本文主要是介绍Hdoop学习笔记(HDP)-Part.14 安装YARN+MR,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
Part.01 关于HDP
Part.02 核心组件原理
Part.03 资源规划
Part.04 基础环境配置
Part.05 Yum源配置
Part.06 安装OracleJDK
Part.07 安装MySQL
Part.08 部署Ambari集群
Part.09 安装OpenLDAP
Part.10 创建集群
Part.11 安装Kerberos
Part.12 安装HDFS
Part.13 安装Ranger
Part.14 安装YARN+MR
Part.15 安装HIVE
Part.16 安装HBase
Part.17 安装Spark2
Part.18 安装Flink
Part.19 安装Kafka
Part.20 安装Flume
十四、安装YARN+MR
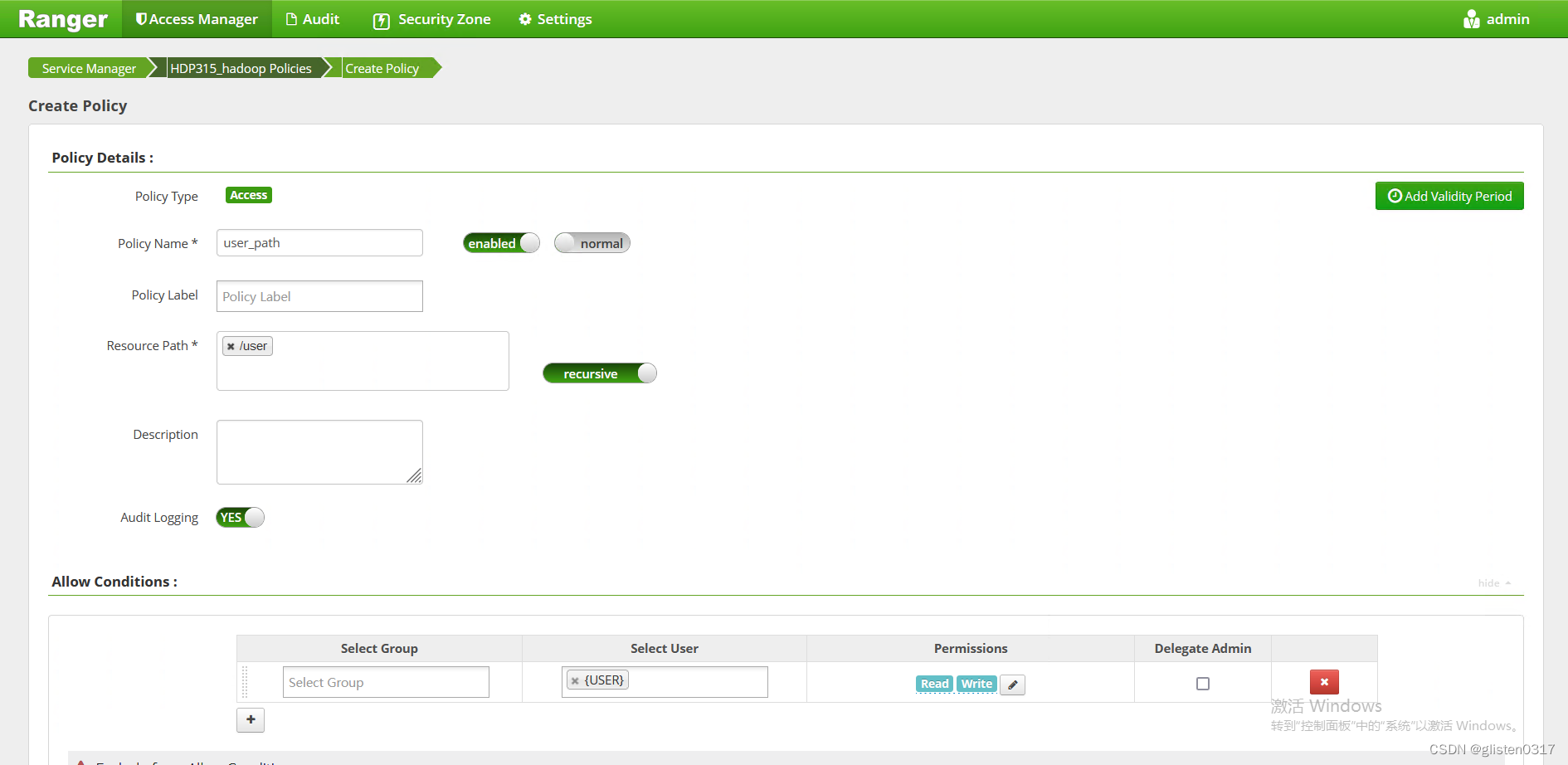
1.MR中间结果存储权限
使用Yarn提交MapReduce任务的时候,中间结果会保存在HDFS,/user/username/,如果/user目录下用户目录下不存在,则被创建,当MR执行结束之后,中间结果会被删除,目录保留。因此需要在Ranger中对/user的权限做策略。
2.安装服务
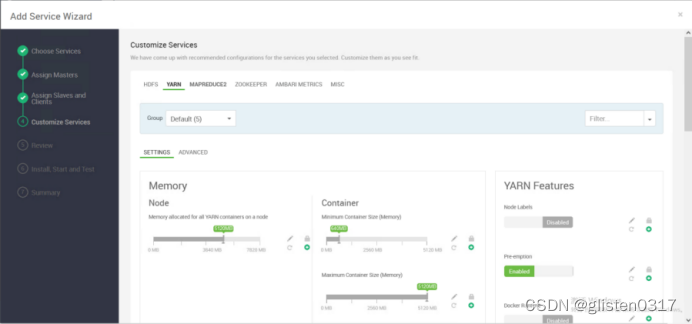
YARN的部分存储路径调整:
Node Manager
YARN NodeManager Local directories:/data01/hadoop/yarn/local
YARN NodeManager Log directories:/data01/hadoop/yarn/log
Application Timeline Server
yarn.timeline-service.leveldb-state-store.path:/data01/hadoop/yarn/timeline
yarn.timeline-service.leveldb-timeline-store.path:/data01/hadoop/yarn/timeline
Advanced yarn-hbase-env
is_hbase_system_service_launch:true
use_external_hbase:false
