本文主要是介绍我不是DBA之慢SQL诊断方式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近经常遇到技术开发跑来问我慢SQL优化相关工作,所以干脆出几篇SQL相关优化技术月报,我这里就以公司mysql一致的5.7版本来说明下。
在企业中慢SQL问题进场会遇到,尤其像我们这种ERP行业。
成熟的公司企业都会有晚上的慢SQL监控和预警机制。不需要我们技术人员过多关注慢SQL的产生和收集,自然会有管理人员通知下来。一般来说慢SQL监控通常都是利用slowlog来实现的,这个比较简单:
mysql 默认是关闭slowlog的,不记录管理语句,也不记录不使用索引进行查找的查询,毕竟这也是一个额外的损耗。最小值和默认值long_query_time分别为 0 和 10。
可以查看是否开启了slowlog:
show variables like '%slow_query_log%';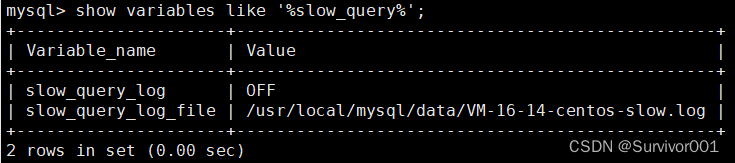
如果需要开启可以执行语句:或者去配置文件添加配置
set global slow_query_log=1;这里就不再展示了,毕竟我们不是DBA。
那么发现了慢SQL之后怎么去定位问题?在mysql官网文档中性能问题诊断分析有提供分析方式。
1、慢SQL诊断SHOW PROFILES
mysql提供了show profiles和show profile语句提供的分析信息相当的数据,但是需要注意的是在未来的mysql中会弃用当前语句功能,使用性能模式performance_schema来替换,从8.0版本文档中确实没有看到这个语句了,但是听别说依旧可以使用,这个先不管了,反正目前看来mysql5.7在23年10月还在更新维护,那就没什么好说的。
确定当前版本是否支持show profiles
select @@have_profiling;
如果支持那就开启下:(这种是临时开启,启动后会重置)
set profiling=1;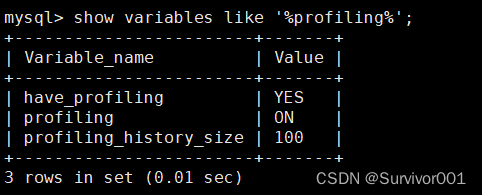
其他内容就不多说了,简单玩意,默认size是15,我这里调成了最大100。
2、已知执行SQL,诊断性能
如果现在你已经知道慢SQL是哪个了,就可以通过profiling来进行诊断。
比如当执行完SQL后,可以通过show profiles来显示发送到服务器的最新语句的列表(除了他自己)。

接下来就可以通过show profile T for ID 来显示有关单个语句的详细信息。
show profile for query 19;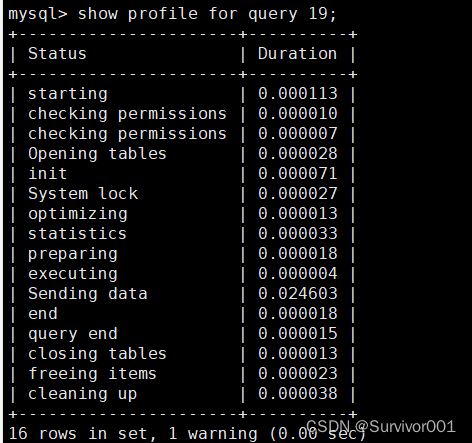
这里先对show profile语句做个简单的介绍:show profile T for ID
type可以指定 可选值来显示特定的附加类型的信息:ALL显示所有信息BLOCK IO显示块输入和输出操作的计数CONTEXT SWITCHES显示自愿和非自愿上下文切换的计数CPU显示用户和系统CPU使用时间IPC显示发送和接收的消息计数MEMORY目前尚未实施PAGE FAULTS显示主要和次要页面错误的计数SOURCE显示源代码中函数的名称,以及函数所在文件的名称和行号SWAPS显示交换计数比如你先查看当前SQL执行时CPU的情况,就可以show profile CPU for query 19,可以显示在各个阶段CPU的消耗。具体的使用可以根据需要来定。
对于show profile的结果,比较重要,这是我们诊断SQL问题的关键。返回内容比较多,都是SQL整个执行过程,我们也不需要关注所有的内容:
System lock
确认是由于哪个锁引起的,通常是因为MySQL或InnoDB内核级的锁引起的。
建议:如果耗时较大再关注即可,一般情况下都还
Sending data
解释:【数据收集|检索+发送】该线程正在读取和处理语句的行 select,并将数据发送到客户端。由于在此状态期间发生的操作往往会执行大量磁盘访问(读取),因此它通常是给定查询生命周期中运行时间最长的状态。
建议:一般当前步骤耗时久,就是SQL本身的效能问题,可以通过做响应的优化手段,比如索引优化提高检索效率、分页控制数据量等等。
Sorting result
正在对结果进行排序,类似Creating sort index,不过是正常表,而不是在内存表中进行排序
建议:一般在无索引order by、groupby都会有这样的步骤产生,如果当前阶段耗时久,可以考虑做一些索引优化来避免sort动作,或者进行数据量控制。
Sending to client服务器正在向客户端写入数据包。
Writing to netMySQL 5.7.8之前 称为此状态
create sort index
当前的SELECT中需要用到临时表在进行ORDER BY排序
建议:一般在无索引order by、groupby都会有这样的步骤产生,如果当前阶段耗时久,可以考虑做一些索引优化来避免sort动作,或者进行数据量控制
Creating tmp table
创建临时表。先拷贝数据到临时表,用完后再删除临时表。消耗内存,数据来回拷贝删除,消耗时间。
建议:比如groupby或者一些子查询会产生当前步骤,可以通过优化索引来避免
converting HEAP to MyISAM
查询结果太大,内存不够,数据往磁盘上搬了。
建议:优化索引或着数据量优化,可以调整max_heap_table_size
Copying to tmp table on disk
把内存中临时表复制到磁盘上,危险!!!
建议:优化索引,可以调整tmp_table_size参数,增大内存临时表大小
上面列举一些常见内容项,详细的可以查看官网中资料(processlist):MySQL :: MySQL 5.7 Reference Manual :: 8.14.3 General Thread States d
处理一般线程state,官网还介绍了缓存、I/O线程状态等等。虽然内容是show processlist的,但是也适用于当前
到这里基本上就可以大致有个慢SQL诊断结果了,如果SQL本身需要优化,就可以做响应的执行进化分析过程。
3、线上问题分析定位
如果线上存在正在执行慢SQL,可以通过线程集来定位show processlist
比如当前线上正在慢SQL执行中:

这样可以知道当前执行中的SQL当前自行过程中的状态,注意这个时实时的,所以可以通过多次观察来看耗时的步骤,比如当前SQL在sending to client持续时间很久,说明数据量很大,导致传输给客户端效率慢。
同时也可以通过explain connection for ID 来查看当前SQL执行计划:
explain for connection 99;
好了,诊断问题完成了,接下来就是具体的SQL分析和优化了。
这篇关于我不是DBA之慢SQL诊断方式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







