684-1-1.html)
192.168.0.107 aboutyun/123456 master
192.168.0.108 aboutyun/123456 slave1
172.16.77.17 aboutyun/123456 slave2
3.1 上面各列分别为IP、user/passwd、hostname
Hostname可以在/etc/hostname中修改,hostname,
对于三台机器都需要修改:
下面是master的修改:通过命令
vim /etc/hosts
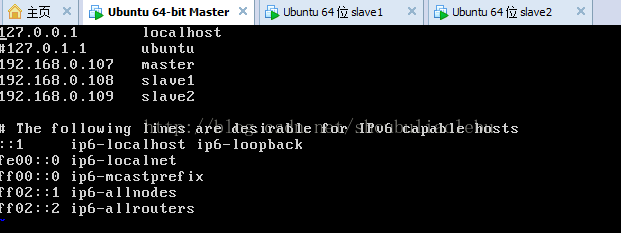
4、打通master到slave节点的SSH无密码登陆
1)、登陆root用户,运行sudo apt-get update
(2)、运行apt-get install ssh安装ssh应用
(3)、设置local无密码登陆
具体步骤如下:
第一步:产生密钥
$ ssh-keygen -t rsa -P ” -f ~/.ssh/id_rsa
输出如下:
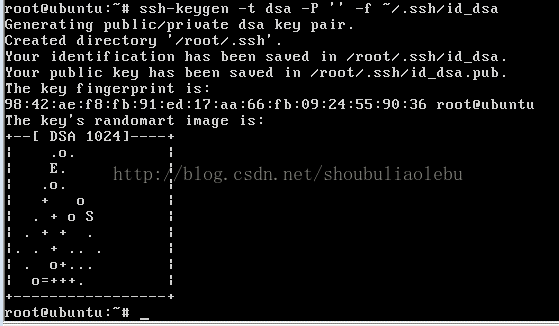
第二步:导入authorized_keys
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
第二步导入的目的是为了无密码等,这样输入如下命令:
ssh localhost
注:次localhost对应的是/etc/hosts中127.0.0.1 localhost一行中的对应字段
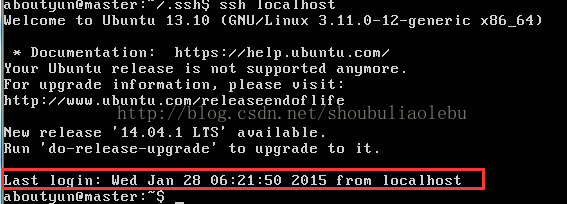
出现Last login表示登陆成功
(4)、设置远程无密码登陆
进入master的.ssh目录
scp authorized_keys aboutyun@slave1:~/.ssh/authorized_keys_from_master
进入slave1的.ssh目录
cat authorized_keys_from_master >> authorized_keys
至此,可以在master上面ssh slave1进行无密码登陆了(注意:是master访问slave1,不是slave1访问master)。
【注意】:以上操作在每台机器上面都要进行。
(5)、这里在强调一下原理:
就是把工钥放到里面,然后本台机器就可以ssh无密码登录了。如果想彼此无密码登录,那么就需要把彼此的工钥(*.pub)放到authorized_keys里面
如果想要理解上述操作,请参考网址(http://www.educity.cn/net/1620180.html)
下面有三篇好文章讲解rsa和dsa密钥管理只是,可以看一下哦,人家讲解的通俗易懂,考虑的又比较全面:
http://www.ibm.com/developerworks/cn/linux/security/openssh/part1/index.html
http://www.ibm.com/developerworks/cn/linux/security/openssh/part2/index.html
http://www.ibm.com/developerworks/cn/linux/security/openssh/part3/index.html
如果建立权限不成功可参考以下此网址(http://digdeeply.org/archives/06142220.html和http://jiajun.iteye.com/blog/621309)
5、安装jdk
(1)解压安装
sudo mkdir /usr/lib/jvm
sudo tar zxvf ./jdk-7-linux-x64.tar.gz -C /usr/lib/jvm
cd /usr/lib/jvm
sudo mv jdk1.7.0 java
(2)修改环境变量
vim ~/.bashrc在最下边增加以下代码
export JAVA_HOME=/usr/lib/jvm/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
(3)配置默认JDK版本
由于ubuntu中可能会有默认的JDK,如openjdk,所以,为了将我们安装的JDK设置为默认JDK版本,还要进行如下工作。
执行代码:
sudo update-alternatives --install /usr/bin/java java /usr/lib/jvm/java/bin/java 300sudo update-alternatives --install /usr/bin/javac javac /usr/lib/jvm/java/bin/javac 300sudo update-alternatives --install /usr/bin/jar jar /usr/lib/jvm/java/bin/jar 300sudo update-alternatives --install /usr/bin/javah javah /usr/lib/jvm/java/bin/javah 300sudo update-alternatives --install /usr/bin/javap javap /usr/lib/jvm/java/bin/javap 300
(4)测试
$ java -versionjava version "1.7.0"Java(TM) SE Runtime Environment (build 1.7.0-b147)Java HotSpot(TM) Server VM (build 21.0-b17, mixed mode)(5)关闭每台机器的防火墙
ufw disable (重启生效)
6、安装和配置主hadoop
(参考网址:http://www.aboutyun.com/thread-7684-1-1.html)
(1)、 解压文件
将第一部分中下载的
执行代码:
tar zxvf hadoop-2.2.0_x64.tar.gz
mv hadoop-2.2.0 /usr/hadoop(2)、hadoop配置过程
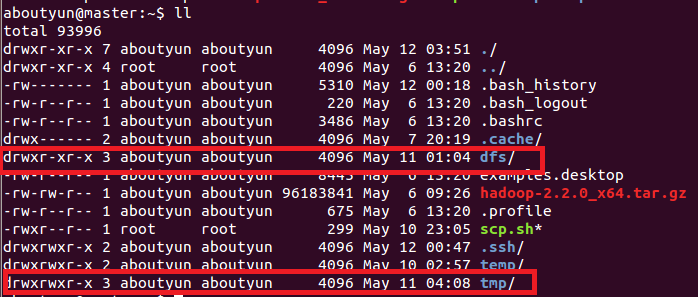
配置之前,需要在master本地文件系统创建以下文件夹:
~/dfs/name
~/dfs/data
