本文主要是介绍scrapyd及gerapy的使用及docker-compse部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、scrapyd的介绍
scrapyd是一个用于部署和运行scrapy爬虫的程序,它允许你通过JSON API(也即是web api)来部署爬虫项目和控制爬虫运行,scrapyd是一个守护进程,监听爬虫的运行和请求,然后启动进程来执行它们
- scrapyd的安装
scrapyd服务端: pip install scrapyd
scrapyd客户端: pip install scrapyd-client
- 启动scrapyd服务
在scrapy项目路径下 启动scrapyd的命令:sudo scrapyd 或 scrapyd。启动之后就可以打开本地运行的scrapyd,浏览器中访问本地6800端口可以查看scrapyd的监控界面


- 点击Job可以查看任务监控

- 通过scrapyd部署scrapy项目
- 配置需要部署的项目:编辑需要部署的项目的scrapy.cfg文件(需要将哪一个爬虫部署到scrapyd中,就配置该项目的该文件)

- 部署项目到scrapyd
同样在scrapy项目路径下执行:
scrapyd-deploy 部署名(配置文件中设置的名称) -p 项目名称
以上面配置文件为例子:scrapyd-deploy Baidu -p my_spider
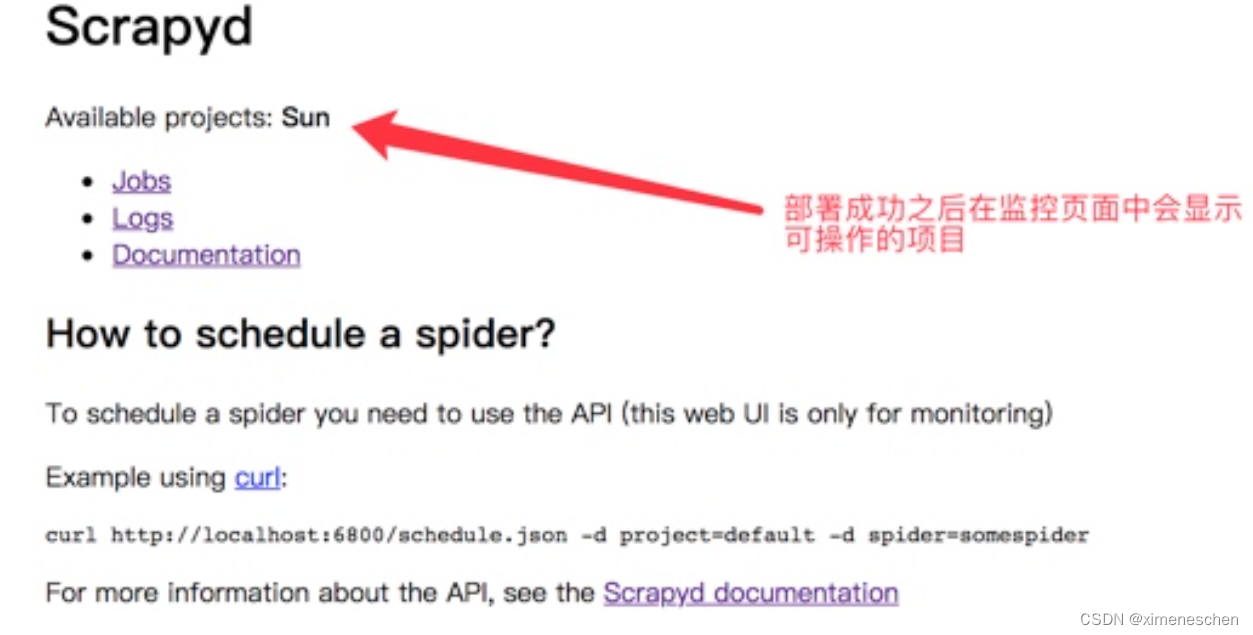
- 管理项目
启动项目:
curl http://localhost:6800/schedule.json -d project=project_name -d spider=spider_name
这里就可以看到使用web api调度有多么麻烦了,于是引入下面的gerapy
二、gerapy
- 什么是gerapy
Gerapy 是一款分布式爬虫管理框架,支持 Python 3,基于 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 开发,Gerapy 可以帮助我们:
- 更方便地控制爬虫运行
- 更直观地查看爬虫状态
- 更实时地查看爬取结果
- 更简单地实现项目部署
- 更统一地实现主机管理