YARN可使用内置的HBase数据库,也可以使用外部;使用内置时,需要is_hbase_system_service_launch设置为true
Advanced ranger-yarn-security
Add YARN Authorization:取消勾选
该选项是禁用YARN本身的ACL权限控制,YARN队列的权限控制由RANGER统一管理
注:需要先对NameNode页面的认证取消了,否则ResourceManager修改后也不生效
MAPREDUCE2的部分存储路径调整:
Advanced mapred-site
mapreduce.jobhistory.recovery.store.leveldb.path:/data01/hadoop/mapreduce/jhs
Custom mapred-site
mapred.local.dir:/data01/hadoop/mapred
3.ResourceManager HA
(1)启用HA
在ACTIONS->Enable ResourceManager HA中配置
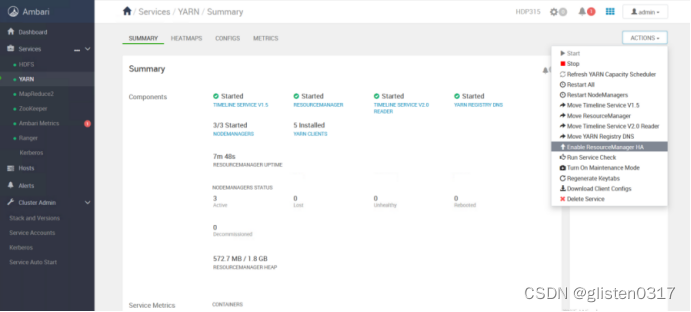
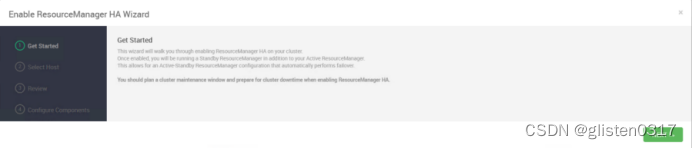
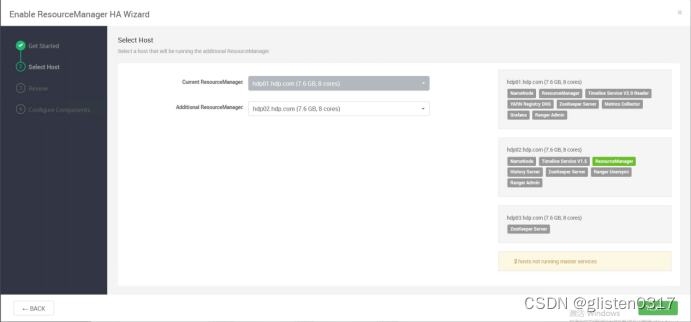
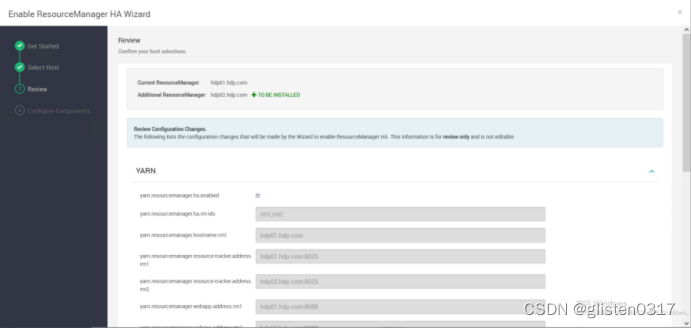
(2)确认配置文件
启用HA后,会在/etc/hadoop/conf/yarn-site.xml中出现如下关于HA的配置项
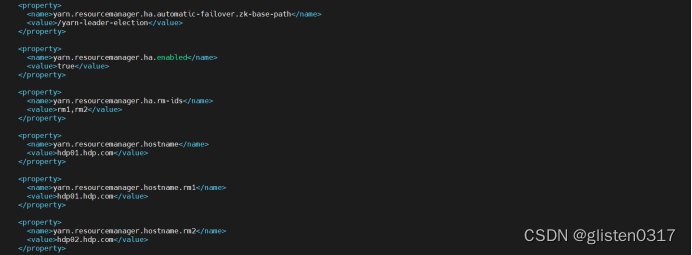
指定zk下对应的文件目录为/yarn-leader-election,对应的rm节点为hdp01.hdp.com和hdp02.hdp.com
在zookeeper中查看也同样生成了对应的文件目录

(3)确认YARN、MR2配置
①CPU资源调度
目前的CPU被划分为虚拟CPU,这里的虚拟CPU是yarn自己引入的概念,因为每个服务器的CPU计算能力不一样,有的机器可能是其他机器计算能力的两倍,然后可以通过多配置几个虚拟CPU弥补差异。在yarn中,CPU的相关配置如下:
yarn.nodemanager.resource.cpu-vcores
表示该节点上YARN可使用的虚拟CPU个数,默认是8,注意,目前推荐将该值设置为与物理CPU核数数目相同。如果节点CPU核数不够8个,则需要调减小这个值,而YARN不会智能的探测节点的物理CPU总数。
