本文主要是介绍Hazelcast分布式内存网格(IMDG)基本使用,使用Hazelcast做分布式内存缓存,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、Hazelcast简介
- 1、Hazelcast概述
- 2、Hazelcast之IMDG
- 3、数据分区
- 二、Hazelcast配置
- 1、maven坐标
- 2、集群搭建
- (1)组播自动搭建
- 3、客户端
- 4、集群分组
- 5、其他配置
- 三、Hazelcast分布式数据结构
- 1、IMap
- 2、IQueue:队列
- 3、MultiMap
- 4、ISet
- 5、IList
- 6、其它
- 参考资料
一、Hazelcast简介
1、Hazelcast概述
官方文档:https://docs.hazelcast.com/hazelcast/5.3/
Hazelcast是驻内存数据网格(In-Memory Data Grid,IMDG)的数据网格开源项目,同时也是该公司的名称。Hazelcast提供弹性可扩展的分布式内存计算,Hazelcast被公认是提高应用程序性能和扩展性最好的方案。Hazelcast通过开放源码的方式提供以上服务。更重要的是,Hazelcast通过提供对开发者友好的Map、Queue、ExecutorService、Lock和JCache接口使分布式计算变得更加简单。例如,Map接口提供了内存中的键值存储,这在开发人员友好性和开发人员生产力方面提供了NoSQL的许多优点。
除了在内存中存储数据外,Hazelcast还提供了一组方便的api来访问集群中的cpu,以获得最大的处理速度。轻量化和简单易用是Hazelcast的设计目标。Hazelcast以Jar包的方式发布,因此除Java语言外Hazelcast没有任何依赖。Hazelcast可以轻松地内嵌已有的项目或应用中,并提供分布式数据结构和分布式计算工具。
Hazelcast 具有高可扩展性和高可用性(100%可用,从不失败)。分布式应用程序可以使用Hazelcast进行分布式缓存、同步、集群、处理、发布/订阅消息等。Hazelcast基于Java实现,并提供C/C++,.NET,REST,Python、Go和Node.js客户端。Hazelcast遵守内存缓存协议,可以内嵌到Hibernate框架,并且可以和任何现有的数据库系统一起使用.
如果你正在寻找基于内存的、高速的、可弹性扩展的、对开发者友好的NoSQL,Hazelcast是一个很棒的选择。
2、Hazelcast之IMDG
Hazelcast功能非常强大,本文主要讨论Hazelcast用于做分布式缓存。
Hazelcast做IMDG的官方文档如下:https://docs.hazelcast.com/imdg/4.2/
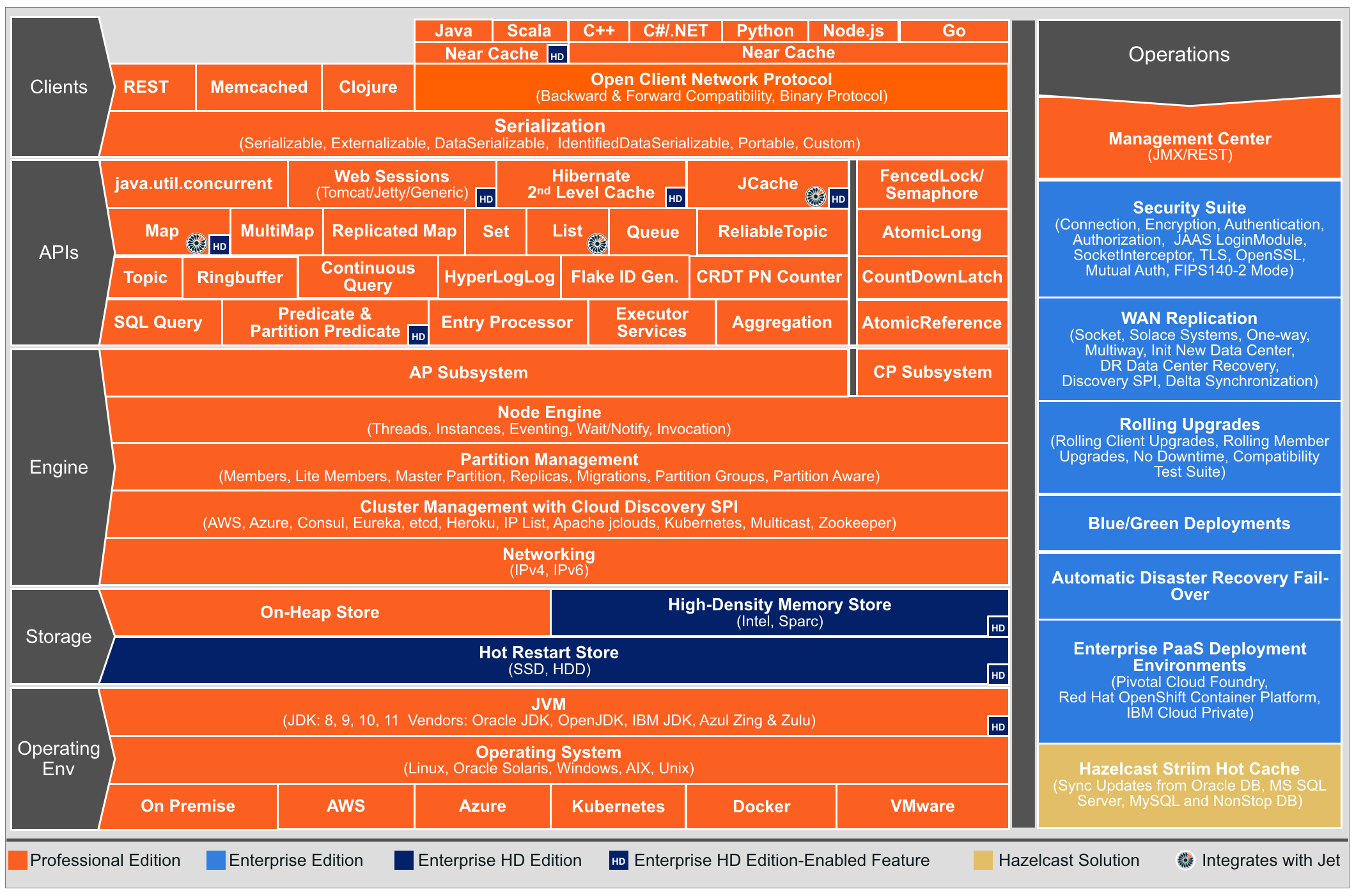
Hazelcast支持如下语言的API:Java、.NET、C++、Node.js、Python、Go。在此我们主要讨论JavaAPI。
下面的架构图中包含所有Hazelcast IMDG版本的功能:
3、数据分区
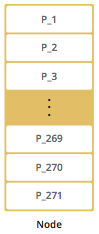
默认情况下,Hazelcast提供271个分区。当您启动只有一个成员的集群时,它拥有全部271个分区(即,它保留271个分区的主副本)。下图显示了具有单个成员的Hazelcast群集中的分区。
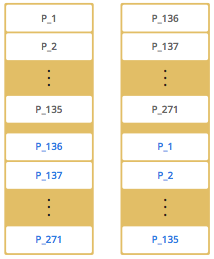
当添加更多成员时,Hazelcast会将一些主分区副本和备份分区副本逐个移动到新成员,从而使所有成员都是平等的和冗余的。得益于一致的哈希算法,只有最少量的分区被移动以横向扩展Hazelcast。下面是一个有四个成员的Hazelcast集群中的分区副本分布图:
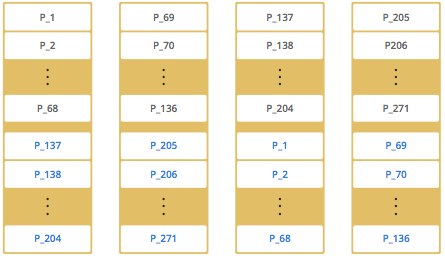
也就是说,Hazelcast会对数据进行冗余,以实现它的高可用。一个节点挂掉之后,其分区中的数据一定会在集群中其它服务中找到。
Hazelcast通过分区表存储分区id和它们所属的集群成员的地址。这个表的目的是让集群中的所有成员(包括lite成员)都知道这个信息,确保每个成员都知道数据在哪里。
二、Hazelcast配置
1、maven坐标
直接引入jar包即可使用,非常方便。
<!-- https://mvnrepository.com/artifact/com.hazelcast/hazelcast -->