通俗的解释:Gerapy 的最主要的目标是将 Scrapyd 的命令行操作转化为直观的 Web 点击操作。它提供了一个可视化的 Web 界面,让用户通过界面轻松地进行 Scrapy 项目的管理、监控和部署,而不必直接使用 Scrapyd 的命令行
- Gerapy的安装
- 执行如下命令,等待安装完毕
pip3 install gerapy
- 验证gerapy是否安装成功
在终端中执行 gerapy 会出现如下信息
Usage: gerapy init [--folder=] gerapy migrate gerapy createsuperuser gerapy runserver []`
- Gerapy配置启动
- 新建一个项目:
gerapy init
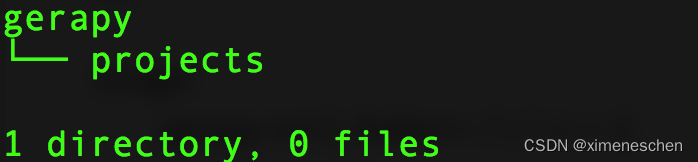
执行完该命令之后会在当前目录下生成一个gerapy文件夹,进入该文件夹,会找到一个名为projects的文件夹
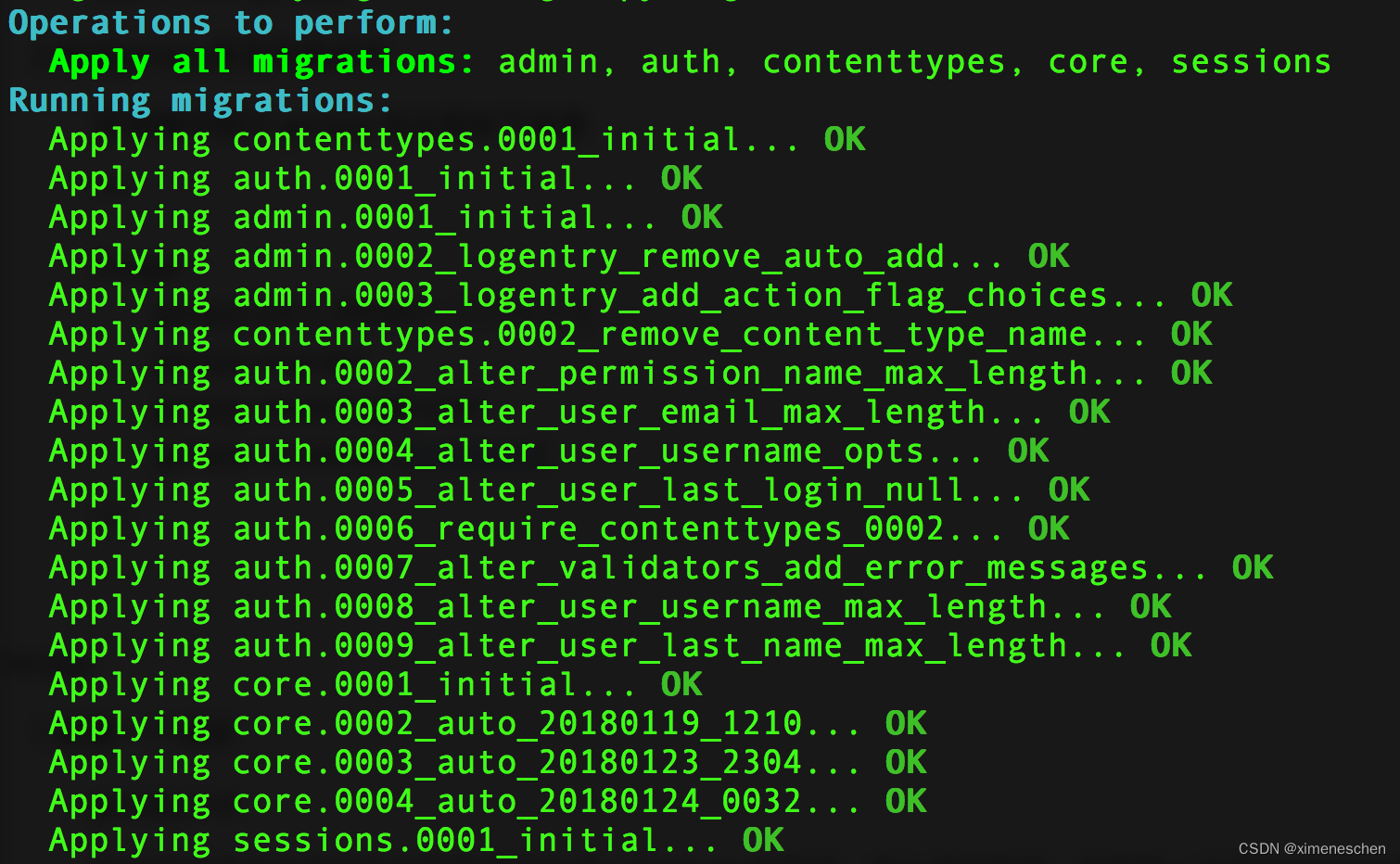
对数据库进行初始化(在gerapy目录中操作),执行如下命令