yarn.scheduler.minimum-allocation-vcores
单个任务可申请的最小虚拟CPU个数,默认是1,如果一个任务申请的CPU个数少于该数,则该对应的值改为这个数。
yarn.scheduler.maximum-allocation-vcores
单个任务可申请的最多虚拟CPU个数,默认是4。这里说的cpu个数都是说的虚拟cpu,默认的是1个物理cpu=2个虚拟cpu。
②Memory资源调度
yarn一般允许用户配置每个节点上可用的物理资源,注意,这里是"可用的",不是物理内存多少,就设置多少,因为一个服务器节点上会有若干的内存,一部分给yarn,一部分给hdfs,一部分给hbase。在yarn中,Memory相关的配置如下:
yarn.nodemanager.resource.memory-mb
设置该节点上yarn可使用的内存,默认为8G,如果节点内存资源不足8G,要减少这个值,yarn不会智能的去检测内存资源,一般这个设置yarn的可用内存资源
yarn.scheduler.minimum-allocation-mb
单个任务可申请的最小的内存大小,默认是1G,当内存不够时,会自动按照一定大小累加内存。
yarn.scheduler.maximum-allocation-mb
单个任务最大申请物理内存量,默认为8291MB
③示例
以hdp03-05(8C、8G)为例,
yarn.nodemanager.resource.cpu-vcores 虚拟core
这个参数根据自己生产服务器决定,比如服务器很富裕,那就直接1:1,设置成8,如果服务器不是很富裕,那就直接成1:2,设置成8,本次设置为16
yarn.nodemanager.resource.memory-mb 总内存
生产上一般要预留15-20%的内存,那么可用内存就是8*0.8=6.4G,本次设置为6G
yarn.scheduler.minimum-allocation-mb 单任务最小内存
如果设置成500M,那6/0.5 = 12,就是最多可以跑12个container
如果设置成1G,那6/1 = 6,就是最多可以跑6个container
本次设置为1G
yarn.scheduler.minimum-allocation-vcores 单任务最少vcore
