本文主要是介绍首次超越1000量子比特大关!量子前哨详解IBM突破性进展,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

(图片来源:网络)
本周,IBM在其年度量子峰会上宣布,公司已在量子计算领域取得重要突破。其中包括备受期待的1121量子比特Condor QPU,以及一个较小的133量子比特Heron QPU,这些QPU能够与其他QPU组合成更大的量子系统。此外,IBM还介绍了其新一代模块化基础设施——IBM System Two,可以适应多个系统与超低温稀释制冷机。首个IBM System Two已在美国纽约州约克城高地启动并运行,其中包含三个Heron QPU。
IBM还宣布计划在2024年2月份推出Qiskit 1.0,并整合生成式AI功能,使其更为易用。同时,IBM还将分享它的10年量子发展路线图,其规模是之前5年量子发展路线图的一倍。借助去年春天发布的127量子比特Eagle处理器,IBM宣布将通过已改进的错误缓解(error mitigation)和纠正技术(correction techniques)来开启实用化量子时代。
“简而言之,我们能使一台量子计算机以超越暴力检索算法(brute force)的规模来执行可靠的计算。这一重大突破标志着我们进入了一个全新的里程碑。在此之前,我们从未有过此类工具,而现在我们正借助它来探索全新的领域,并努力挖掘其潜在的价值。我们坚信,我们将成为未来首个发掘量子优势的公司。”负责量子算法和科学合作业务的副总裁Katie Pizzolato说。同时她强调,这些探索实验将极大地推动算法的开发进程。
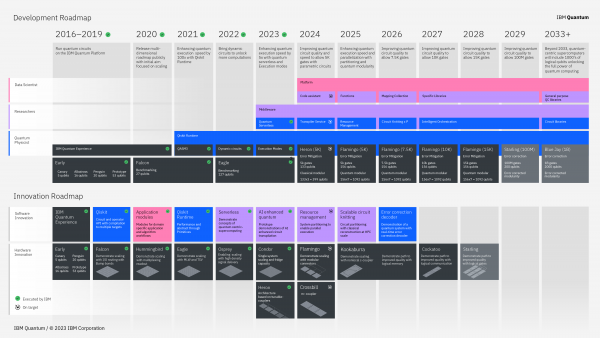
IBM发展路线图(图片来源:网络)
IBM研究员兼IBM公司副总裁Jay Gambetta指出:“我们为实现发展路线图上的每一个里程碑而感到自豪。制定一个为期10年的蓝图是一件大事。可以看到,整个路线图实际上被分为两部分。顶部是我们所说的发展路线图,而底部则是创新路线图。我们的目标是保持全程透明,向公众们展示我们是如何取得进展以及所有创新的。”
他表示:“在接下来的五年内,我们计划将技术质量提升五倍。这将为我们提供更广阔的空间去开展实验,并帮助我们实现量子计算的真正突破,并以此推进重要科学工具的现有极限。为更好地实现2029年的目标,我们期望能够构建一个名为“Starling”的系统,该系统能够在200个量子比特上运行1亿个门。”
以下是本次IBM量子峰会上的一些亮点:
●日本东京大学,美国阿贡国家实验室,西班牙巴斯克科学基金会,以色列量子计算软件公司QEDMA,芬兰量子计算公司Algorithmiq,美国华盛顿大学,德国科隆大学以及澳大利亚量子技术公司Q-CTRL展示了关于探索实用规模大小的量子计算能力的新研究。
●发布IBM性能最高的量子处理器“IBM Quantum Heron”,与先前的“IBM Quantum Eagle”相比,这一全新的架构在减少误差方面的效率提升了5倍。
●IBM Quantum System Two在开始运行时使用了3个IBM Heron处理器,旨在将以量子为中心的超级计算变为现实。
●在接下来的10年里,IBM将着重扩展其量子发展路线图,优先改进门的运行,从而实现先进的纠错系统。
●Qiskit 1.0版本现已发布。据IBM介绍,Qiskit是全球使用最广泛的开源量子编程软件,这一版本具备多项新功能,可协助计算专家更轻松、更快速地设计量子电路。
●IBM将展示其生成式AI模型,这些模型能够利用WatsonX自动开发量子代码并优化量子电路。

IBM Condor QPU(图片来源:网络)