~/tmp
这里文件权限:创建完毕,你会看到红线部分,注意所属用户及用户组。
配置文件1:hadoop-env.sh
修改JAVA_HOME值(export JAVA_HOME=/usr/lib/jvm/java)
配置文件2:yarn-env.sh
修改JAVA_HOME值(export JAVA_HOME=/usr/lib/jvm/java)
配置文件3:slaves (这个文件里面保存所有slave节点)
写入以下内容:
slave1
slave2配置文件4:core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://master:8020</value></property><property><name>io.file.buffer.size</name><value>131072</value></property><property><name>hadoop.tmp.dir</name><value>file:/home/aboutyun/tmp</value><description>Abase for other temporary directories.</description></property><property><name>hadoop.proxyuser.aboutyun.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.aboutyun.groups</name><value>*</value></property>
</configuration>
配置文件5:hdfs-site.xml
<configuration><property><name>dfs.namenode.secondary.http-address</name><value>master:9001</value></property><property><name>dfs.namenode.name.dir</name><value>file:/home/aboutyun/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/home/aboutyun/dfs/data</value></property><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.webhdfs.enabled</name><value>true</value></property>
</configuration>配置文件6:mapred-site.xml
<configuration><property> <name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property>
</configuration>配置文件7:yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.resourcemanager.address</name><value>master:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>master:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>master:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>master:8033</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>master:8088</value></property>
</configuration>7、复制到其他节点
上面配置完毕,我们基本上完成了90%了剩下就是复制。我们可以把整个hadoop复制过去:使用如下命令:
sudo scp -r /usr/hadoop aboutyun@slave1:~/
这里记得先复制到home/aboutyun下面,然后在转移到/usr下面。
后面我们会经常遇到问题,经常修改配置文件,所以修改完一个配置文件后,其他节点都需要修改,这里附上脚本操作方便:
一、节点之间传递数据:
第一步:vi scp.sh
第二步:把下面内容放到里面
#!/bin/bash
#slave1
scp /usr/hadoop/etc/hadoop/core-site.xml aboutyun@slave1:~/
scp /usr/hadoop/etc/hadoop/hdfs-site.xml aboutyun@slave1:~/ #slave2
scp /usr/hadoop/etc/hadoop/core-site.xml aboutyun@slave2:~/
scp /usr/hadoop/etc/hadoop/hdfs-site.xml aboutyun@slave2:~/第三步:保存scp.sh
第四步:bash scp.sh执行
二、移动文件夹:
可以自己写了。
8、配置环境变量
(1)、vi ~/.bashrc
(2)、添加如下代码:
export HADOOP_HOME=/home/tom/hadoop-2.2.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin(3)、source ~/.bashrc
9、启动验证
启动hadoop(注:以下命令都只是在主节点上运行)
格式化namenode:
hdfs namenode –format
启动hdfs:
start-dfs.sh
此时在master上面运行jps命令有以下两个进程:
namenode
secondarynamenodeslave节点上面运行的进程有:datanode
启动yarn:
start-yarn.sh
我们看到如下效果:
master有如下进程:
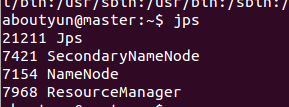
slave1有如下进程
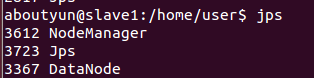
此时hadoop集群已全部配置完成!!!
【注意】:而且所有的配置文件和节点处不要有空格,否则会报错!
