本文主要是介绍KRaft使用SASL_PLAINTEXT进行认证,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
需要有KRaft相关的基础,才行。可参阅之前学习记录Kafka
一、配置
首先需要了解SASL的含义,SASL全称为Simple Authentication and Security Layer,它主要是用于在客户端和服务器之间提供安全的身份验证机制。
Kafka 支持以下几种 SASL 验证机制如下
- GSSAPI (Kerberos)
- PLAIN
- SCRAM-SHA-256
- SCRAM-SHA-512
- OAUTHBEARER
其中,PLAIN相对来说更简单,本文就记录SASL/PLAIN的配置与使用。
1.1 配置单机SASL/PLAIN认证
安装的过程参考一键安装的脚本,安装好Kafka后,按照如下操作进行配置
1.) 创建kafka_server_jaas.conf
KafkaServer {org.apache.kafka.common.security.plain.PlainLoginModule requiredusername="admin"password="admin-secret"user_admin="admin-secret"user_alice="alice-secret";
};
user_admin="admin-secret"表示用户名admin,对应的密码为admin-secret。user_alice同理。
username和password表示节点建立集群时,需要验证的身份信息,只有验证通过的节点,方能成功建立集群。
2.)进入到kafka的bin路径中, 复制一份kafka-server-start.sh出来。
cp kafka-server-start.sh kafka-server-start-jaas.sh
并修改复制出来的文件,添加三行。
if [ "x$KAFKA_OPTS" ]; thenexport KAFKA_OPTS="-Djava.security.auth.login.config=/root/kafka_server_jaas.conf"
fi
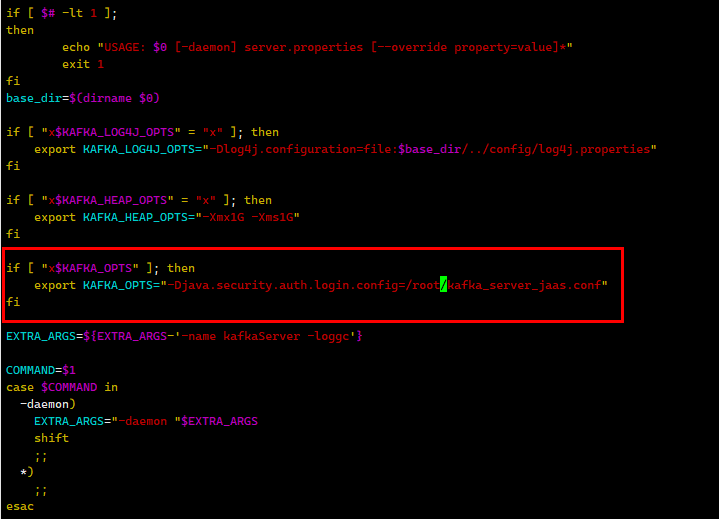
3.) 将config/kraft/server.properties再复制一份。
cp server.properties server.jaas.properties
并修改复制出来的文件,修改参数如下。其中advertised.listeners中的ip要改为实际使用的ip地址。
sasl.enabled.mechanisms=PLAIN
sasl.mechanism.inter.broker.protocol=PLAINlisteners=SASL_PLAINTEXT://:9092,CONTROLLER://:9093
inter.broker.listener.name=SASL_PLAINTEXT
advertised.listeners=SASL_PLAINTEXT://10.0.0.10:9092
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
其中,listener.security.protocol.map的格式为{别名}:{监听器类型},配置了别名,那么在配置listeners时,就可以通过{别名}://:{端口}来进行配置。前缀为 SASL 的两个参数是新增的,目的是为了配置 SASL 认证,其表示的含义如下
sasl.enabled.mechanisms:指定Kafka进行SASL验证的机制。PLAIN表示使用文本验证。sasl.mechanism.inter.broker.protocol:指定broker之间通信所使用的SASL验证的机制。PLAIN表示使用文本验证。
Kafka支持不同的监听器类型,如下
| 监听器类型 | 数据加密 | 身份验证 | 适用场景 |
|---|---|---|---|
| PLAINTEXT | —— | —— | 内网环境、安全性有保障 |
| SSL/TLS | SSL/TLS | —— | 在公网传输敏感数据 |
| SASL_PLAINTEXT | —— | SASL | 需要身份验证但不需要数据加密的环境 |
| SASL_SSL | SSL/TLS | SASL | 安全性要求极高的环境 |
4.) 启动
格式化集群信息,并启动
/root/kafka_2.13-3.3.1/bin/kafka-storage.sh format -t T1CYXg2DQPmdSYSUI-FNFw -c /root/kafka_2.13-3.3.1/config/kraft/server.jaas.properties
/root/kafka_2.13-3.3.1/bin/kafka-server-start-jaas.sh /root/kafka_2.13-3.3.1/config/kraft/server.jaas.properties
会了单节点的配置,集群的配置只是简单调下参数,不过还是记录一下。
具体的配置参阅1.2即可。
1.2 配置集群SASL/PLAIN认证
准备三台机器
- 10.0.0.101
- 10.0.0.102
- 10.0.0.102
按照单机Kafka的配置步骤进行配置,但是在第三步时,略有调整。
10.0.0.101的示例配置文件如下。每个节点中,需要单独修改三个参数,分别为node.id、controller.quorum.voters、advertised.listeners。
process.roles=broker,controller
