本文主要是介绍【Trino权威指南(第二版)】Trino介绍:trino解决大数带来的问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一. 大数据带来的问题
- 二. Trino来救场
- 1. 为性能和规模而生
- 2. SQL-on-Anything
- 3. 数据存储与查询计算资源分离
- 三. Trino使用场景
一. 大数据带来的问题
数据现状
数据存储机制日益多样:关系型数据库、NoSQL数据库、文档数据库、键值存储和对象存储系统等。对于当今的组织结构,它们当中很多是必备的,只使用其中一种已经不够了。
数据分散在各个孤岛上,对有些数据的查询无法满足分析所需的必要性能。其他系统则将数据存储在单一庞大的系统上,因而不能像现代的云应用程序一样横向扩展。
大数据带来的问题
数仓的笨拙
- 对全世界的组织来说,创建和维护大型专用数据仓库的传统方法成本高昂。 通常,对很多用户和使用模式来说,这种方法也显得缓慢且笨拙。
- 有些分析不需要数仓、或者有些业务库不开放为数仓。
数据的持续分布导致增加数据处理的难度
- 通常被考虑作为解决方案的数据湖,要么成了无人问津的数据倾倒场,要么需要带着巨大的痛苦艰难地尝试才能对它做数据分析。
- 作为新方法的数据湖仓,尽管它可以融合数据仓库和数据湖两者的优点,但也不是唯一的解决方案。数据将持续分布,存储在各个地方,并将出现越来越多的系统。
二. Trino来救场
Trino能解决上述所有问题。通过支持不同系统上的联邦查询、并行查询和横向集群扩展等功能,它为我们提供了新的机会。
Trino是一个开源的分布式SQL查询引擎,是为了高效查询不同系统和各种规模(从GB级到PB级)的数据源而从头开始设计和编写的一套系统。
1. 为性能和规模而生
- 如果有TB级乃至PB级的数据需要查询,你可能会使用Apache Hive等工具。与这些工具相比,Trino可以更高效地查询数据。分析师应该使用Trino,因为他们期望SQL查询可以在几毫秒(实时数据分析)、几秒或几分钟内返回结果。
- Trino支持SQL,通常用在数据仓库、数据分析、海量数据聚合和生成报告等任务上,这些任务通常被归类为联机分析处理(OnLine Analytical Processing,OLAP)。
- 尽管Trino能理解并高效地执行SQL,但它并不是一个数据库,因为它并不包含自己的数据存储系统。此外,Trino也不适用于联机事务处理(OnLine Transaction Processing,OLTP)。
Trino同时使用了众所周知的技术和新颖的技术来执行分布式查询。这些技术包括
- 内存并行处理
- 跨集群节点管线执行
- 多线程执行模型(以保持所有CPU核心被充分利用)
- 高效的扁平内存数据结构(以最小化Java的垃圾回收和Java字节码生成)
借助上述技术,Trino用户可以以比其他方案更低的成本更快地获得查询结果。
2. SQL-on-Anything
- Trino是一个查询引擎,可以从对象存储系统、关系型数据库管理系统(RDBMS)、NoSQL数据库和其他系统中查询数据。Trino几乎可以查询任何东西,是一个真正的SQL-on-Anything系统。