然后我们输入:(这里有的同学没有配置hosts,所以输出master访问不到,如果访问不到输入ip地址即可)
http://master:8088/
如何修改hosts:
win7 进入下面路径:
C:\Windows\System32\drivers\etc
找打hosts
然后打开,进行如下配置即可看到
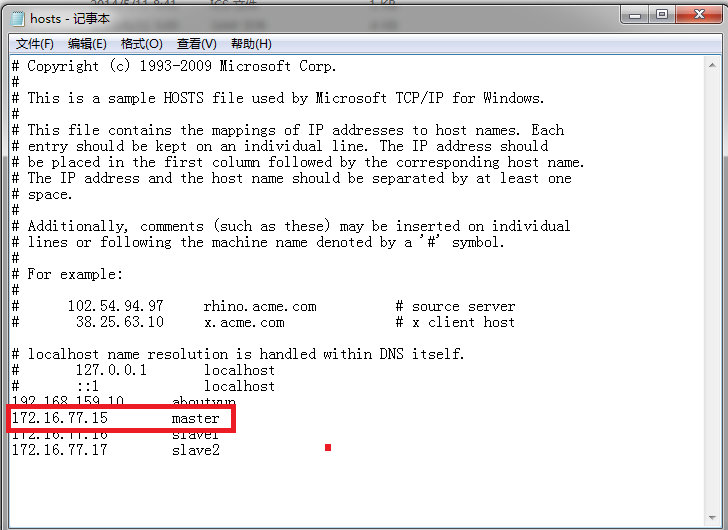
看到下图:
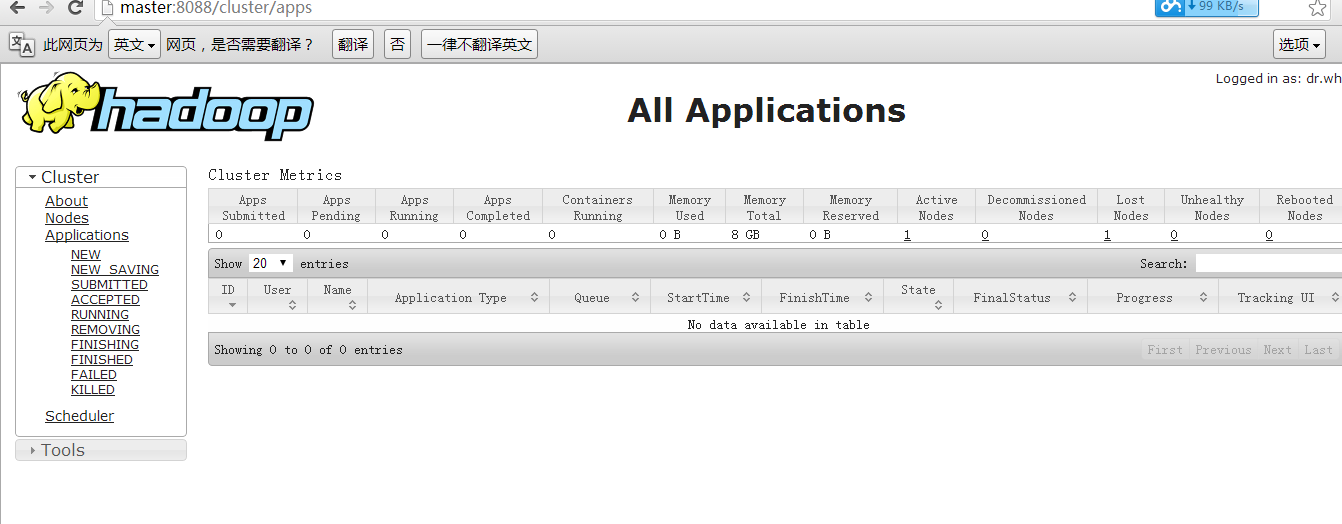
10、遇到问题
启动HDFS,命令如下:(参考网址:http://blog.csdn.net/xin_jmail/article/details/40556267)
$ sbin/start-dfs.sh
遇到如下错误:
1. 14/10/29 16:49:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2. Starting namenodes on [OpenJDK Server VM warning: You have loaded library /home/baisong/hadoop-2.5.0/lib/native/libhadoop.so.1.0.0
3. which might have disabled stack guard. The VM will try to fix the stack guard now.
4. It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
5. localhost]
6. sed: -e expression #1, char 6: unknown option to `s'
7. VM: ssh: Could not resolve hostname vm: Name or service not known
8. library: ssh: Could not resolve hostname library: Name or service not known
9. have: ssh: Could not resolve hostname have: Name or service not known
10. which: ssh: Could not resolve hostname which: Name or service not known
11. might: ssh: Could not resolve hostname might: Name or service not known
12. warning:: ssh: Could not resolve hostname warning:: Name or service not known
13. loaded: ssh: Could not resolve hostname loaded: Name or service not known
14. have: ssh: Could not resolve hostname have: Name or service not known
15. Server: ssh: Could not resolve hostname server: Name or service not known分析原因知,没有设置 HADOOP_COMMON_LIB_NATIVE_DIR和HADOOP_OPTS环境变量,在 ~/.bashrc文件中添加如下内容并编译。
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib" $ source ~/.bashrc
重新启动HDFS,输出启动成功。
这篇关于ubuntu64位hadoop2.2.0全分布安装部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







