本文主要是介绍kibana日志搜索规则及搜索界面显示处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目调用ES日志检索接口,实现简单的日志界面展示;操作数据,然后通过数据去渲染页面,而不是直接操作DOM
日志检索语法
简单的对基本的语法做一个总结
1.语法关键字
+ - && || ! ( ) { } [ ] ^ “ ~ * ? : /
如果所要查询的查询词中本身包含关键字,则需要用\进行转义(注意是本身!)
例1:rvm:5100/kibana/kibana:6.7.0

例2:[MessageBroker-1]
2.查询词(Term)
支持两种查询词,一种是单一查询词,如”hello”,一种是词组(phrase),如”hello world”。
例1:Unexpected

例2:”not get “

3. 查询域(Field)
在查询语句中,可以指定从哪个域中寻找查询词,如果不指定,则从默认域中查找。
查询域和查询词之间用:分隔,如title:”Do it right”。
:仅对紧跟其后的查询词起作用,如果title:Do it right,则仅表示在title中查询Do,而it right要在默认域中查询。
例1:stream:”stdout”

例2:只搜“1”,可以搜到log和message两个字段都有1,搜 log:“1”,只可以搜到log字段的1

4.通配符查询(Wildcard)
支持两种通配符:?表示一个字符,*表示多个字符。
通配符可以出现在查询词的中间或者末尾,如te?t,test*,te*t,但决不能出现在开始,如*test,?test。
例1:k8s-?

例2: k8s-*

例3:kube-syst*m

5.模糊查询(Fuzzy)
模糊查询的算法是基于Levenshtein Distance,也即当两个词的差别小于某个比例的时候,就算匹配,如roam~0.8,即表示差别小于0.2,相似度大于0.8才算匹配。
例1:fetc~

例2:con~

6.临近查询(Proximity)
在词组后面跟随~10,表示词组中的多个词之间的距离之和不超过10,则满足查询。
所谓词之间的距离,即查询词组中词为满足和目标词组相同的最小移动次数。
如索引中有词组”apple boy cat”。
如果查询词为”apple boy cat”~0,则匹配。
如果查询词为”boy apple cat”~2,距离设为2方能匹配,设为1则不能匹配。
| 步数 | 1 | 2 | 3 |
|---|---|---|---|
| (0) | boy | apple | cat |
| (1) | boy cat | apple | |
| (2) | apple | boy | cat |
如果查询词为”cat boy apple”~4,距离设为4方能匹配。
| 步数 | 1 | 2 | 3 |
|---|---|---|---|
| (0) | cat | boy | apple |
| (1) | cat boy | apple | |
| (2) | boy | cat apple | |
| (3) | boy apple | cat | |
| (4) | apple | boy | cat |
例1:”not get user”~0

例2:”get not user”~3

7.区间查询(Range)
区间查询包含两种,一种是包含边界,用[A TO B]指定,一种是不包含边界,用{A TO B}指定。
如date:[20020101 TO 20030101],当然区间查询不仅仅用于时间,如title:{Aida TO Carmen}
例1:hostname:{k8s-1 TO k8s-5}

8.增加一个查询词的权重(Boost)
可以在查询词后面加^N来设定此查询词的权重,默认是1,如果N大于1,则说明此查询词更重要,如果N小于1,则说明此查询词更不重要。
如jakarta^4 apache,”jakarta apache”^4 “Apache Lucene”
例1:network^4 error

9.布尔操作符
布尔操作符包括连接符,如AND,OR,和修饰符,如NOT,+,-。
默认状态下,空格被认为是OR的关系,QueryParser.setDefaultOperator(Operator.AND)设置为空格为AND。
+表示一个查询语句是必须满足的(required),NOT和-表示一个查询语句是不能满足的(prohibited)。
例1:network AND error

例2: network OR error

10.组合
可以用括号,将查询语句进行组合,从而设定优先级。
如(jakarta OR apache) AND website
例1:network AND (error OR success)