- Trino在原地查询数据,无须事先将数据迁移集中到某个位置。(优于数仓?)无论数据存放在何处,Trino都可以查询,因此它可以取代传统、昂贵和笨重的提取-变换-加载(ETL)过程,或者至少为某些现代化高效ETL工具(例如,dbt)。
- 有了Trino,用户甚至可以用相同的SQL在不同的系统之间进行查询。
3. 数据存储与查询计算资源分离
- Trino没有自己的存储,它只是在数据所在之处进行查询处理。使用Trino时,存储和计算是分离的,它们可以各自独立地扩展。
- Trino代表计算层,底层的数据源代表存储层。这使得Trino可以基于对数据的分析需求来扩展和缩减计算资源。无须移动数据或根据当前查询的需求预设计算资源和存储资源,也无须随着查询需求的变化来定期变更资源的分配。Trino可以通过动态扩展计算集群来扩展查询能力。借助这一特性,你可以极大地优化硬件资源需求并降低成本。
三. Trino使用场景
- 单一的SQL分析访问点
你可以从Trino这里访问所有数据库。所有的仪表盘和分析工具以及其他商业智能系统,都可以指向一个系统——Trino,它可以访问组织当中的所有数据。
2.数据仓库和数据源系统的访问点
- Trino允许你添加任何数据仓库作为数据源,就像其他关系型数据库一样。如果你想深入研究数据仓库的查询,可以在Trino里直接完成。
- 你也可以在这里访问数据仓库及其源数据库系统,甚至可以将它们组合在一起编写一个SQL语句来查询。Trino让你可以使用单个系统查询任何数据库(包括数据仓库、源数据库)。
3.提供对任何内容的SQL访问
Trino允许你将它作为一个数据源,用来对接各类系统。这些系统可以使用标准的ANSI SQL来查询相关的数据。
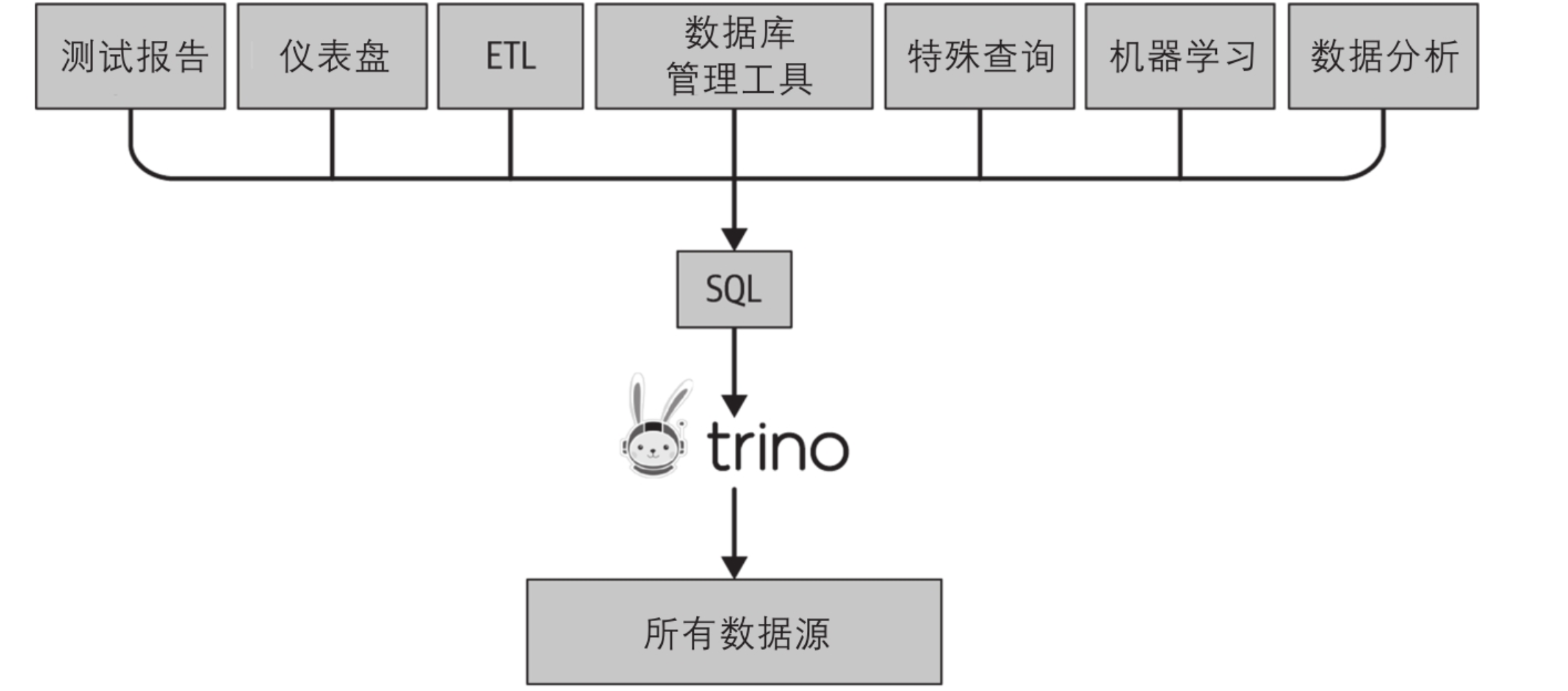
- 联邦查询
联邦查询是在一个语句中引用并使用不同数据库和模式(schema)的SQL查询。在Trino中可以用同一条SQL语句,在同一时间查询出来自完全不同的系统的数据。
5.虚拟数据仓库的语义层
- Trino可用作虚拟数据仓库。使用这一工具和标准ANSI SQL,你就可以定义语义层。一旦所有的数据库都设置成Trino的数据源,你就可以查询它们。
- Trino提供了查询这些数据库所需的计算能力。使用SQL和Trino支持的函数与运算符,你可以直接从数据源获得想要的数据。在使用数据进行分析之前,无须复制、移动或转换它们。
- 数据湖查询引擎
- 数据湖通常指的是一个巨大的HDFS或类似的分布式对象存储系统,在数据被存储到这些存储系统时,并没有特别考虑接下来应该如何访问它们。Trino可以使它们成为有用的数据仓库。
- Delta Lake和Iceberg等新表格式极大地提高了数据湖的可用性,以至于产生了新的术语——数据湖仓(湖仓一体)。有了Delta Lake和Iceberg连接器,Trino是查询这些数据湖仓的首选。
- 更快的响应带来更好的洞见
Trino在设计上避免了数据复制。Trino的并行计算和深度优化通常能为你的数据分析带来性能提升。如果原来需要3天的查询现在只需15分钟就可以完成。
- SQL转换和ETL、大数据、机器学习和人工智能
《Trino权威指南(第二版)》
这篇关于【Trino权威指南(第二版)】Trino介绍:trino解决大数带来的问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