如果设置vcore = 1,那么16/1 = 16,就是最多可以跑16个container,如果设置成这个,根据上面内存分配的情况,最多只能跑6个container,vcore有点浪费
如果设置vcore = 2,那么16/2 = 8,就是最多可以跑8个container
yarn.scheduler.maximum-allocation-vcores 单任务最多vcore
一般就设置成4个,cloudera公司做过性能测试,如果cpu大于等于5之后,cpu利用率反而不是很好(固定经验值)
yarn.scheduler.maximum-allocation-mb 单任务最大内存
这个要根据实际业务设定,如果有大任务
4.测试
(1)创建租户并分配对应的资源队列
跳转至YARN Queue Manager页面,针对之前的租户tenant1和tenant2,新建资源队列,注意所有队列总和要为100%,否则会报错
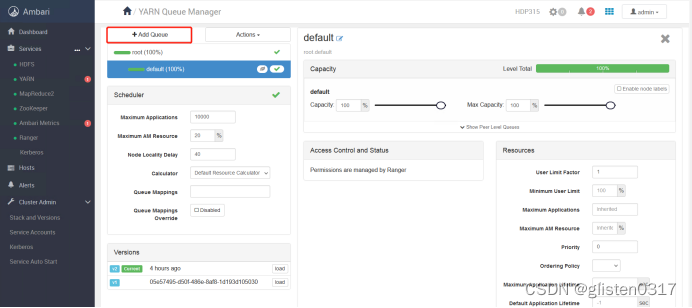
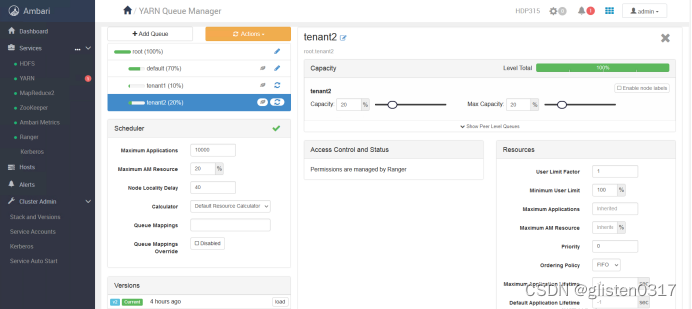
租户与队列资源关系绑定
[u | g] [username : groupname] [yarn队列的名字]
本次绑定为
u:tenant1:tenant1,u:tenant2:tenant2
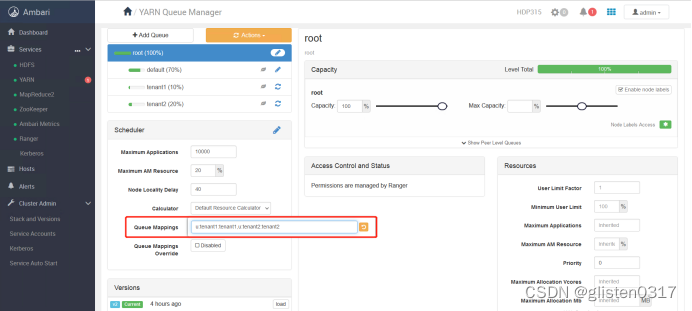
保存本次操作内容
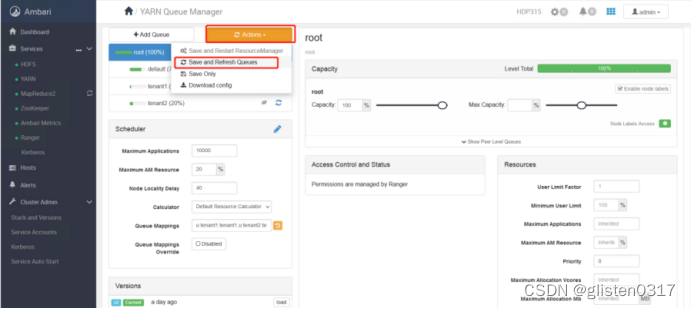
查看resourcemanager页面,可以看到已经更新出新的资源队列
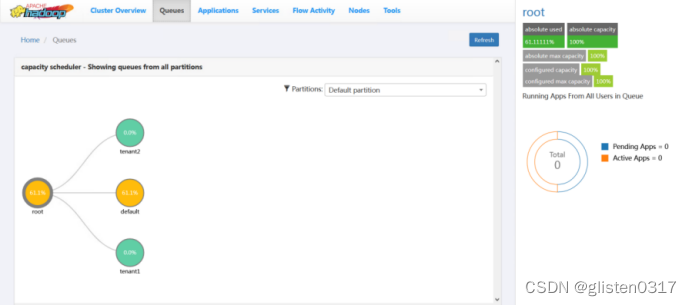
(2)队列使用权限
可使用官方提供的测试jar包
https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-examples
在OpenLDAP中创建账号ranger_yarn,重启UserSync服务后将账号同步至Ranger中,然后在kerberos中创建同样的账号(注:该测试jar包只能用账号ranger_yarn,队列offline)
kadmin.local
addprinc -randkey ranger_yarn
ktadd -kt /root/keytab/ranger_yarn.keytab ranger_yarn
在Yarn中创建队列及账号与队列的映射关系
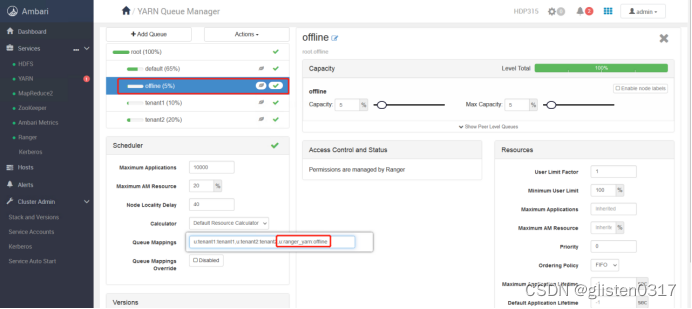
