本文主要是介绍<Linux>(极简关键、省时省力)《Linux操作系统原理分析之文件管理(3)》(24),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
《Linux操作系统原理分析之文件管理(3)》(24)
- 7 文件管理
- 7.5 文件存储空间的管理
- 7.6 文件的共享和保护
- 7.6.1 文件存取控制
- 7.6.2 文件共享的实现方法
- 7.6.3 文件的备份转储
7 文件管理
7.5 文件存储空间的管理
- 位示图

对每个磁盘可以用一张位示图指示磁盘空间的使用情况。一个磁盘的分块确定后,根据总块数决定位示图由多少字组成,位示图中的每一位与一个磁盘块对应,某位为“ 1”状态表示相应块已被占用,为“0”状态的位所对应的块是空闲块。
块号 b=(i-1)×n+j
i=(b-1)DIV n +1
j=(b-1)mod n +1
- 空闲块表
系统为每个磁盘建立一张空闲块表,表中每个登记项记录一组连续空闲块的首块号和块数,空闲块数为“0”的登记项为“空”登记项。 适合采用顺序结构的文件。
| 序号 | 第一个空白块号 | 空白块个数 | 物理块号 |
|---|---|---|---|
| 1 | 2 | 4 | 2、3、4、5 |
| 2 | 9 | 3 | 9、10、11 |
| 3 | 15 | 5 | 15、16、17、18、19 |
| 4 |
- 空闲块链表
1、单块连接
把所有空闲块用指针连接起来,每一个空闲块中都设置一个指向另一个空闲块的指针,所有的空闲块就构成了一个空闲块链。系统设置一个链首指针,指向链中的第一个空闲块,最后一个空闲块中的指针为“0”。 效率较低,麻烦费时。
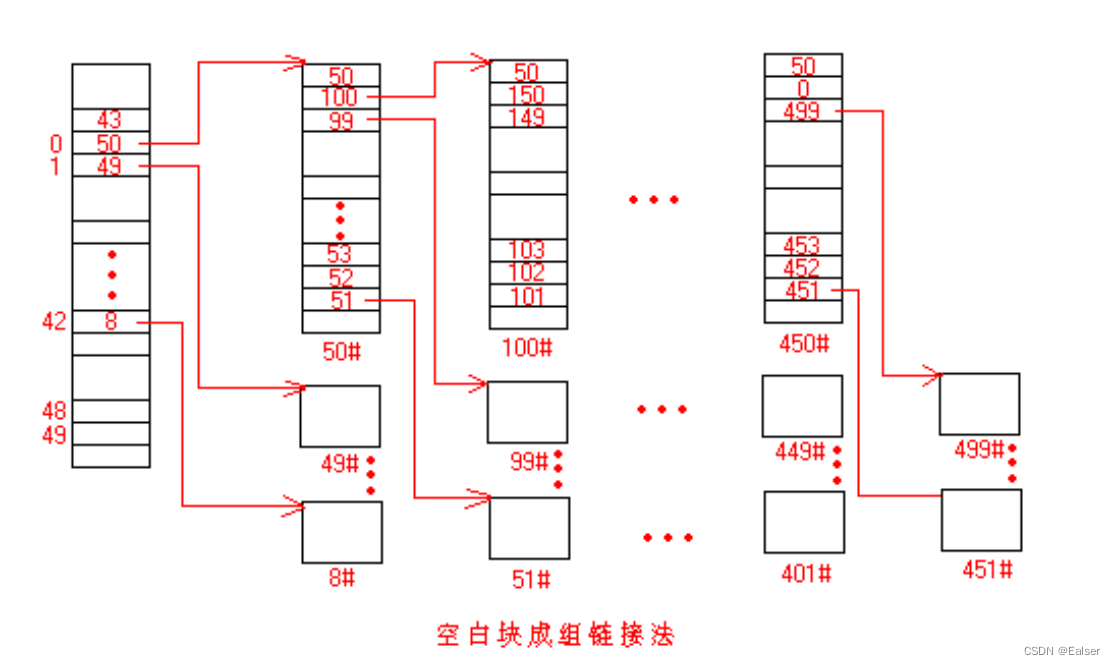
2、成组连接
UNIX 系统:采用空闲块成组连接的方法。
采用成组连接后,分配回收磁盘块时均在内存中查找和修改,只是在一组空闲块分配完或空闲的磁盘块构成一组时才启动磁盘读写。比单块连接方式效率高。
7.6 文件的共享和保护
7.6.1 文件存取控制
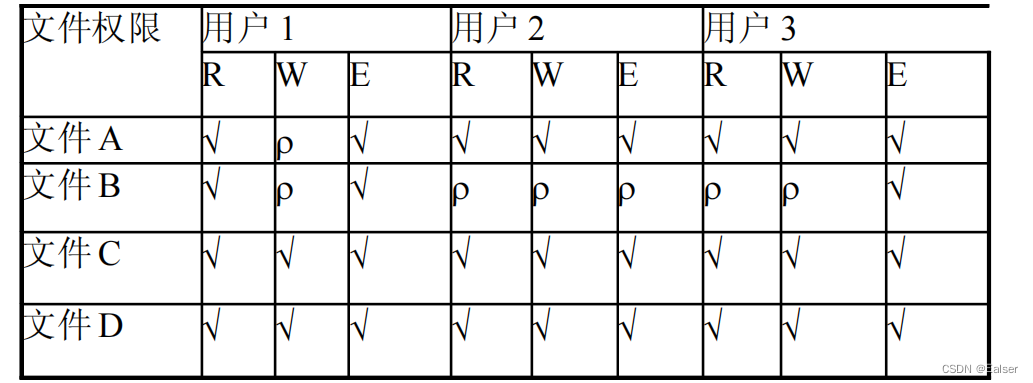
- 存取控制矩阵
如下图,记录所有用户对所有文件的使用权限。缺点:占用较大空间;查找速度慢
- 存取控制表
对存取控制矩阵改进,将用户进行分组。对一个文件而言,针对文件所有者,即其所在的各个用户组规定不同的存取权限,从而形成该文件的存取控制表。它比存取控制矩阵规模要小得多。
