本文主要是介绍MYSQL练题笔记-高级查询和连接-指定日期的产品价格,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这依旧是中等题,想了好久,终于理解了很开心!
一、题目相关内容
1)相关的表和题目
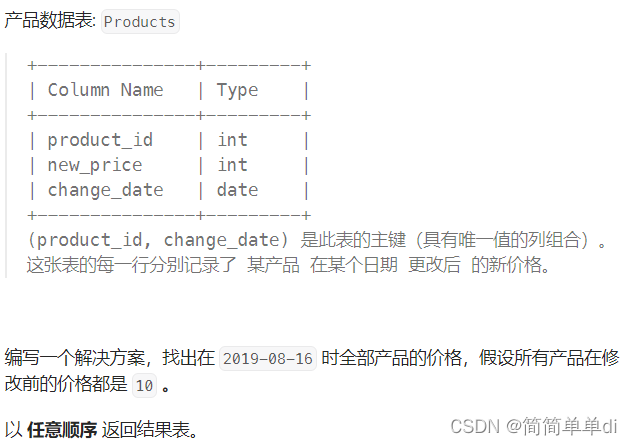
2)帮助理解题目的示例,提供返回结果的格式
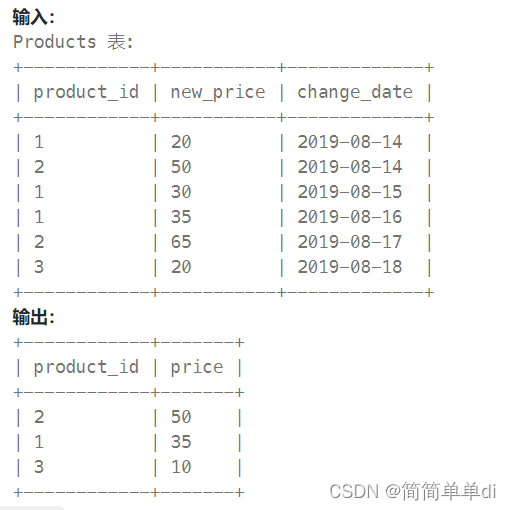
二、自己初步的理解
题目是找出2019-08-16 时全部产品的价格,所以重点是获取想要的时间的产品价格。
提供的表记录了某产品在某个日期更改后的新价格。
那就是改了价格的就有记录;没改就输出,那这里先思考没改的话,price就等于10,但是可能是核心点没有思考全目前也没有具体的想法,先想简单的点好像也不行。
1)那改价格有不同时间改的,16之前以及16这一天改的要及时输出,这一天之后修改对于本题来说话没有意义,重点是有可能改了不止一次。所以要取最大的日期但是不大于16号修改的记录。
2)因为这里同一个的产品可能改了多次,那就需要根据product_id进行分组。然后获取分组里不大于16号的最大的日期的价格。
3)然后这里需要联系上没有修改价格的product_id,但是我发现这个题目里没有所有的产品的id,只有可能是在16号之后修改的产品的价格就是'10'。
然后下面这是我的解答
select p1.product_id,ifnull(p1.new_price,'10') as price from products p1 left join(select product_id,new_price from products group by product_id having max(change_date)<='2019-08-16') change_price on p1.product_id=change_price.product_id;
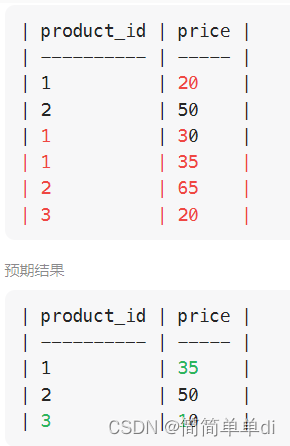
其实我都自信满满的啦,但是给我显示错误,就是下图的错误,所以我屈服去看题解了,不过这次有进步不断地思考自己的逻辑,没有和之前一样,自己逻辑都没有理清的时候就去看题解,搞得最后一知半解。
三、题解展示和分析
正确的题解如下。
select p1.product_id,ifnull(p2.new_price,10) as price from (select distinct product_id from products) p1 left join(select product_id,new_price from products where(product_id,change_date)in(select product_id,max(change_date) from products where change_date <= '2019-08-16' group by product_id))p2 on p1.product_id=p2.product_id;
我和大佬的区别在上面两段红色的代码部分,这说明我总体的逻辑是对的,有两个点,一获取全部产品的id的方式不对,没有想到提取的是不重复的id。二是我直接的子查询和where in的区别,我是想着分组后,每个组里的修改日期最大值<=16号,但其实可以从我上面错误的答案明显的看出来我是没有过滤成功的,但是我一直想不通啊,这里做一个尝试,因为我有两个错误,那我把第一个错误改一下正确题解的,但是这一个错误先不改,就改成了下面的题解
select p1.product_id,ifnull(p2.new_price,10) as price from (select distinct product_id from products) p1 left join(select product_id,new_price from products group by product_id having max(change_date)<='2019-08-16')p2 on p1.product_id=p2.product_id;
输出还是不对,如下

这明显第二个错误是有问题的,没有找到最大的日期,但是确实确实不知道原因!!!!!!!!!
但我知道为什么正确答案正确,啊啊啊!!!
select product_id,new_price from products where(product_id,change_date)in(select product_id,max(change_date) from products where change_date <= '2019-08-16' group by product_id
1)小部分正确答案的分析逻辑
正确答案这部分是在找id和新价格
什么样的id和新价格呢
首先新价格的日期都要小于或者等于16(啊啊啊,这不直接就省掉了很多的记录吗,我一直想着分组后筛选,又没筛对,我还不理解,难啊难!!)
然后找分组过后的里面的最大的日期,注意啊这是筛选后最后找最大的日期,不像之前是全部的日期找最大的(这逻辑不就一下子出来了吗,那我的逻辑是什么)
2)我的小部分答案分析逻辑
我的答案也是在找id和新价格
什么样的id和新价格呢
分组后,新价格的日期的最大值都要小于或者等于16的记录
3)总结上述对比
我知道了!!!!!因为新价格的日期最大值可能大于16,但小一点的小于16。也说明了为啥我的第二条记录为啥错误,他不满足条件就输出10。
而且从上面的输出可以看出来,我的第一个答案也是错了的,这是为什么呢?我自己的猜测是三条记录都满足条件,那就选择第一个输出!!
所以啊,要把逻辑盘顺啊,你就非常好理解了!
四、总结
仔细想仔细想自己的逻辑,切记啊,你不了解自己那你别指望了解正确的题解,正确的答案都在那了,别放着不拿哈,当然前提是你明确自己的逻辑你才是走上了那答案的第一步,加油加油,写完了这难缠的一题了!
这篇关于MYSQL练题笔记-高级查询和连接-指定日期的产品价格的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





