本文主要是介绍kyuubi整合flink yarn application model,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 概述
- 配置
- flink 配置
- kyuubi 配置
- kyuubi-defaults.conf
- kyuubi-env.sh
- hive
- 验证
- 启动kyuubi
- beeline 连接
- 使用hive catalog
- sql测试
- 结束
概述
flink 版本 1.17.1、kyuubi 1.8.0、hive 3.1.3、paimon 0.5
整合过程中,需要注意对应的版本。
注意以上版本

姊妹篇 kyuubi yarn session model 整合链接在此
配置
kyuubi flink yarn application mode 官网文档
flink 配置
#jobManager 的 IP 地址
jobmanager.rpc.address: localhost#jobManager 的端口,默认为 6123
jobmanager.rpc.port: 6123#jobManager 的 JVM heap 大小,生产环境4G起步
jobmanager.heap.size: 1600m#taskManager 的 jvm heap 大小设置,低于 1024M 不能启动
taskmanager.memory.process.size: 8094m
taskmanager.memory.managed.size: 64m#taskManager 中 taskSlots 个数,最好设置成 work 节点的 CPU 个数相等
taskmanager.numberOfTaskSlots: 2#taskmanager 是否启动时管理所有的内存
taskmanager.memory.preallocate: false#并行计算数
parallelism.default: 2#控制类加载策略,可选项有 child-first(默认)和 parent-first
classloader.resolve-order: parent-first
classloader.check-leaked-classloader: falsestate.backend.incremental: true
state.backend: rocksdb
execution.checkpointing.interval: 300000
state.checkpoints.dir: hdfs://ks2p-hadoop01:9000/dinky-ckps
state.savepoints.dir: hdfs://ks2p-hadoop01:9000/dinky-savepoints
heartbeat.timeout: 180000
akka.ask.timeout: 60s
web.timeout: 5000
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
kyuubi 配置
- 官网下载:https://kyuubi.apache.org/releases.html
- kyuubi conf下三个配置文件去 template后缀
- 配置 kyuubi-defaults.conf、kyuubi-env.sh
kyuubi-defaults.conf
此处配置引擎类型, flink 的模式,这两个重要的。
kyuubi.engine.type FLINK_SQL
flink.execution.target yarn-application
kyuubi.ha.namespace kyuubi
kyuubi-env.sh
没有采用 hadoop 集群默认的配置,java 及 flink 使用的都是定制的版本。
export JAVA_HOME=/data/jdk-11.0.20
export FLINK_HOME=/data/soft/flink-1.17.1
export HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_CONF_DIR=/data/hadoop/etc/hadoop
export FLINK_HADOOP_CLASSPATH=${HADOOP_HOME}/share/hadoop/client/hadoop-client-runtime-3.2.4.jar:${HADOOP_HOME}/share/hadoop/client/hadoop-client-api-3.2.4.jar
hive
生产上 paimon 的 catlog 信息是 hive 存储的。
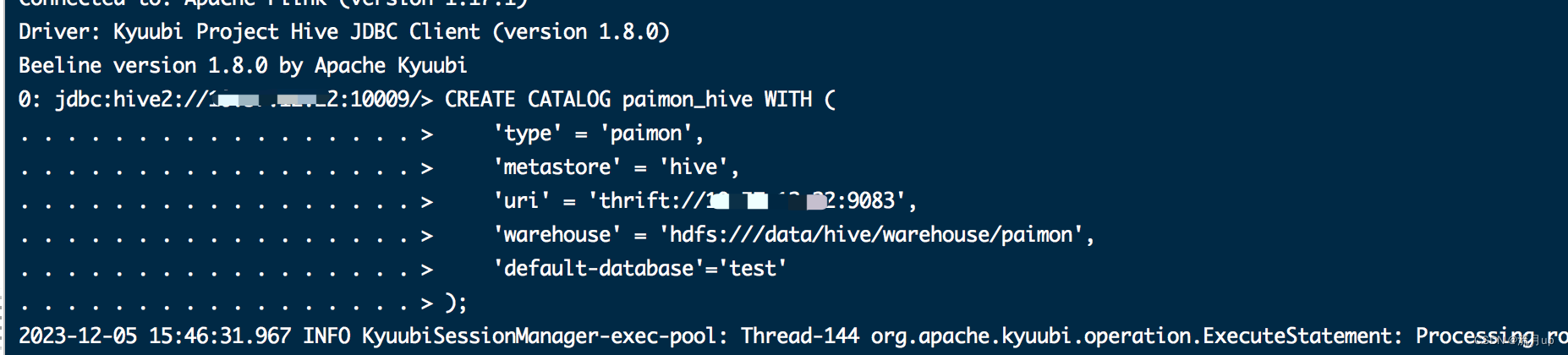
CREATE CATALOG paimon_hive WITH ('type' = 'paimon','metastore' = 'hive','uri' = 'thrift://10.xx.xx.22:9083','warehouse' = 'hdfs:///data/hive/warehouse/paimon','default-database'='test'
);USE CATALOG paimon_hive;
验证
**注意:**下面启动相应的组件,进行相关的验证。
启动kyuubi

验证一下正常启动如下:
[root@ksxx-hadoop06 apache-kyuubi-1.8.0-bin]# netstat -nlp | grep :10009
tcp 0 0 10.xx.xx.22:10009 0.0.0.0:* LISTEN 218311/java
beeline 连接
