本文主要是介绍Cloud Foundry中基于Master/Slave机制的Service Gateway——解决Service Gateway单点故障问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Cloud Foundry作为业界最出色的PaaS平台之一,给广大的互联网开发者和消费者提供出色的体验。自Cloud Foundry开源以来,有关Cloud Foundry的研究越来越多,这也很好的支持着Cloud Foundry的生态系统。但是作为一个平台,Cloud Foundry仍然会存在一些可靠性,扩展性方面的不足,这也吸引着众多的Cloud Foundry爱好者对其进行更多更深入的研究。
本文主要讲述Cloud Foundry中Service Gateway的运行机制,Service Gateway存在的单点故障问题,以及解决单点问题的Master/Slave Service Gateway机制。
1. Service Gateway运行机制
关于Cloud Foundry中Service Gateway的介绍,可以参考我之前的博文:Cloud Foundry Service Gateway 源码分析。
介绍该组件运行机制的时候,我希望使用Service Gateway的最常用的功能provision a service 和 bind a service 来简要阐述,虽然不能代表所有的功能,但是这两个功能可以让我们对Service Gateway运行机制了解个大概。
1.1 Service Gateway的启动
以上提及的博文中已经介绍得很多,关于启动,需要强调的是fetch_handles的功能,即Service Gateway向Cloud Controller请求获得service instance的信息,并存储在内存中,后面会讲到在provision a service 的时候会用到该内存中的信息;还有send_heartbeat的功能,即Service Gateway向Cloud Controller发送心跳信息,证明自己的存活状态(另外Cloud Controller也会通过这个心跳信息来存储该类型Service Gateway)。
1.2 provision a service
provision a service 的流程很简单明了,主要实现创建一个服务实例,无非是Cloud Controller接收用户请求,使用HTTP方式发送给Service Gateway,Service Gateway接收并处理请求后通过NATS向Service Node发送provision请求,Service Node接收到请求到provision完毕后,通过NATS将结果返回给Service Gateway,Service Gateway将结果备份一份以后,通过HTTP方式返回给Cloud Controller,最后Cloud Controller收到结果信息,将其持久化至数据库,并对用户做回应。这里需要注意的是:首先,关于provision出来的service instance的信息最终会被持久化到Cloud Controller的postgres数据库中;然后,关于这些信息,Service Gateway会备份一份(存储在内存中)。这两点在后文中会显得尤为重要。
1.3 bind a service
bind a service 主要是实现为一个应用绑定一个服务实例。流程与通信方式和provision a service 大同小异,不同的是,在Service Gateway在接收到Cloud Controller的时候,会从自己关于service的备份信息中找出来相应的service instance,然后给该instance发送请求。
2. Service Gateway的单点故障问题
在Cloud Foundry中,同种类型service的Service Gateway只有一个,因此在运行过程中,肯定会出现单点故障问题。一旦Service Gateway所在节点宕机,那么该Service Gateway变得不可用,所以关于该service的provision和bind等众多请求都将得不到响应。需要注意的是,对于已经成功bind服务的应用来讲,是不受影响的,因为app可以直接通过URL访问Service Node,而不用经过Service Gateway。
由于目前的Cloud Foundry缺乏对于组件的状态监控机制,所以Cloud Foundry对于Service Gateway的宕机不会采取任何措施,因此Cloud Foundry的管理员也不会被告知Service Gateway的故障,从而导致该类型service的不可用。当Cloud Foundry的用户感受到该类型service不可用,并且向管理员反馈时,管理员才会去后台去查看Service Gateway的状态,发现状态为关闭状态,从而进行人为的启动。在这一漫长的过程中,该类型的service均处于不可用状态,大大影响Cloud Foundry的可用性。
在这样的情况下,最理想的解决方案自然可以使得Cloud Foundry中关于某种类型的service可以具有多个Service Gateway ,如此一来,在一个Service Gateway宕机的时候,还可以有其他的Service Gateway继续工作。通过以上的假设,在实际过程中,我曾经尝试过两种方案:Master/Slave Gateway 以及Multi Gateways。以下是两个方案的简述:
- Master/Salve Gateway: 该方案在执行过程中,只有一个Service Gateway接收到Cloud Controller的请求,并做处理;只有当一个Service Gateway宕机的时候,Cloud Controller才会将请求发给另一个请求。看到这里,肯定会有一些问题:那就是Cloud Controller如何获知Gateway是否宕机的信息,另外Cloud Controller如何决策将请求发送给哪个gateway,还有一个Service Gateway已经provision完一个服务后宕机,则关于该服务的bind请求会发送至另一个Service Gateway,而这个Service Gateway不具有这个服务的任何信息,从而导致请求不能被执行。本文主要讲述这种方案的设计与实现。
- Multi Gateways: multi 就是多个,另外有一种多个之间地位平等的概念,也就是说在Cloud Controller在接收到请求之后,分发给所有的该类型service的Service Gateway,从而使得当一个Service Gateway宕机之后,而其他的所有gateway仍能正常工作。当然,该方案也会存在难点:除了上一种方案中的部分困难之外,还有:由于请求为多个,一个Service Node接收到多个Service Gateway的请求后,该如何决策该请求是否执行过等。
3. 基于Master/Slave模式的Service Gateway
关于Master/Slave模式的Service Gateway框架如下图:
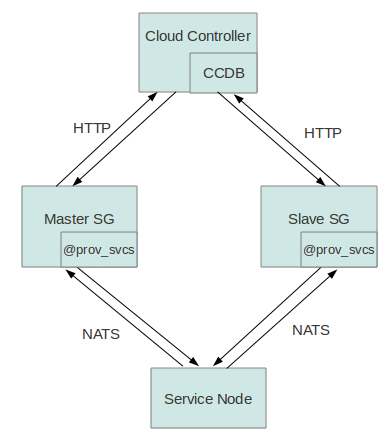
3.1 两个Service Gateway的注册问题
由于该方案中有两个同种类型的Service Gateway与Cloud Controller相连,则必须要解决的问题是:如何让Cloud Controller认识这两个Service Gateway。在这里,我们可以回忆在原先的Cloud Foundry中,Cloud Controller如何认识或者存储一个Service Gateway:Cloud Controller接收Service Gateway的heartbeat信息的同时,在自己的postgres数据库中存储该Service Gateway的信息,也相当于完成Service Gateway的注册。
解决方案:
启动同种类型service的两个Service Gateway,他们分别向Cloud Controller发送heartbeat,由Cloud Controller接收这些请求,并决策哪一个是Master,哪一个是Slave ,从而存入数据库。
具体实现:
Cloud Controller的软件框架是基于Rails编写的,关于postgres数据库的数据表都有一个model(MVC模式中的M),而修改数据表的模式则必须修改这个model文件,由于之前的模式会验证service类型的唯一性,现在则必须将/cloudfoundry/cloud_controller/cloud_controller/app/models/service.rb中的验证代码validates_uniqueness_of :label 给注释掉,这样就有了向数据库中添加相同类型service的可能性。另外我们还需要在该模式中加入一个属性MasterOrSlave,这样可以使得Cloud Controller决策Master/Slave后,将带有Master/Slave标记的service记录存入postgres数据库。
以上操作只是从理论上,允许在数据库中出现两个相同label的service记录,关于最终往数据库中存两条记录还是需要Cloud Controller的controller来实现(MVC中的C)。在具体程序运行中,service_controller.rb文件中的create方法会接收来自Service Gateway的heartbeat信息,并做相应的注册。为了实现Master/Slave模式,我们需要改进该方法,加入决策机制,实现Master/Slave的注册。下图是决策机制:
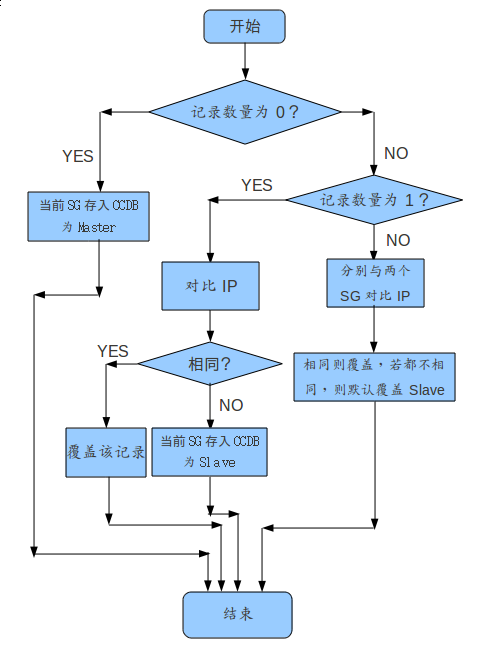
3.2 Cloud Controller决策使用Service Gateway的问题
解决了以上的注册问题,Cloud Foundry还需要解决Cloud Controller如何选择Service Gateway的问题。
解决方案:
Cloud Controller关于某一label的service 请求,首先找到该label的Master Service Gateway,如果该Service Gateway的active属性为TRUE,则表示该Service Gateway存活状态为存活,可以接收请求;若active属性为FALSE,则表示该Service Gateway存活状态为不存活,则找到该label的Slave Service Gateway,若Slave Service Gateway的active属性为TRUE,则表示Slave Service Gateway可以接收请求,否则该类型的Master Slave Service Gateway都不可用,请求不会执行,用户被告知Service Gateway不可用。决策流程如下图:
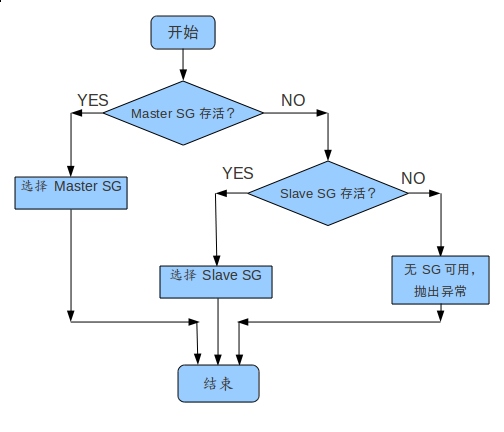
3.3 Master/Slave Service Gateway之间服务信息的同步问题