<dependency><groupId>com.hazelcast</groupId><artifactId>hazelcast</artifactId><version>5.3.6</version>
</dependency>Gradle等其他坐标请移步:
https://mvnrepository.com/artifact/com.hazelcast/hazelcast/5.3.6
2、集群搭建
(1)组播自动搭建
Config cfg = new Config();
HazelcastInstance instance = Hazelcast.newHazelcastInstance(cfg);
Map<Integer, String> mapCustomers = instance.getMap("customers");
mapCustomers.put(1, "Joe");
mapCustomers.put(2, "Ali");
mapCustomers.put(3, "Avi");System.out.println("Customer with key 1: "+ mapCustomers.get(1));
System.out.println("Map Size:" + mapCustomers.size());Queue<String> queueCustomers = instance.getQueue("customers");
queueCustomers.offer("Tom");
queueCustomers.offer("Mary");
queueCustomers.offer("Jane");
System.out.println("First customer: " + queueCustomers.poll());
System.out.println("Second customer: "+ queueCustomers.peek());
System.out.println("Queue size: " + queueCustomers.size());
以上代码运行两次,就会形成一个集群:
Members {size:2, ver:2} [Member [127.0.0.1]:5701 - e40081de-056a-4ae5-8ffe-632caf8a6cf1 thisMember [127.0.0.1]:5702 - 93e82109-16bf-4b16-9c87-f4a6d0873080
]
在这里,您可以看到集群的大小(size)和成员列表版本(ver).当集群发生变化时,成员列表版本递增,例如,成员离开或加入集群。
默认情况下,Hazelcast通过组播的形式,在同一个网络中,自动发现其它成员。
3、客户端
下面的代码启动一个Hazelcast客户机,连接到我们的集群,并打印customers Map:
public class GettingStartedClient {public static void main( String[] args ) {ClientConfig clientConfig = new ClientConfig();HazelcastInstance client = HazelcastClient.newHazelcastClient( clientConfig );IMap map = client.getMap( "customers" );System.out.println( "Map Size:" + map.size() );}
}
Hazelcast其实有两种用法,一种是搭建一个独立的服务器集群,然后客户端连接上进行使用,就像redis那样。还有一种是,随着项目的启动而启动,此时就不需要客户端了,每一个java应用都作为Hazelcast集群服务的一员。
4、集群分组
通过指定集群名称,可以简单地对集群进行分离和分组。
可以通过编程方式定义集群配置(也可以使用xml和yaml进行配置https://docs.hazelcast.com/imdg/4.2/clusters/creating-clusters)。一个JVM可以托管多个Hazelcast实例。每个Hazelcast实例只能参与一个组。每个Hazelcast实例只加入自己的组,不与其他组交互:下面的代码示例创建三个单独的Hazelcast实例-h1属于production群集,而h2和h3属于development集群:
Config configProd = new Config();
configProd.setClusterName( "production" );Config configDev = new Config();
configDev.setClusterName( "development" );HazelcastInstance h1 = Hazelcast.newHazelcastInstance( configProd );
HazelcastInstance h2 = Hazelcast.newHazelcastInstance( configDev );
HazelcastInstance h3 = Hazelcast.newHazelcastInstance( configDev );
5、其他配置
Hazelcast用于在集群成员之间通信的端口。其默认值为5701,如果端口被占用会递增,可以进行配置:
Config config = new Config();
config.getNetworkConfig().setPort( 5701 ).setPortAutoIncrement( true ).setPortCount( 20 );
其他网络配置:Hazelcast提供自动检测、多播、TCP/IP、AWS、Kubernetes、Azure、GCP、Eureka等等。
https://docs.hazelcast.com/imdg/4.2/clusters/network-configuration
Hazelcast可以使用xml或者yaml进行特殊的额外配置,在项目中,新建一个hazelcast.yml或者hazelcast.xml,在里面进行配置,更多配置请移步官方文档!
三、Hazelcast分布式数据结构
1、IMap
IMap继承了ConcurrentMap,所以我们可以使用其put和get方法对数据进行写入和读取。其所有的操作都是线程安全的。
Hazelcast对IMap数据进行分区(上面讨论过)存储,并进行备份。
Config config = new Config();
config.setClusterName("CLUSTER_NAME");MapConfig mapConfig = new MapConfig();
mapConfig.setName("MY_MAP");
mapConfig.setBackupCount(1); // 同步备份,默认就是1
mapConfig.setAsyncBackupCount(1); // 异步备份,默认是0
mapConfig.setTimeToLiveSeconds(100); // 100秒过期时间
mapConfig.setMaxIdleSeconds(100); // 100秒活跃时间,最后一次对其进行读写时间 过期
mapConfig.setInMemoryFormat(InMemoryFormat.NATIVE); // 设置内存格式,二进制、反序列化、堆外内存。默认是二进制方式存储EvictionConfig evictionConfig = new EvictionConfig();
evictionConfig.setEvictionPolicy(EvictionPolicy.LRU); // LRU形式驱逐key
evictionConfig.setSize(1000); // 1000最大key
mapConfig.setEvictionConfig(evictionConfig);config.addMapConfig(mapConfig);
HazelcastInstance hazelcastInstance = Hazelcast.newHazelcastInstance(config);
IMap<String, String> map = hazelcastInstance.getMap("map");map.put( "key", "value", 50, TimeUnit.SECONDS); // 可以为单个key设置过期时间
map.setTtl("key", 50, TimeUnit.SECONDS ); // 单独设置过期时间
map.put( "key", "value", 50, TimeUnit.SECONDS, 40, TimeUnit.SECONDS );// 过期时间、活跃时间
map.put("key", "value");
map.get("key"); // 获取的是一个克隆,并不是原对象!