node.id=1
controller.quorum.voters=1@10.0.0.101:9093,2@10.0.0.102:9093,3@10.0.0.103:9093
listeners=SASL_PLAINTEXT://:9092,CONTROLLER://:9093
sasl.enabled.mechanisms=PLAIN
sasl.mechanism.inter.broker.protocol=PLAIN
inter.broker.listener.name=SASL_PLAINTEXT
advertised.listeners=SASL_PLAINTEXT://10.0.0.101:9092
controller.listener.names=CONTROLLER
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
其中node.id表示节点的编号,controller.quorum.voters表示集群中的所有具有controller角色的节点,其配置格式为{node.id}@{ip}:{port}。
在三节点上均执行如下命令
/root/kafka_2.13-3.3.1/bin/kafka-storage.sh format -t T1CYXg2DQPmdSYSUI-FNFw -c /root/kafka_2.13-3.3.1/config/kraft/server.jaas.properties
/root/kafka_2.13-3.3.1/bin/kafka-server-start-jaas.sh /root/kafka_2.13-3.3.1/config/kraft/server.jaas.properties
启动后日志如图。
1.3 client接入授权
1.) 如果kafka未开启身份认证
./kafka-consumer-groups.sh --bootstrap-server 10.0.0.101:9092 --describe --all-groups
2.) 如果kafka开启了身份认证,则需要创建存储身份认证的文件kafka.properties
security.protocol: SASL_PLAINTEXT
sasl.mechanism: PLAIN
sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="alice" password="alice-secret";
之后再执行命令
./kafka-consumer-groups.sh --bootstrap-server 10.0.0.101:9092 --describe --all-groups --command-config ./kafka.properties
1.4 集群为何是奇数
常见的分布式一致性算法
- Paxos
- Raft
KRaft全称为Kafka Raft,是基于Raft算法实现的分布式副本管理协议。
Raft的多数派原则,规定了集群的建立无需全员存活,只要存活多数(n个节点,存活节点数>n/2)即可视为集群为正常状态。
这个规定解决了集群中出现的脑裂问题。
比如4台节点组成的集群,其中2台为上海机房,另外2台为北京机房,当上海与北京的网络出现故障,那么一个集群就会分裂为2个集群,这就是脑裂现象。
由于这个规定,导致集群中n台和n+1台节点,他们的容灾能力是一样的(n为奇数),都只能坏一台。使用奇数个节点反而能节省资源。
二、监控
2.1 监控组件比较
常见的Kafka监控如下
- CMAK (previously known as Kafka Manager)
- 优点:监控功能更强大
- 缺点:a. 重量级 b. 不支持KRaft,参考Kafka 3.3.1 with KRaft Support · Issue #898 · yahoo/CMAK
- kafdrop
- 优点:a. 轻量,开箱即用 b. 支持KRaft
- 缺点:a. 实时性监控并不好 b. 交互做得并不好,当节点开启身份验证时,会存在严重卡顿情况
2.2 kafdrop使用
首先下载Release 4.0.1 · obsidiandynamics/kafdrop
执行命令,启动监控
java -jar kafdrop-4.0.1.jar --kafka.brokerConnect=10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092
kafdrop本身是一个springboot项目,对于javaer来说是很有好的。其他一些复杂的配置,可以直接下载源码查看application.yml
# 省略以上若干配置。详细内容可自行查看
kafka:brokerConnect: localhost:9092saslMechanism: "PLAIN"securityProtocol: "SASL_PLAINTEXT"truststoreFile: "${KAFKA_TRUSTSTORE_FILE:kafka.truststore.jks}"propertiesFile : "${KAFKA_PROPERTIES_FILE:kafka.properties}"keystoreFile: "${KAFKA_KEYSTORE_FILE:kafka.keystore.jks}"
“${KAFKA_PROPERTIES_FILE:kafka.properties}”
表示获取环境变量KAFKA_PROPERTIES_FILE,如果存在则使用环境变量值,否则使用默认值kafka.properties
比如我开启了授权,那么需要再kafdrop的同级目录下创建kafka.properties,然后再次启动。