在Cloud Foundry中Service Gateway的运行机制中,已经介绍了provision和bind的功能,在这两个过程中,都涉及了一个内存空间(具体代码为@prov_svcs),这个内存空间用来存放这个service类型的service信息。Service Gateway启动的时候会通过fetch_handles方法获取全部的信息,另外在每次经过这个Service Gateway的provision和bind等请求时,会有相应的信息更新。
那如果使用Master/Slave Service Gateway机制的话,为什么要考虑两个Service Gateway之间@prov_svcs的同步信息呢?关于这个问题,可以推测:要保证Master/Slave Service Gateway的高可用性,那么在一个Service Gateway宕机的时候,另一个Service Gateway仍然可以工作,并接管之后的请求。但是,如果一个请求通过Master Service Gateway 成功provision 一个服务实例后,Master Service Gateway宕机了,那么关于这个服务实例的bind请求,肯定会通过Slave Service Gateway来完成,然而Slave Service Gateway不具有这个服务实例的任何信息,故bind失败。毫无疑问,Master/Slave Service Gateway机制必须解决服务信息的同步问题,也就是在一个Service Gateway完成某一个请求,更新@prov_svcs后,必须将相同的更新告知另一个Service Gateway,完成信息的同步。
解决方案:
从Service Gateway的请求流程来看,关于service instance的信息在@prov_svcs中更新后,都会存储到Cloud Controller的postgres数据库中。为了做到Master/Slave Service Gateway的服务信息同步,最有效的方法就是一有信息被更新到Cloud Controller的postgres数据库中,就马上把这个更新信息发送给另一个Service Gateway。为了简单起见,本文采取的同步方式是:Service Gateway以一个可以人为设定的频率向Cloud Controller发送获取服务信息的请求。这样的话,从一定程度上说,可以保证两个Service Gateway服务信息的同步。
具体实现:
在上文的Service Gateway启动的时候,已经讲述过,Service Gateway会使用fetch_handles方法来获取服务信息,具体代码见asynchronous_service_gateway.rb:
update_callback = Proc.new do |resp|@provisioner.update_handles(resp.handles)@handle_fetched = trueevent_machine.cancel_timer(@fetch_handle_timer)# TODO remove it when we finish the migrationcurrent_version = @version_aliases && @version_aliases[:current]if current_version@provisioner.update_version_info(current_version)else@logger.info("No current version alias is supplied, skip update version in CCDB.")endend@fetch_handle_timer = event_machine.add_periodic_timer(@handle_fetch_interval) { fetch_handles(&update_callback) }event_machine.next_tick { fetch_handles(&update_callback) }从代码中可以看到Service Gateway是首先是通过一个周期性的timer向Cloud Controller发送获取请求,当收到Cloud Controller的响应之后,取消了这个timer。在Master/Slave Service Gateway 中为了不断地发送fetch_handles请求,只需要将代码event_machine.cancel_timer(@fetch_handle_timer)注释掉即可。这样的话,Service Gateway就会以周期@handle_fetch_interval发送fetch_handles请求。只要Cloud Controller关于service的信息有变动,Service Gateway就会在@handle_fetch_interval时间内获知。在此基础上,修改以上代码只是实现周期性发送请求,而Service Gateway在接受周期性响应后,还需要在处理的时候作出相应的修改,具体代码在provision.rb中,可以每次执行的时候都将@prov_svcs置空,然后再将所有的服务信息放入hash对象@prov_svcs。
