本文主要是介绍【运维】hive 高可用详解: Hive MetaStore HA、hive server HA原理详解;hive高可用实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一. hive高可用原理说明
- 1. Hive MetaStore HA
- 2. hive server HA
- 二. hive高可用实现
- 1. 配置
- 2. beeline链接测试
- 3. zookeeper相关操作
一. hive高可用原理说明
1. Hive MetaStore HA
Hive元数据存储在MetaStore中,包括表的定义、分区、表的属性等信息。
hive metastore 配置多台,可以避免单节点故障导致整个集群的hive client不可用。
原理如下:
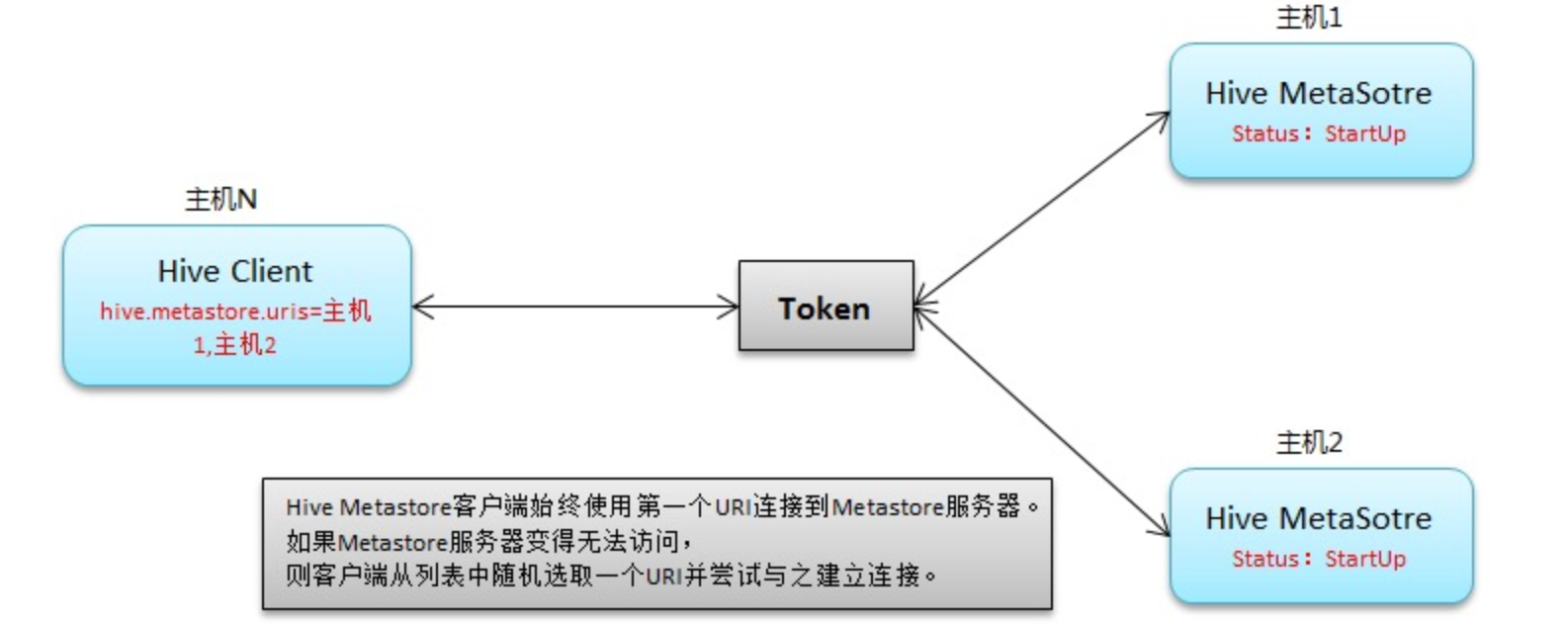
Active-active mode is not supported for Hive Metastore. Hence, there is one active instance of the Hive Metastore service at any given point in time. The other instances of the Hive Metastore service are in standby state.