队列offline、账号ranger_yarn都准备好后,在Ranger上创建授权关系
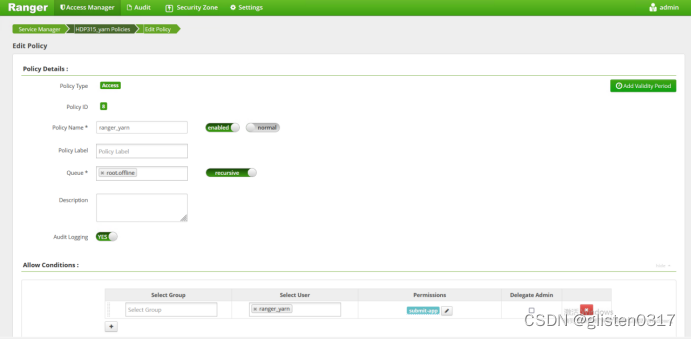
① 计算圆周率
使用ranger_yarn登录,运行计算圆周率任务
kinit -kt /root/keytab/ranger_yarn.keytab ranger_yarn
hadoop jar /root/hadoop-mapreduce-examples-3.1.1.3.0.1.4-1.jar pi -Dmapred.job.queue.name=offline 10 50
hadoop jar是hadoop运行jar包命令
第一个参数pi:表示MapReduce程序执行圆周率计算
第二个参数:用于指定map阶段运行的任务次数,并发度,这是是10
第三个参数:用于指定每个map任务取样的个数,这里是50
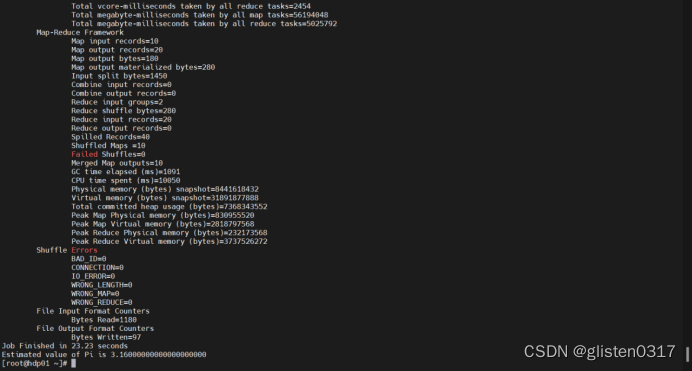
在Yarn中可查看Application的信息
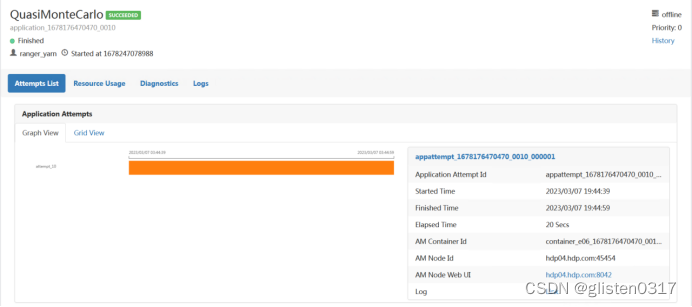
此时在运行jar包时指定队列为tenant1,执行报错,说明权限
② 单词词频统计
首先创建要统计词频的文件,并上传到hdfs上,提前做好对ranger_yarn的hdfs授权
kinit -kt /etc/security/keytabs/nn.service.keytab nn/hdp01.hdp.com@HDP315.COM
hdfs dfs -mkdir /testhdfs/ranger_yarn
kinit -kt /root/keytab/ranger_yarn.keytab ranger_yarn
hdfs dfs -put /root/wordcount_input /testhdfs/ranger_yarn
hdfs dfs -ls /testhdfs/ranger_yarn
运行词频统计jar包
kinit -kt /root/keytab/ranger_yarn.keytab ranger_yarn
hadoop jar /root/hadoop-mapreduce-examples-3.1.1.3.0.1.4-1.jar wordcount -Dmapred.job.queue.name=offline /testhdfs/ranger_yarn/wordcount_input /testhdfs/ranger_yarn/wordcount_output