关于该问题的解决,以上只是阐述了Service Gateway需要作的改动,这包括Service Gateway发送请求和接受请求,但是只有这些还是不够的,对于通信的Server端,Cloud Controller也需要作一定的修改,主要是如何根据Service Gateway的请求,读取postgres数据库中所有的服务信息。代码地址主要为cloudfoundry/cloud_controller/cloud_controller/app/controllers/service_controller.rb的list_handles方法。由于Cloud Controller都是通过Service Gateway的URL信息去寻找数据库中数据表service_bindings和service_configs的关于该Service Gateway的所有service instance,而现在是Master/Slave Service Gateway机制,需要将两个Service Gateway的服务信息全部信息找出,并返回给Service Gateway。比如:service instance A是由 Master Service Gateway来provision或者bind的,那么在service_configs或者service_bindings中是属于Master Service Gateway的,因此Slave Service Gateway在获取handles的时候,也需要将Master Service Gateway取出,并返回给Slave Service Gateway。其中的具体实现可以参考Rails中的model,在这里service_binding blongs_to :service_config,service_config belongs _to :service。
3.4 unprovison, bind和unbind等请求的部分修改
关于这部分的修改,以unprovision请求为例:
Cloud Controller在收到用户关于某service instance的unprovision后,首先会从service_configs数据表中找出这个service instance,然后再取出Service Gateway的URL信息,并向这个URL发送unprovision请求。但是如果现在这个Service Gateway已经宕机的话,之前的机制将不能响应这个请求。如果要在Master/Slave Service Gateway机制中解决这个问题,只需要在每次执行unprovision请求的时候,不是去找service instance的Service Gateway信息,而是去寻找当前正在工作的Service Gateway 来完成unprovision工作。
关于bind和unbind操作,也是如此,在Cloud Controller向Service Gateway发送请求的时候,不是通过service instance来寻找Service Gateway,而是通过当前存活的Service Gateway来寻找。
4. 评价
以上关于Master/Slave Service Gateway设计与实现,已经阐述完毕,现在可以在评价这个机制。
首先从可用性入手,该机制很好的解决了之前Cloud Foundry中Service Gateway的单点故障问题,一旦Cloud Foundry中的一个Service Gateway宕机的话,该机制下,Cloud Foundry仍然可以使用另一个Service Gateway来完成工作。当然,当两个Service Gateway都宕机的情况下,该机制也不能正常保证Service的工作,但是在两个Service Gateway相同环境下,出现这种情况的概率要远远低于只有一个Service Gateway的时候。
Master/Slave Service Gateway机制最重要的部分主要是如何实现service信息的同步问题,本设计主要是通过周期性的发送获取请求,来实现最终的同步。但是周期性的请求,其实不能严谨的保证consistency。如果关于一个service instance的porvision和bind操作在一个周期内需要完成,而在两个请求之间的某个时刻,Master Service Gateway宕机的话,Slave Service Gateway也不可用。当这个周期非常粗粒度的时候,这样的问题是不能容忍的,但是如果这个周期比较细粒度的话,问题能得到非常好的缓解,这样的情况几乎可以忽略不计。但是当周期性的请求粒度很细的话,势必会造成Cloud Controller的通信的拥挤,这也是一个在请求很多,系统很大的时候不得不考虑的问题。
5. 总结
本文主要旨在解决原先Cloud Foundry中关于Service Gateway的单点故障问题。在简要介绍Service Gateway的运行流程后,讲述了Service Gateway可能存在的单点故障问题,并对于该问题提出了两种解决方案。随后,本文大篇幅介绍了其中一个解决方案Master/Slave Service Gateway机制,主要包括该方案的具体解决的问题和具体实现。最后,对于该机制进行了简要的评价,主要着眼于可用性与对系统的性能影响。
转载请注明出处。
这篇文档更多出于我本人的理解,肯定在一些地方存在不足和错误。希望本文能够对开始接触Cloud Foundry中service的人有些帮助,如果你对这方面感兴趣,并有更好的想法和建议,也请联系我。
我的邮箱:shlallen@zju.edu.cn新浪微博:@莲子弗如清
这篇关于Cloud Foundry中基于Master/Slave机制的Service Gateway——解决Service Gateway单点故障问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