gerapy migrate
对数据库初始化之后会生成一个SQLite数据库,数据库保存主机配置信息和部署版本等
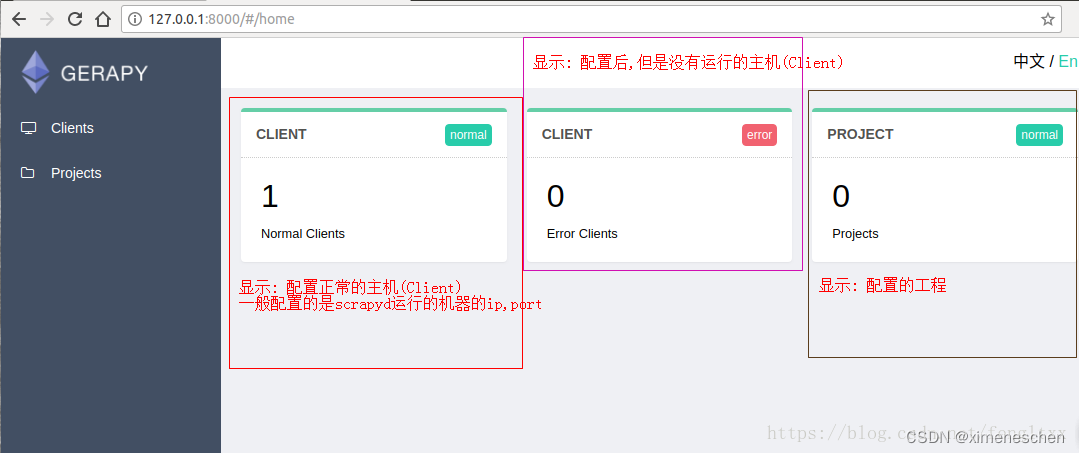
- 启动 gerapy服务: gerapy runserver
此时启动gerapy服务的这台机器的8000端口上开启了Gerapy服务,在浏览器中输入http://localhost:8000就能进入Gerapy管理界面,在管理界面就可以进行主机管理和界面管理
- 通过Gerapy配置管理scrapy项目
-
添加主机
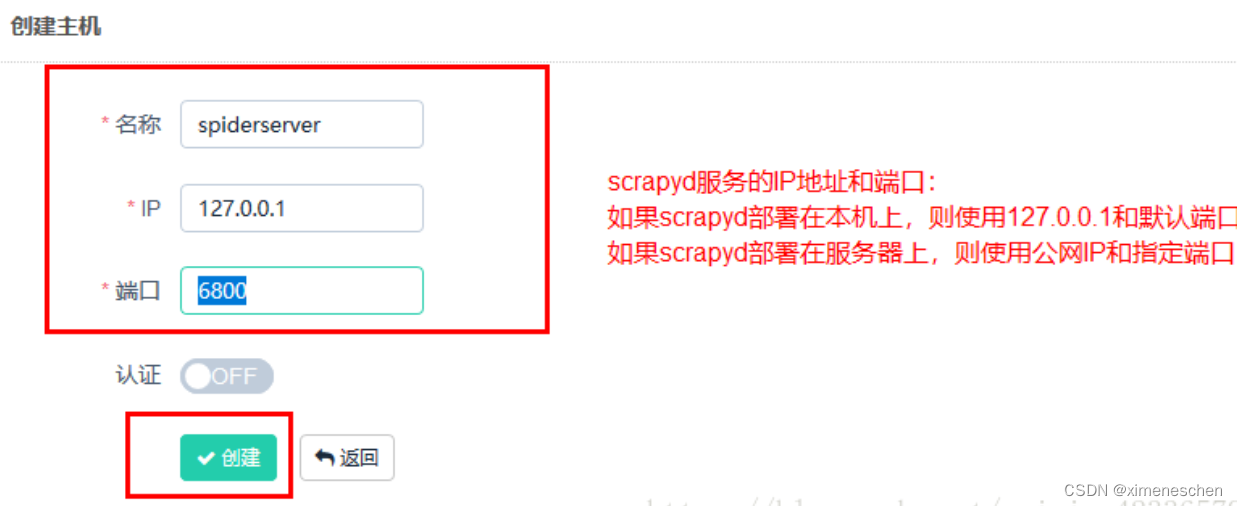
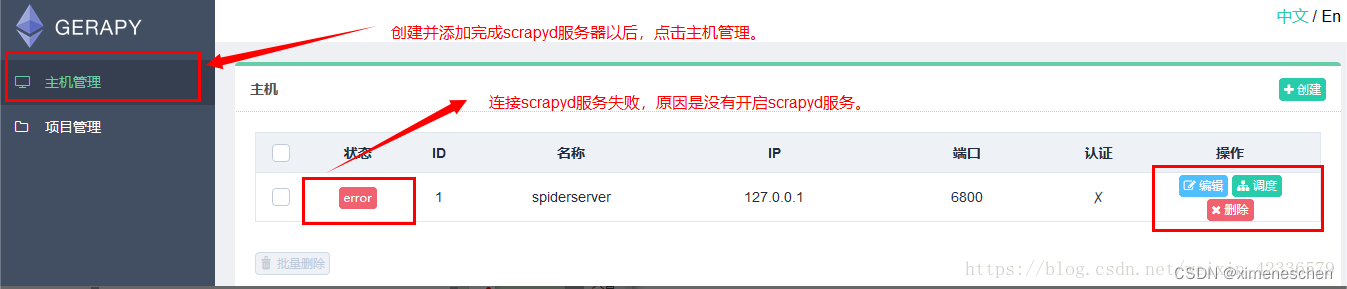
需要添加 IP、端口,以及名称,点击创建即可完成添加,点击返回即可看到当前添加的 Scrapyd 服务列表,创建成功后,我们可以在列表中查看已经添加的服务 -
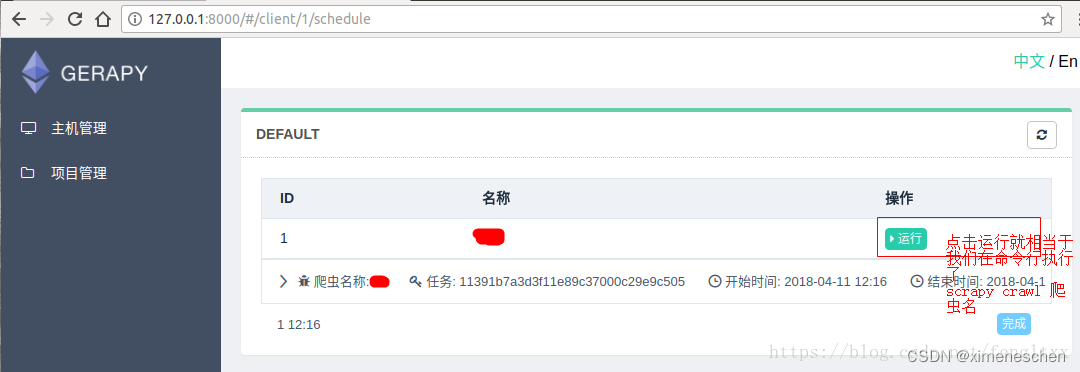
执行爬虫,就点击调度.然后运行.(前提是: 我们配置的scrapyd中,已经发布了爬虫.)