第一个参数:wordcount表示执行单词统计
第二个参数:指定输入文件的路径
第三个参数:指定输出结果的路径(该路径不能已存在)
统计完成会在输出目录生成结果
hdfs dfs -cat /testhdfs/ranger_yarn/wordcount_output/part-r-00000

5.常用指令
(1)查看命令
yarn application -list
yarn application -list -appStates <ALL,NEW,NEW_SAVING,SUBMITTED,ACCEPTED,RUNNING,FINISHED,FAILED,KILLED>
(2)Kill命令
根据id杀死任务
yarn application -kill <application_id>
(3)查看日志
查询Application日志
yarn logs -applicationId <ApplicationId>
查询Container日志
yarn logs -applicationId -containerId <ApplicationId> -containerId <ContainerId>
(4)查看尝试运行的任务
查看尝试运行的任务
yarn applicationattempt -list<ApplicationId>
查看尝试运行任务的状态
yarn applicationattempt -status <ApplicationAttemptId>
(5)查看容器
列出所有Container
yarn container -list <ApplicationAttemptId>
打印Container状态
yarn container -status <ContainerId>
6.常见报错
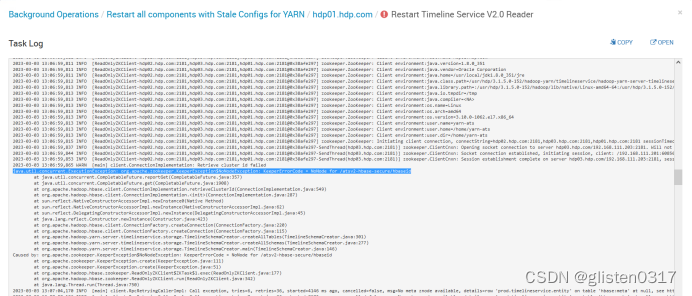
(1)Timeline Service启动报错
启动时报错:
java.util.concurrent.ExecutionException: org.apache.zookeeper.KeeperException$NoNodeException: KeeperErrorCode = NoNode for /atsv2-hbase-secure/hbaseid
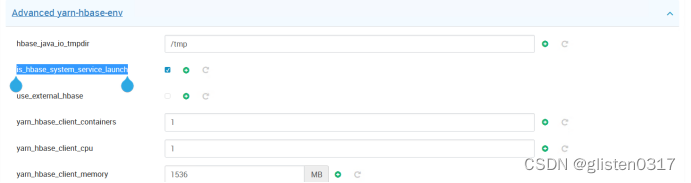