[root@ks2p-hadoop06 apache-kyuubi-1.8.0-bin]# bin/beeline -u 'jdbc:hive2://10.xx.xx.22:10009/' -n tableau
Connecting to jdbc:hive2://10.xx.xx.22:10009/
2023-12-06 10:55:48.247 INFO KyuubiSessionManager-exec-pool: Thread-138 org.apache.kyuubi.operation.LaunchEngine: Processing tableau's query[6bab2d9e-c7f5-4438-bcd7-8f1e2fd98020]: PENDING_STATE -> RUNNING_STATE, statement:
LaunchEngine
2023-12-06 10:55:48.279 WARN KyuubiSessionManager-exec-pool: Thread-138 org.apache.kyuubi.shaded.curator.utils.ZKPaths: The version of ZooKeeper being used doesn't support Container nodes. CreateMode.PERSISTENT will be used instead.
2023-12-06 10:55:48.304 INFO KyuubiSessionManager-exec-pool: Thread-138 org.apache.kyuubi.engine.ProcBuilder: Creating tableau's working directory at /data/soft/apache-kyuubi-1.8.0-bin/work/tableau
2023-12-06 10:55:48.317 INFO KyuubiSessionManager-exec-pool: Thread-138 org.apache.kyuubi.engine.EngineRef: Launching engine:
/data/soft/flink-1.17.1/bin/flink run-application -t yarn-application -Dyarn.ship-files=/data/soft/flink-1.17.1/opt/flink-sql-client-1.17.1.jar;/data/soft/flink-1.17.1/opt/flink-sql-gateway-1.17.1.jar -Dyarn.application.name=kyuubi_USER_FLINK_SQL_tableau_default_e29cfc98-f864-4bb9-a430-2d3eceeeac24 -Dyarn.tags=KYUUBI,e29cfc98-f864-4bb9-a430-2d3eceeeac24 -Dcontainerized.master.env.FLINK_CONF_DIR=. -Dexecution.target=yarn-application -c org.apache.kyuubi.engine.flink.FlinkSQLEngine /data/soft/apache-kyuubi-1.8.0-bin/externals/engines/flink/kyuubi-flink-sql-engine_2.12-1.8.0.jar \--conf kyuubi.session.user=tableau \--conf kyuubi.client.ipAddress=10.xx.xx.22 \--conf kyuubi.client.version=1.8.0 \--conf kyuubi.engine.submit.time=1701831348298 \--conf kyuubi.engine.type=FLINK_SQL \--conf kyuubi.ha.addresses=10.xx.xx.22:2181 \--conf kyuubi.ha.engine.ref.id=e29cfc98-f864-4bb9-a430-2d3eceeeac24 \--conf kyuubi.ha.namespace=/kyuubi_1.8.0_USER_FLINK_SQL/tableau/default \--conf kyuubi.ha.zookeeper.auth.type=NONE \--conf kyuubi.server.ipAddress=10.xx.xx.22 \--conf kyuubi.session.connection.url=ks2p-hadoop06:10009 \--conf kyuubi.session.real.user=tableau
2023-12-06 10:55:48.321 INFO KyuubiSessionManager-exec-pool: Thread-138 org.apache.kyuubi.engine.ProcBuilder: Logging to /data/soft/apache-kyuubi-1.8.0-bin/work/tableau/kyuubi-flink-sql-engine.log.02023-12-06 10:55:59,647 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2023-12-06 10:55:59,648 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface ks2p-hadoop06:1655 of application 'application_1694575187997_0427'.