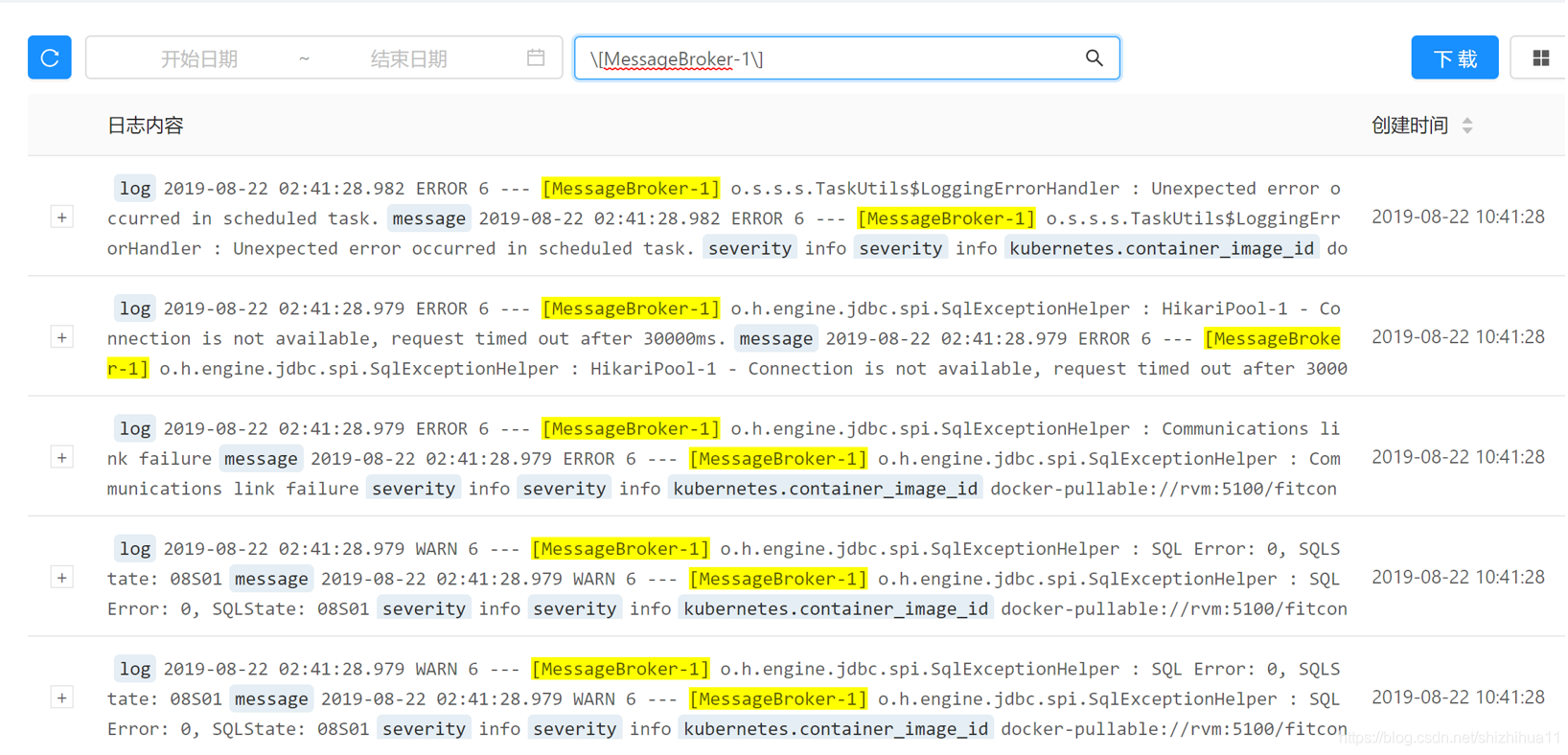
前端高亮显示kibana搜索结果
那界面如何实现key值标蓝显示,搜索结果标黄显示呢?
ES接口可以返回哪些是搜索结果,对应在文本中替换即可。
import React, { PureComponent, Fragment } from 'react';
import { connect } from 'dva';
import { formatMessage } from 'umi-plugin-react/locale';
import { Card, Button, DatePicker, Modal, notification } from 'antd';
import RefreshTable from '@/components/RefreshTable';
import PageHeaderWrapper from '@/components/PageHeaderWrapper';
import styles from './Log.less';
import AceEditor from 'react-ace';
import jQuery from 'jquery';
import brace from 'brace';
import 'brace/mode/json';
import 'brace/mode/yaml';
import 'brace/theme/github';
const $ = jQuery;const { RangePicker } = DatePicker;@connect(({ log, loading }) => ({log,loading: loading.models.log,
}))
class Log extends PureComponent {state = {pageSize: 50,pageNo: 1,filterParam: '',sortBy: '',sortFlag: 'desc',startTime: null,endTime: null,initFlag: true,logAll: [],renderStartFlag: true,renderParam: '',};lastlog = [];columns = [{title: '日志内容',dataIndex: '_source',disabled: true,key: '_source',render: (text, record, index) => (// 日志显示内容很多,且页面渲染,所以根据高度折叠;点击+查看更多<divstyle={{height: $('.antd-pro-pages-log-log-logColor').height() * 3 + Number(12),overflow: 'hidden',}}>{record._source &&this.getLogArr(record._source, index, record.highlight) &&this.getLogArr(record._source, index, record.highlight).length !== 0 &&this.getLogArr(record._source, index, record.highlight).map(item => (<Fragment>{/* 每个key值标蓝 logColor是蓝色样式 */}<span className={styles.logColor}>{Object.keys(item)[0]}</span>{/* 因为value值会对搜索结果标黄,span包裹搜索结果,所以需渲染html */}<spanclassName={styles.logText}dangerouslySetInnerHTML={{ __html: Object.values(item)[0] }}></span></Fragment>))}</div>),},{title: '创建时间',dataIndex: 'time',sorter: true,width: 155,key: 'time',},];componentDidMount() {// 一开始获取日志数据this.getServiceList();}getServiceList = value => {const { dispatch } = this.props;let params = {};if (!value) {const { pageSize, pageNo, filterParam, sortBy, sortFlag } = this.state;params = {pageSize,pageNo,keyword: filterParam.trim(),sortBy,sortFlag,};} else {params = value;}delete params.sortBy;dispatch({type: 'log/fetch',payload: params,callback: res => {this.setState({renderStartFlag: true,startLogTime: res.data.startTime,endLogTime: res.data.endTime,});},});};getLogArr = (logData, index, highlight) => {// highlight每一行数据标黄部分const { renderParam, initFlag, renderStartFlag } = this.state;if (!initFlag && !renderStartFlag) {let resultArr = [];resultArr = this.lastlog[index];return resultArr;}let logArr = [];if (logData && Object.keys(logData).length !