在Yarn中的CONFIGS->ADVANCED->Advanced yarn-hbase-env中,将is_hbase_system_service_launch启用
(2)History Server启动一会后报错
启动时无报错,等几分钟后报错并停止,在hdp02上查看日志,/var/log/hadoop-mapreduce/mapred/hadoop-mapred-historyserver-hdp02.log
报错信息为:
Error creating intermediate done directory: [hdfs://hdp315:8020/mr-history/tmp]
Permission denied: user=mapred, access=WRITE, inode="/mr-history"
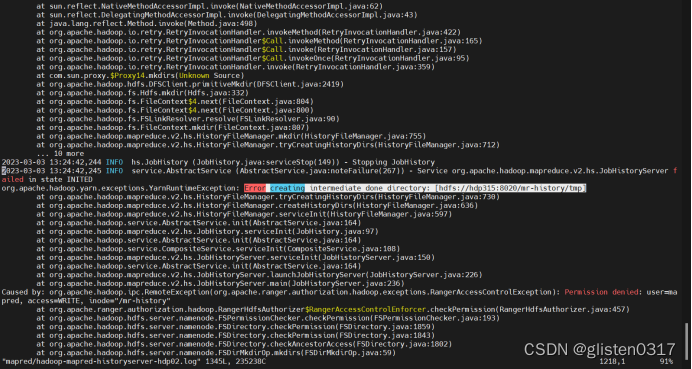
查看hdfs上的目录权限,确认权限归属无问题

原因是Ranger上取消了联合授权功能,在Ranger上没有对应的策略开放该目录,导致mapred用户无法访问对应的目录,开启联合授权功能后恢复。
(3)告警:ATS embedded HBase is NOT running on hdp01.hdp.com
告警信息:ATS embedded HBase is NOT running on hdp01.hdp.com
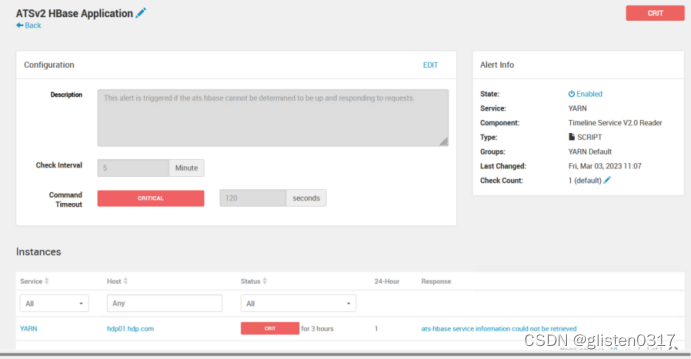
resourceMananger的JVM内存是1G,内存太小导致的,将ResourceManager中的Java heap size的JVM内存增加到了2048MB
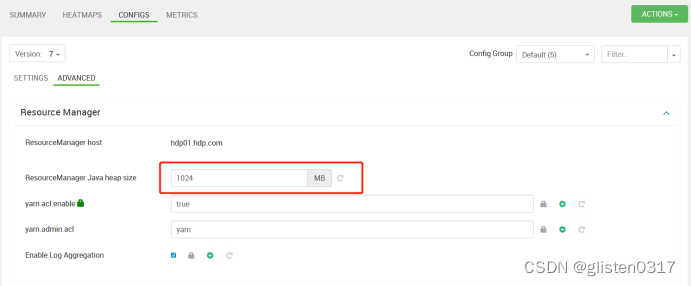
重启Yarn服务后告警消失
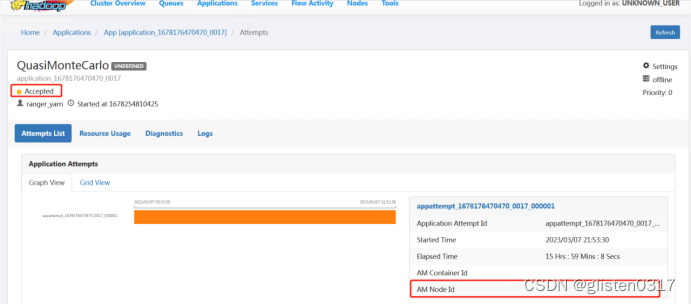
(4)提交任务后状态一直为ACCEPTED
主要可能的原因是分配给容器的内存过小导致,正常情况下需要适当调整分配内存,本次是因为总体内存量不大,而在分配queue:offline的时候,设置的资源大小为5%,导致无法正常运行,而是一直停留在分配资源阶段,重新分配队列资源大小后恢复。
这篇关于Hdoop学习笔记(HDP)-Part.14 安装YARN+MR的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