Connected to: Apache Flink (version 1.17.1)
Driver: Kyuubi Project Hive JDBC Client (version 1.8.0)
Beeline version 1.8.0 by Apache Kyuubi
0: jdbc:hive2://10.xx.xx.22:10009/>
使用hive catalog
sql测试
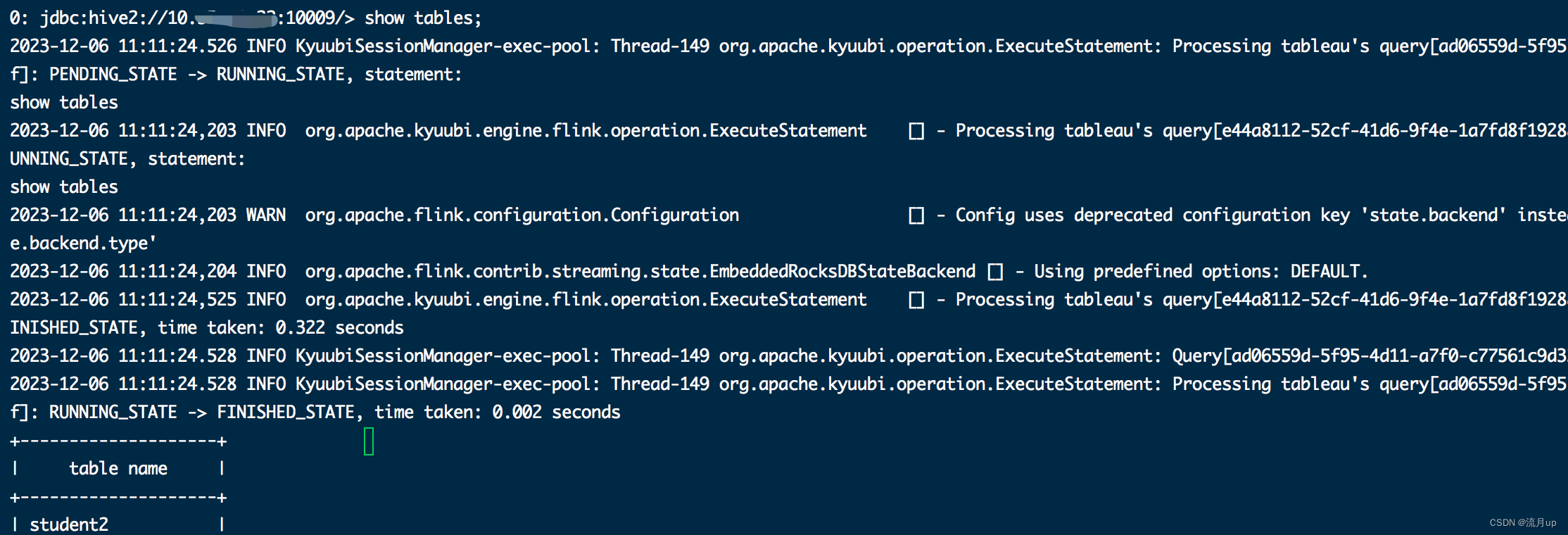
重要的步骤:
设置
flink为批模式
SET execution.runtime-mode=batch;


业务稍大的数据处理:
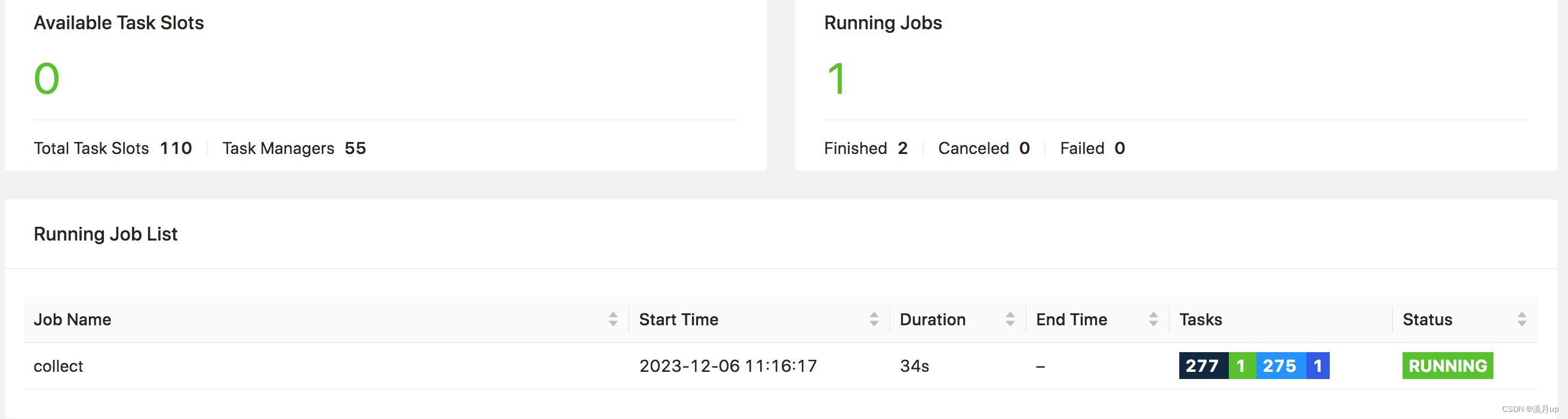

结束
kyuubi整合flink yarn application model 至此结束,如有问题,欢迎评论区留言。
这篇关于kyuubi整合flink yarn application model的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