| 用户 | 文件权限 |
|---|---|
| 文件所有者 | RWE |
| 用户组 A | RW |
| 用户组 B | RE |
| 其他 | R |
- 口令
对文件规定一个口令,放在文件说明中,并规定使用该文件的用户。当用户访问文件时,必须提供口令。验证正确后,才能访问。 - 加密
对文件中所有信息以密码形式重新编码存储,在读文件时,再进行译码解密。通常做法是:在用户向外存写入一个文件时,通过一个加密程序对文件的信息进行变化处理。读取文件时,通过一个解密程序把文件恢复原貌。
7.6.2 文件共享的实现方法
- 基于索引结点的共享方式:
引用索引结点,即诸如文件的物理地址及其它的文件属性等信息,不再放在目录中,而是放在索引结点中。在文件目录中只设置文件名及指向相应索引结点的指针,如右图所示。
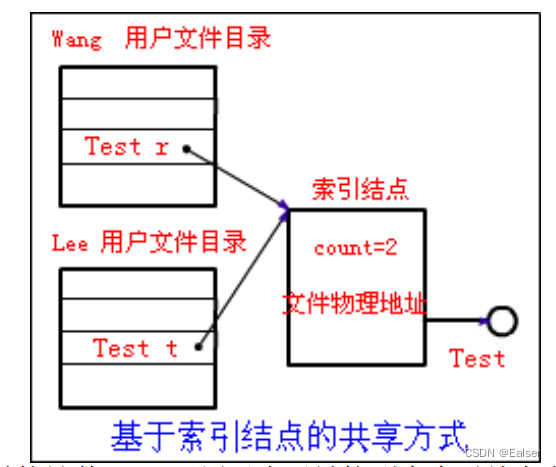
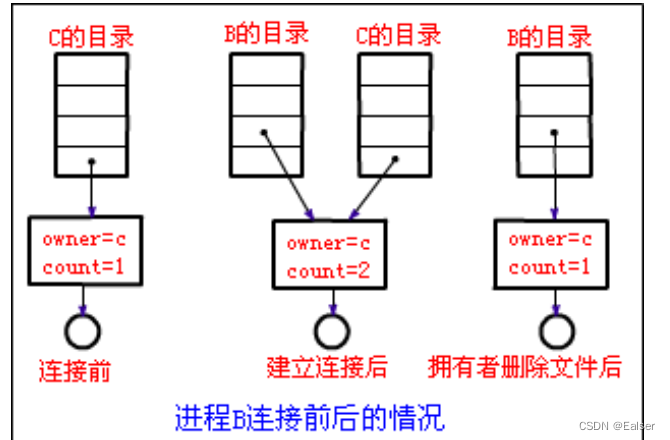
在索引结点中还应有一个链接计数 count,用于表示链接到本索引结点上的用户目录项的数目。当用户创建一个新文件时,他是该文件的所有者,此时将 count 置 1。当有用户 B 要共享此文件时,在用户 B 的用户目录中增加一目录项,并设置一指针指向该文件的索引结点,此时,文件主仍然是 C,count=2。如果用户 C 不再需要此文件,是不能将文件删除的,因为删除了该文件,也必删除了该文件的索引结点。
- 符号链实现文件共享 符号链实现文件共享:
B 为了共享 C 的一个文件 F,可以由系统创建一个 LINK 类型的新文件,将新文件 F 写入 B 的用户目录中,以实现 B 的目录文件与文件 F 的链接。在新文件中只包含被链接文件 F 的路径名,称这样的链接方法为符号链接;
7.6.3 文件的备份转储
通过转储技术,定期将全部或部分文件转存在磁带、光盘作为备份。常用的转储方法有两种:全量转储、增量转储。
全量转储:把文件系统中所有文件,定期复制在磁带上。 增量转储:仅把修改过的文件和新建立的文件转储在磁带上。
这篇关于<Linux>(极简关键、省时省力)《Linux操作系统原理分析之文件管理(3)》(24)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