hive metastore不支持双活的高可用,也就说hive metastore的高可用是主备架构,其中一个节点提供服务,另外一个节点处于就绪的状态。
相关配置项:在hive-site.xml中
<property>
<name>hive.metastore.uris</name>
<value>thrift://metastore_node1:9083,thrift://metastore_node2:9083</value>
</property>
2. hive server HA
HiveServer2是Hive的一个查询引擎,允许用户通过多种方式(如JDBC、ODBC等)提交和执行Hive查询。它负责解析客户端的请求,生成查询计划,并将这些任务提交给底层的执行引擎(如 MapReduce 或 Tez)。HiveServer2 本身并不直接处理 Thrift 协议,而是通过 Hive Thrift Server 来实现 Thrift 服务。
Hive从0.14开始,使用Zookeeper实现了HiveServer2的HA功能(ZooKeeper Service Discovery),Client端可以通过指定一个nameSpace来连接HiveServer2,而不是指定某一个host和port。
原理图如下:
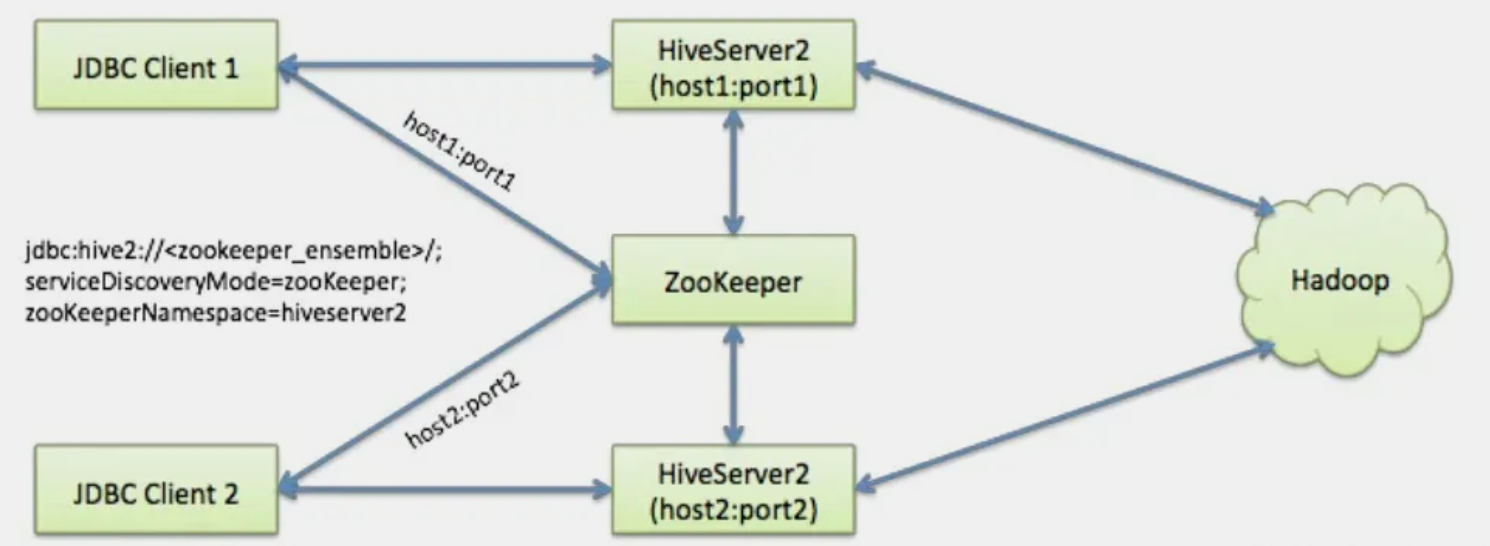
The JDBC/ODBC client connects to Zookeeper, which randomly returns a : for a registered HiveServer2 instance. The client uses the returned value to connect to a particular HiveServer2 instance directly to perform its work.
If the HiveServer2 instance fails while the client is connected, the client session is terminated and there is no automatic fail-over to a new HiveServer2 instance.
JDBC/ODBC client(比如中台的元数据发现服务通过JDBC访问)连接zookeeper,zookeeper随机返回一个server信息(<host>:<port>)用于注册hiveserver2实例。客户端使用返回的值连接指定的hiveserver实例,进行元数据查询等操作。当连接的hiveserver挂了或者无法通讯,创建的client会话将会关闭,且没有自动的故障转移操作转移到另外一个hiveserver实例。也就是说你需要重新请求HiveServer。
上面提到的随机返回一个hiveserver,说明hiveserver高可用具备一定的请求分流,减少hiveserver的请求压力。
参考:
IBM - availability-enabling-hiveserver2-high
相关配置:在hive-site.xml中添加
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property><property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2_zk</value>
</property><property>
<name>hive.zookeeper.quorum</name>
<value>zk_server1:2181,zk_server2:2181,zk_server3:2181</value>
</property><property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
二. hive高可用实现
1. 配置
每个hive所在节点修改配置:hive-site.xml
<property><name>hive.server2.support.dynamic.service.discovery</name><value>true</value>
</property><property><name>hive.server2.zookeeper.namespace</name><value>hiveserver2_zk</value>
</property><property><name>hive.zookeeper.quorum</name><value>zk_node1:2181,zk_node2:2181,zk_node3:2181</value>
</property><property><name>hive.zookeeper.client.port</name><value>2181</value>
</property><property><name>hive.metastore.uris</name><value>thrift://metastore_node1:9083,thrift://metastore_node2:9083</value>
</property>
所有节点执行,启动hive Metastore和hive server
因为hive server 依赖hive metastore,所以先启动metastore
nohup hive --service metastore >> /opt/module/apache-hive-2.1.1-bin/metastore.log 2>&1 &
nohup hive --service hiveserver2 >> /opt/module/apache-hive-2.1.1-bin/hiveserver.log 2>&1 &
2. beeline链接测试
语法说明:
jdbc:hive2://<zookeeper quorum>/<dbName>;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk
参数含义说明:
<zookeeper quorum>: 为Zookeeper的集群链接串,如node1:2181,node2:2181,node3:2181<dbName>: 为Hive数据库,不填默认为defaultserviceDiscoveryMode=zooKeeper: 指定模式为zooKeeperzooKeeperNamespace=hiveserver2_zk: 指定ZK中的nameSpace,即参数hive.server2.zookeeper.namespace所定义
连接测试:
beeline -u "jdbc:hive2://zk_node1:2181,zk_node2:2181,zk_node3:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk" -n user1 -p passwd1
这里因为配置了用户名和密码 ,所以使用了-n、-p 去链接,密码设置见我的相关文章:
hive CUSTOM authentication mode:通过用户名密码连接hiveserver
3. zookeeper相关操作
见:
availability-enabling-hiveserver2-high
这篇关于【运维】hive 高可用详解: Hive MetaStore HA、hive server HA原理详解;hive高可用实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