security.protocol: SASL_PLAINTEXT
sasl.mechanism: PLAIN
sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="alice" password="alice-secret";
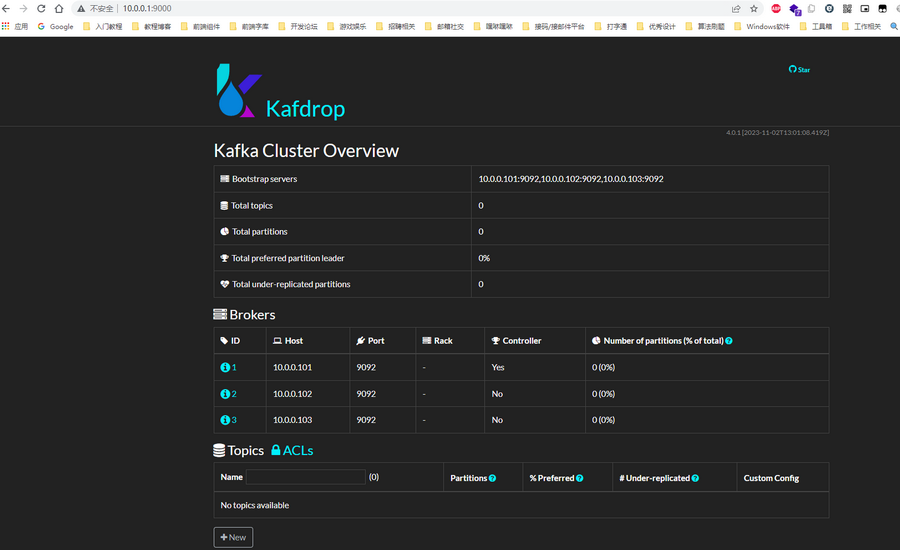
最终kafdrop监控效果如图。
三、使用
3.1 SpringKafka
3.1.1 使用
创建springboot项目,添加依赖
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId>
</dependency>
生产者application.yml配置
spring:kafka:
# bootstrap-servers: 10.0.0.101:9092bootstrap-servers: 10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092# 接入授权properties:security.protocol: SASL_PLAINTEXTsasl.mechanism: PLAINsasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="alice" password="alice-secret";producer:key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer
消费者application.yml配置
spring:kafka:
# bootstrap-servers: 10.0.0.10:9092bootstrap-servers: 10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092# 接入授权properties:security.protocol: SASL_PLAINTEXTsasl.mechanism: PLAINsasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="alice" password="alice-secret";consumer:key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializergroup-id: group # 默认的分组名,消费者都会有所属组
源码参考kafka-cluster-demo/spring-kafka-demo at master · meethigher/kafka-cluster-demo
3.1.2 重试机制
关于SpringKafka的重试机制,未进行深入探索,只参考了文章Spring Kafka:Retry Topic、DLT 的使用与原理 - 知乎。
感觉这篇文章讲得很透彻了。按照该文章的说明,验证了以下两种重试策略
- 默认重试策略
- 自定义重试策略
默认重试策略
快速重试10次,无间隔时间,如果最后还是失败,则自动commit。
@KafkaListener(topics = "test-retry")
public void test(ConsumerRecord<?, ?> record, Consumer<?, ?> consumer) {int i=1/0;
}
不需要额外配置,这是默认的重试策略。
自定义重试策略
Spring单独提供了RetryableTopic注解,及重试后的回调注解DltHandler。底层逻辑是新建了topic对这些失败的数据进行存储,以及监听这些新建的topic再进行消费,细节的话还是参考文章Spring Kafka:Retry Topic、DLT 的使用与原理 - 知乎。
@KafkaListener(topics = "test-retry")
@org.springframework.kafka.annotation.RetryableTopic(attempts = "5", backoff = @org.springframework.retry.annotation.Backoff(delay = 5000, maxDelay = 10000, multiplier = 2))
public void test(ConsumerRecord<?, ?> record, Consumer<?, ?> consumer) {int i = 1 / 0;
}@DltHandler
public void listenDlt(String in, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic,@Header(KafkaHeaders.OFFSET) long offset) {log.error("DLT Received: {} from {} @ {}", in, topic, offset);
}
更多的案例可以参考spring-kafka/samples at main · spring-projects/spring-kafka
3.2 KafkaClient
添加依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.3.1</version>
</dependency>
生产者示例