== 0) {Object.keys(logData).forEach(item => {if (typeof logData[item] !== 'object') {// 如果不是对象,直接显示let logObj = {};logObj[item] = logData[item];logArr.push(logObj);} else {// 还是对象,继续循环Object.keys(logData[item]).forEach(citem => {if (typeof logData[item][citem] !== 'object') {let logObj = {};logObj[`${item}.${citem}`] = logData[item][citem];logArr.push(logObj);} else {Object.keys(logData[item][citem]).forEach(sitem => {let logObj = {};logObj[`${item}.${citem}.${sitem}`] =typeof logData[item][citem][sitem] === 'string'? logData[item][citem][sitem]: JSON.stringify(logData[item][citem][sitem]);logArr.push(logObj);});}});}});}let resultArr = [];let beforeArr = [];let afterArr = [];if (renderParam !== '' && renderStartFlag && highlight) {logArr.forEach(item => {Object.keys(highlight).forEach(jitem => {if (jitem === Object.keys(item)[0]) {let itemValue = highlight[jitem][0];itemValue = itemValue.replace(/</g, `<`);itemValue = itemValue.replace(/>/g, `>`);// 返回结果需高亮标黄的搜索结果;且把包含搜索结果的键值对提前itemValue = itemValue.replace(/@kibana-highlighted-field@/g,`<span class='logYellow'>`);itemValue = itemValue.replace(/@\/kibana-highlighted-field@/g, `</span>`);item[Object.keys(item)[0]] = itemValue;beforeArr.push(item);} else {afterArr.push(item);}});});resultArr = beforeArr.concat(afterArr);} else {resultArr = logArr;}this.lastlog[index] = resultArr;return resultArr;};render() {const {log: { data },loading,route,} = this.props;return (<PageHeaderWrapper content={`${formatMessage({ id: `logCaption` })}`}><Card bordered={false}><RefreshTabledata={data && data.data ? data.data : {}}rowKey={record =>`${record.id}/${record._source['@timestamp']}/${record._source['docker'] &&record._source['docker']['container_id']}/${record._source['_BOOT_ID']}`}columns={this.columns}locale={locle}expandedRowRender={record => (<AceEditorwidth="100%"mode="json"key={record._source['@timestamp']}height="300px"value={record._source ? JSON.stringify(record._source, null, 4) : ''}theme="github"name="UNIQUE_ID_OF_DIV"editorProps={{ $blockScrolling: true }}/>)}></RefreshTable></Card></PageHeaderWrapper>);}
}export default Log;
这篇关于kibana日志搜索规则及搜索界面显示处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




