本文主要是介绍2023.11.28 使用tensorflow进行“三好“权重分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2023.11.28 使用tensorflow进行"三好"权重分析
这是最基础的一个神经网络问题。许久没有再使用,用来做恢复训练比较好。
x1w1 + x2w2 +x3*w3 = y,已知x1,x2,x3和y,求w1,w2,w3
这是一个三元一次方程,正常需要三组数据就能准确求出解,但是如果要在仅有两组数据的情况下进行求解,除使用暴力法外,采用神经网络是一个不错的选择,网络模型图如下
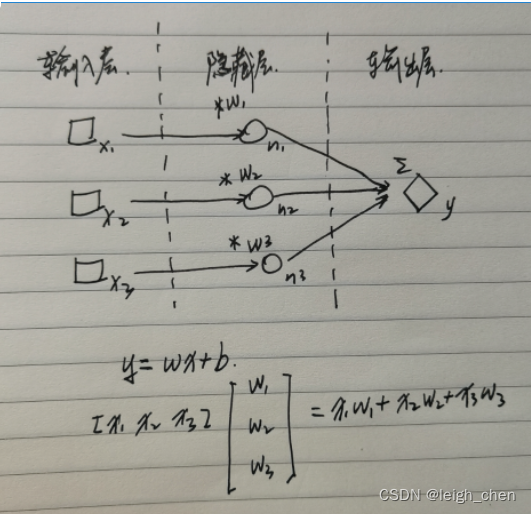
'''尝试最基础的tensorflow应用:三好学生的"三好"权重分析问题:"三好"指的是品德好,学习好,体育好,有两组分数和各组分数综合值,求每个分数的权重
'''import tensorflow.compat.v1 as tf # tf2.0版本改动太大,如果要按1.X版本的格式写需要调用这个库
tf.disable_v2_behavior() # tf2.0版本改动太大,如果要按1.X版本的格式写需要调用这个库x1 = tf.placeholder(dtype=tf.float32)
x2 = tf.placeholder(dtype=tf.float32)
x3 = tf.placeholder(dtype=tf.float32)
yTrain = tf.placeholder(dtype=tf.float32)
'''在TensorFlow 1.X中,创建占位符并在tf.Session实例化时为其提供实际值。但是,从TensorFlow2.0开始,默认情况下启用了Eager Execution,因此“占位符”的概念没有意义,因为操作是立即计算的(而不是与旧范例不同)
'''w1 = tf.Variable(0.1,dtype=tf.float32) # 0.1是w1的初始化参数
w2 = tf.Variable(0.1,dtype=tf.float32)
w3 = tf.Variable(0.1,dtype=tf.float32)n1 = x1 * w1
n2 = x2 * w2
n3 = x3 * w3y = n1 + n2 + n3loss = tf.abs(y - yTrain) # 使用.abs(绝对值),是使实际值和目标值差距最小,而不是损失函数数字最小
learning_rate = 0.001optimizer = tf.train.RMSPropOptimizer(learning_rate) # 选择优化器/分类器train = optimizer.minimize(loss) # 训练模型,目标是loss最小sess = tf.Session()
init = tf.global_variables_initializer() # 初始化前述张量(tf.)
sess.run(init)for i in range(5000):result = sess.run([train,x1,x2,x3,w1,w2,w3,y,yTrain,loss],feed_dict={x1:90,x2:80,x3:70,yTrain:85})print(result)result = sess.run([train, x1, x2, x3, w1, w2, w3, y, yTrain, loss], feed_dict={x1: 98, x2: 95, x3: 87, yTrain: 96})print(result)
循环5000次,输出结果

# 输出结果解释
第一个元素 None 表示训练操作 train 的执行结果为空。
第二个元素 array(98., dtype=float32) 表示输入占位符 x1 的值为 98。
第三个元素 array(95., dtype=float32) 表示输入占位符 x2 的值为 95。
第四个元素 array(87., dtype=float32) 表示输入占位符 x3 的值为 87。
第五个元素 0.5828438 表示权重变量 w1 的值为 0.5828438。
第六个元素 0.2860972 表示权重变量 w2 的值为 0.2860972。
第七个元素 0.13144642 表示权重变量 w3 的值为 0.13144642。
第八个元素 96.03325 表示模型输出 y 的值为 96.03325。
第九个元素 array(96., dtype=float32) 表示目标输出占位符 yTrain 的值为 96。
最后一个元素 0.0332489 表示损失函数 loss 的值为 0.0332489。
对比循环500次,输出结果,循环500次loss尚未稳定,和最终结果存在较大偏差

这篇关于2023.11.28 使用tensorflow进行“三好“权重分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