- 配置Projects.我们可以将scarpy项目直接放到 /gerapy/projects下

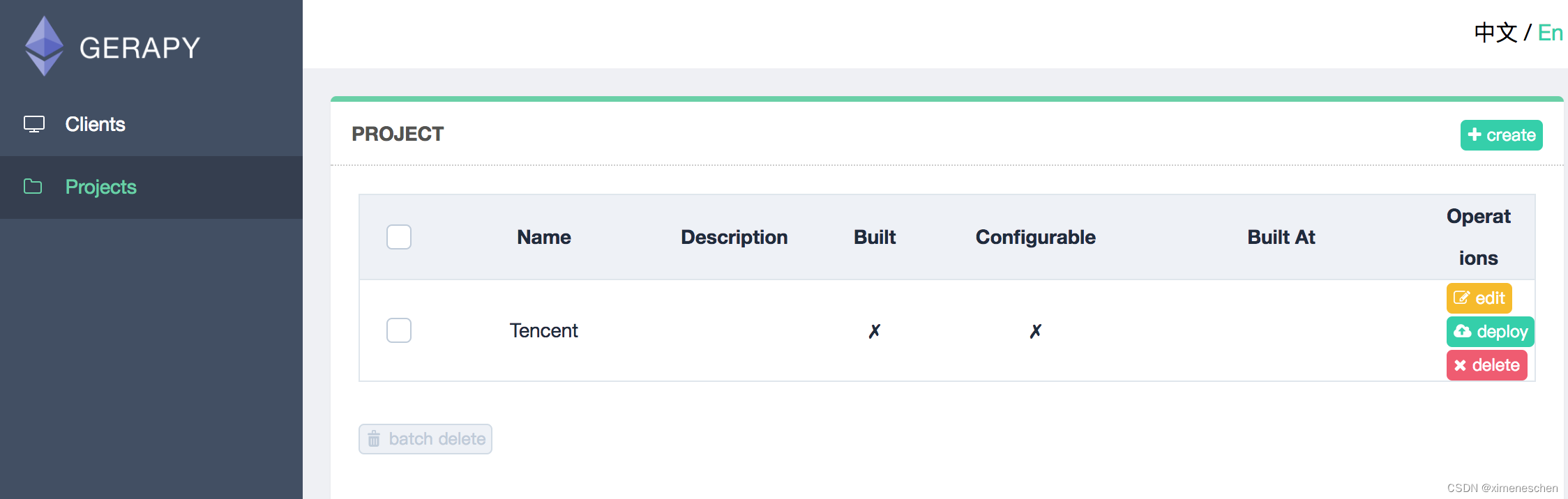
点击部署点击部署按钮进行打包和部署,在右下角我们可以输入打包时的描述信息,类似于 Git 的 commit 信息,然后点击打包按钮,即可发现 Gerapy 会提示打包成功,同时在左侧显示打包的结果和打包名称。
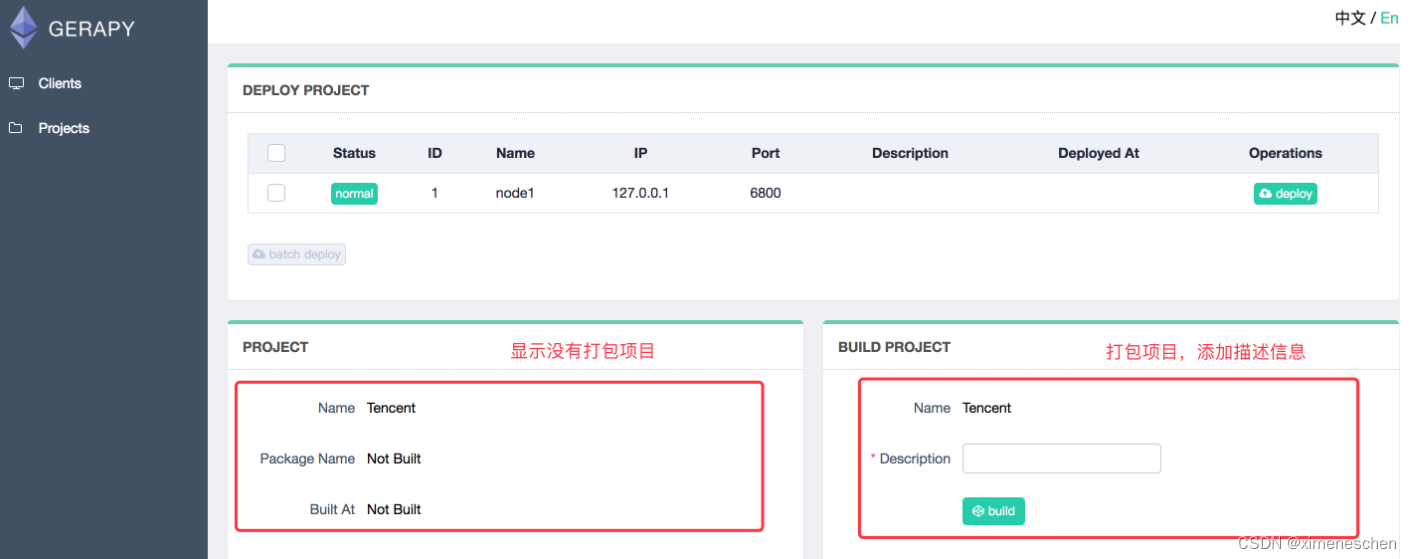
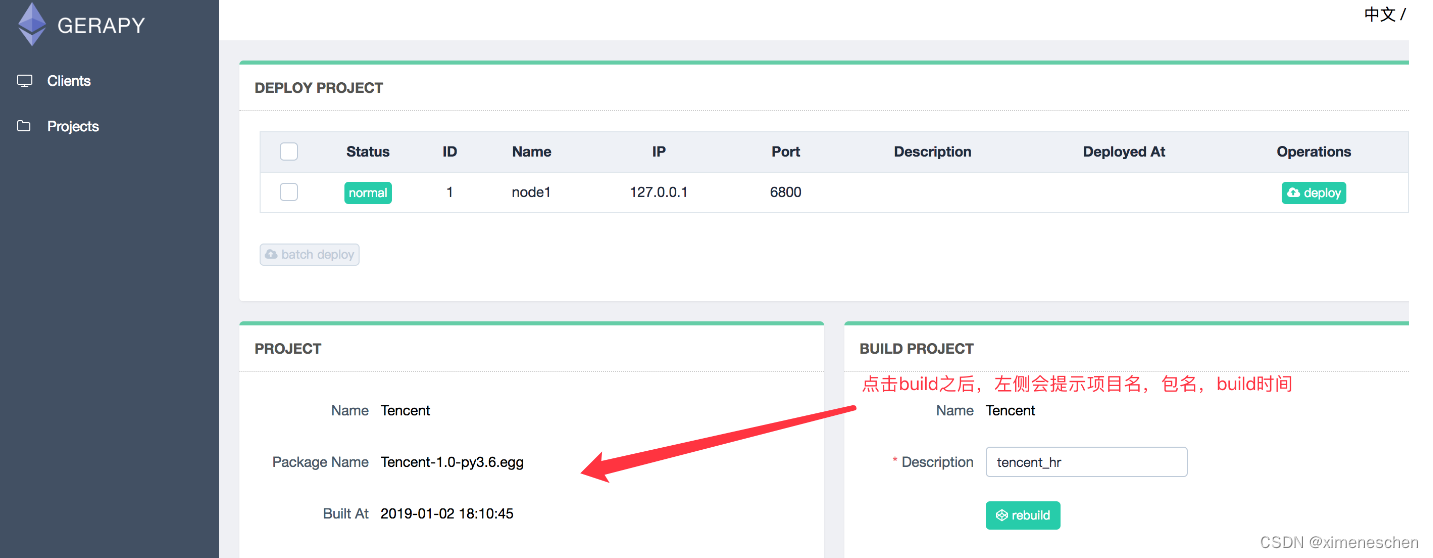
- 选择一个站点,点击右侧部署,将该项目部署到该站点上