import org.apache.kafka.clients.producer.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.util.Properties;public class Producer {private static Logger log = LoggerFactory.getLogger(Producer.class);public static void main(String[] args) throws Exception {// 配置生产者属性Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092");props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// 配置 SASL_PLAINTEXT 认证props.put("security.protocol", "SASL_PLAINTEXT");props.put("sasl.mechanism", "PLAIN");props.put("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"alice\" password=\"alice-secret\";");// 创建生产者实例KafkaProducer<String, String> producer = new KafkaProducer<>(props);// 发送消息到指定主题String topic = "meethigher";String key = "timestamp";while (true) {// 发送消息String value= String.valueOf(System.currentTimeMillis());ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);producer.send(record, (metadata, exception) -> log.info("sent key={},value={} to topic={},partition={}", record.key(), record.value(), metadata.topic(), metadata.partition()));System.in.read();}// 关闭生产者
// producer.close();}
}
消费者示例
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.time.Duration;
import java.util.Collections;
import java.util.Properties;public class Consumer {private static final Logger log = LoggerFactory.getLogger(Consumer.class);public static void main(String[] args) {// 配置消费者属性Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "10.0.0.101:9092,10.0.0.102:9092,10.0.0.103:9092");props.put(ConsumerConfig.GROUP_ID_CONFIG, "your_consumer_group");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");// 配置 SASL_PLAINTEXT 认证props.put("security.protocol", "SASL_PLAINTEXT");props.put("sasl.mechanism", "PLAIN");props.put("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"alice\" password=\"alice-secret\";");// 创建消费者实例KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);// 订阅主题String topic = "meethigher";consumer.subscribe(Collections.singletonList(topic));// 消费消息while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));records.forEach(record -> {log.info("Consumed record with key {} and value {}", record.key(), record.value());});}}
}
四、参考致谢
Apache Kafka
spring-projects/spring-kafka: Provides Familiar Spring Abstractions for Apache Kafka
Listeners in KAFKA
kafka+Kraft模式集群+安全认证_kafka认证机制_鸢尾の的博客-CSDN博客
我的 Kafka 旅程 - SASL+ACL 认证授权 · 配置 · 创建账号 · 用户授权 · 应用接入 - Sol·wang - 博客园
从k8s集群主节点数量为什么是奇数来聊聊分布式系统 - 知乎
万字长文解析raft算法原理 - 知乎
Spring Kafka:Retry Topic、DLT 的使用与原理 - 知乎
这篇关于KRaft使用SASL_PLAINTEXT进行认证的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