IBM Heron QPU(图片来源:网络)
Condor QPU的大小和规模令人印象深刻。Steffen指出:“它打破了规模限制,展现出了前所未有的特点。它的优势在于拥有1121个超导量子比特,所有的量子比特都生成在单个芯片上,并且量子比特的密度增加了50%。整个芯片被安置在一个单一超低温稀释制冷机中,使其能够冷却设备,其性能与我们的Osprey设备相当。”
然而,目前看来,IBM似乎正将其重心更加直接地转向Heron QPU,而模块化使用更小的量子处理单元来构建更大的系统恰恰是未来的关键。
Steffen表示:“Heron QPU是我们迄今为止性能最为卓越的量子处理器,相较于我们的旗舰设备Eagle,其减少误差的效率提高了5倍。这是一段历时四年的旅程。Heron QPU是为实现模块化和规模化而设计的,我们通过一个可调耦合器结构实现了这一目标。该设计将为我们提供核心组件,以继续提高后续每个处理器内的数据操作质量。我们计划将数个Heron芯片与量子通信连接起来,从而提高其计算能力。”
据Steffen表示,IBM计划明年开始在其全球实用规模系统中提供Heron QPU。
Steffen指出:“相较于目前广受欢迎的表面码,我们已成功研发出一种能显著减少执行纠错程序所需量子比特数的方法。更加令人振奋的是,这一新编码可以被划分为多个‘小块’,总共有12个编码块在量子处理器芯片中。在短距离内,我们能够通过黑色M耦合器实现连接,而在长距离内,我们会使用更长的L耦合器进行连接。这段新代码还需要C耦合器的参与,它能够在单个处理器中连接量子比特。”

(图片来源:网络)

(图片来源:网络)
IBM Quantum System Two基础设施的引入,是提升IBM的竞争力并实现其模块化系统的重要一步。
IBM Quantum System Two将为未来几代量子处理器提供具备完全可扩展性和模块化核心基础设施的能力,使其能够比以往任何时候运行更长的量子电路。

(图片来源:网络)
Qiskit最新版本增加了新的功能和生成式AI能力,Qiskit 1.0将于明年2月首次亮相。
据Gambetta所述,借助Qiskit模式与量子服务器(一种利用量子与经典资源的新型编程模型),用户得以构建、部署、运行甚至于未来实现共享,以供其他用户使用。

(图片来源:网络)
通过将生成式AI从WatsonX扩展到Qiskit,程序员可以借助简单的语言命令生成量子电路。他们只需清晰地阐述所需任务,这些命令便会被送入一个经过训练的模型——Granite中进行处理。该模型对所有的Qiskit数据进行微调,并生成可执行的代码。
Gambetta指出:“我们坚信,充分发挥量子计算的优势能为生成式AI提供强大动力,从而提升开发人员的工作体验。”

(图片来源:网络)
Pizzolato指出:“我们总是说,我们需要找到那些难以进行经典模拟的电路,然后将它们映射到一些有趣的问题上。目前,我们所观察到的早期应用案例主要集中在高能物理和凝聚态物理领域。”
她指出,这些早期的探索都维持在不到sub-20量子比特的范围内。“如果我们按照这样的路线继续发展,我们将需要很长时间才能达到一个超越当前正在讨论的如暴力检索算法等经典方法的规模。我们需要一个颠覆性的改变,从而为该技术创造一个不同的发展轨迹。我们认为,随着《A noisy quantum computer produces accurate expectation valueson 127 qubits》(在127量子比特含噪声量子计算机上产生准确的期望值)这一论文发表,这一变化已经在6月产生了。这是含噪声量子计算机第一次在暴力检索算法之外的规模上产生精确的期望值。”
Pizzolato表示:“自从我们与其他合作伙伴共同撰写的论文《Evidence for the utility of quantum computing before fault tolerance》(前容错量子计算实用性的证据)在《Nature》上发表后,我们已经看到很多人发表论文,并采用量子作为工具来探索sub-20量子比特之外的领域,同时开始探索更大的量子比特计数。”

(图片来源:网络)
实际上,量子计算的发展仍然具有挑战。在更广泛的阶跃函数量子优势应用得以实现之前,是否会出现短期的窄量子优势应用?还不确定,所以当前的首要任务依然是容错和模块化研制。而IBM正专注于实现容错量子计算,同时抓住这一过程中的发展机遇。
编译:琳梦
编辑:慕一
特此说明:量子前哨翻译此文仅作信息传递和参考,并不意味着同意此文中的观点与数据。
欢迎添加我们的微信,加入量子前哨粉丝群
与大家一起探讨交流量子领域动态↓↓↓~~


这篇关于首次超越1000量子比特大关!量子前哨详解IBM突破性进展的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