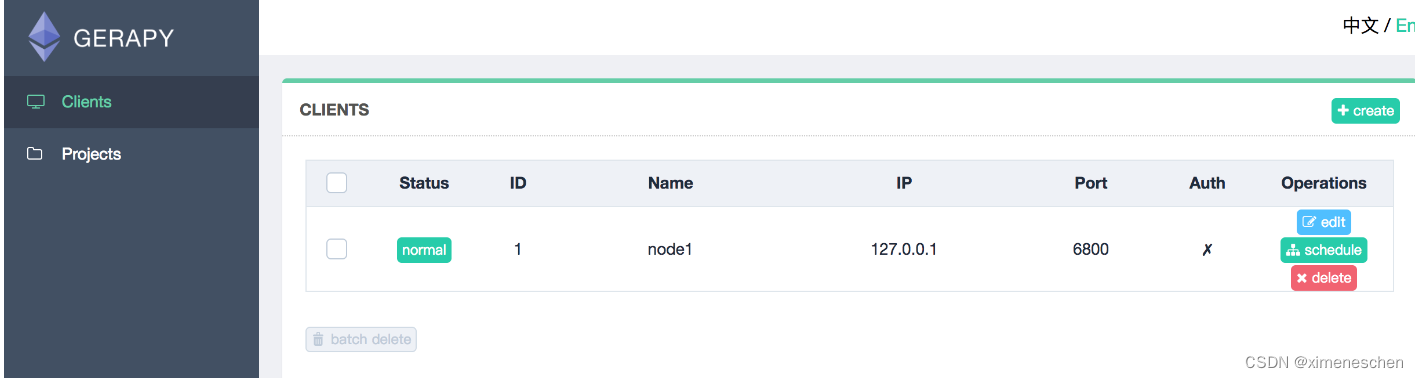
来到clients界面,找到部署该项目的节点,点击调度

三、基于docker-compose的方式
docker-compose的优势就不说了,直接贴文件,应该有人需要的:
version: '3'services:scrapyd:container_name: scrapydimage: germey/scrapyd:latest#network_mode: "host"ports:- "6800:6800"volumes:- /opt/docker/scrapyd_gerapy/scrapyd/app:/apprestart: alwaysgerapy:container_name: gerapyimage: germey/gerapy:latest#environment:# - GERAPY_PORT=8001(有大佬知道如何覆盖镜像里的默认端口麻烦告知一下)#network_mode: "host"ports:- "8001:8000"volumes:- /opt/docker/scrapyd_gerapy/gerapy:/app/gerapydepends_on:- scrapydrestart: always
这篇关于scrapyd及gerapy的使用及docker-compse部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