map.putIfAbsent("key", "value");
map.lock("key"); // 锁定键
map.evictAll(); // 清除锁定键之外的所有的键
map.clear(); // 清除// 可以实现分布式锁
map.lock("key");
map.unlock("key");// 乐观锁
map.replace("key", "old", "new");// 还可以为map添加拦截器,详见官方文档
2、IQueue:队列
IQueue继承了BlockingQueue,是分布式队列,Hazelcast分布式队列允许所有集群成员与之交互。使用Hazelcast分布式队列,您可以在一个集群成员中添加一个项目,并从另一个集群成员中删除它。
Config config = new Config();
config.setClusterName("CLUSTER_NAME");QueueConfig queueConfig = new QueueConfig();
queueConfig.setName("task"); // 设置队列名
queueConfig.setMaxSize(10); // 设置队列最大数量,超过最大数量,再添加将阻塞
queueConfig.setBackupCount(1); // 备份数量config.addQueueConfig(queueConfig);HazelcastInstance hazelcastInstance = Hazelcast.newHazelcastInstance(config);
IQueue<String> queue = hazelcastInstance.getQueue( "task" );
queue.put("MyTask"); // 放值
String task = queue.take(); // 取值boolean offered = queue.offer( "task", 10, TimeUnit.SECONDS );
task = queue.poll( 5, TimeUnit.SECONDS );
if ( task != null ) {//process task
}
3、MultiMap
HazelcastInstance hazelcastInstance = Hazelcast.newHazelcastInstance();
MultiMap<String, String> map = hazelcastInstance.getMultiMap("map");map.put("a", "1");
map.put("a", "2");
map.put("b", "3");
System.out.printf("PutMember:Done");for (String key: map.keySet()){Collection<String> values = map.get(key);System.out.printf("%s -> %s\n", key, values);
}
b → [3]
a → [2, 1]
4、ISet
ISet是的分布式并发实现java.util.Set。它具有以下特点:
- ISet不允许重复元素。
- ISet不保留元素的顺序。
- ISet是一种非分区的数据结构:属于一个集合的所有数据都存在于该成员的一个分区中。
- ISet的规模不能超过单台机器的容量。由于整个集合位于单个分区上,因此在单个集合上存储大量数据可能会造成内存压力。因此,您应该使用多个集合来存储大量数据。这样,所有的集分布在集群中,分担负载。
- ISet的备份存储在集群中另一个成员的分区上,以便在主成员出现故障时数据不会丢失。
- 所有项都被复制到本地成员,迭代在本地发生。
- 在ISet中实现的equals方法使用对象的序列化字节版本,而不是java.util.HashSet.
HazelcastInstance hz = Hazelcast.newHazelcastInstance();
ISet<String> set = hz.getSet("set");
set.add("Tokyo");
set.add("Paris");
set.add("London");
set.add("New York");
System.out.println("Putting finished!");
5、IList
Hazelcast列表(IList)类似于Hazelcast的ISet,但它也允许重复元素。
除了允许重复元素之外,Hazelcast列表(IList)还保留了元素的顺序。
Hazelcast列表(IList)是一种非分区的数据结构,其中值和每个备份由它们自己的单个分区表示。
Hazelcast列表(IList)不能超出单台机器的容量。
所有项目都被复制到本地,迭代在本地进行。
HazelcastInstance hz = Hazelcast.newHazelcastInstance();
IList<String> list = hz.getList("list");
list.add("Tokyo");
list.add("Paris");
list.add("London");
list.add("New York");
System.out.println("Putting finished!");
6、其它
Haselcast还实现了Ringbuffer(环型缓冲器)、Topic(发布订阅)、FencedLock(分布式锁)、IAtomicLong(原子Long类型)、ISemaphore(分布式信号量)、IAtomicReference(分布式原子引用)、ICountDownLatch(分布式闭锁)、PNCounter(PN计数器)、FlakeIdGenerator (ID生成器)等等数据结构,但是由于Haselcast基于内存使用,可靠性并没有Redis高,所以还是得分场景进行使用。
参考资料
https://www.lidihuo.com/hazelcast/hazelcast-index.html
https://www.cnblogs.com/jdw5/p/12017044.html
https://xie.infoq.cn/article/9c7e32628b5839f8490b1f782
官方文档:https://docs.hazelcast.com/imdg/4.2/
这篇关于Hazelcast分布式内存网格(IMDG)基本使用,使用Hazelcast做分布式内存缓存的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






