本文主要是介绍3种在ArcGIS Pro中制作山体阴影的方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
山体阴影可以更直观的展现地貌特点,表达真实的地形,这里为大家介绍一下在ArcGIS Pro中制作山体阴影的方法,希望能对你有所帮助。
数据来源
本教程所使用的数据是从水经微图中下载的DEM数据,除了DEM数据,常见的GIS数据都可以从水经微图中下载。
水经微图
符号系统渲染
在符号系统内,选择主符号系统为晕渲地貌即可看到山体阴影效果,如下图所示。
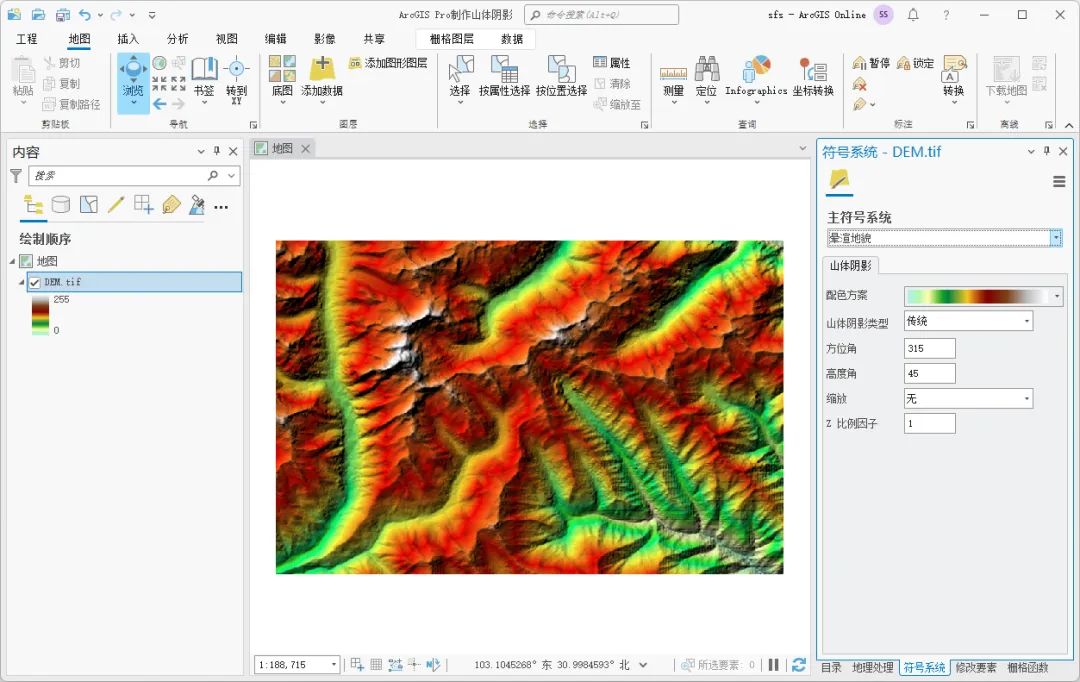
符号系统内山体阴影
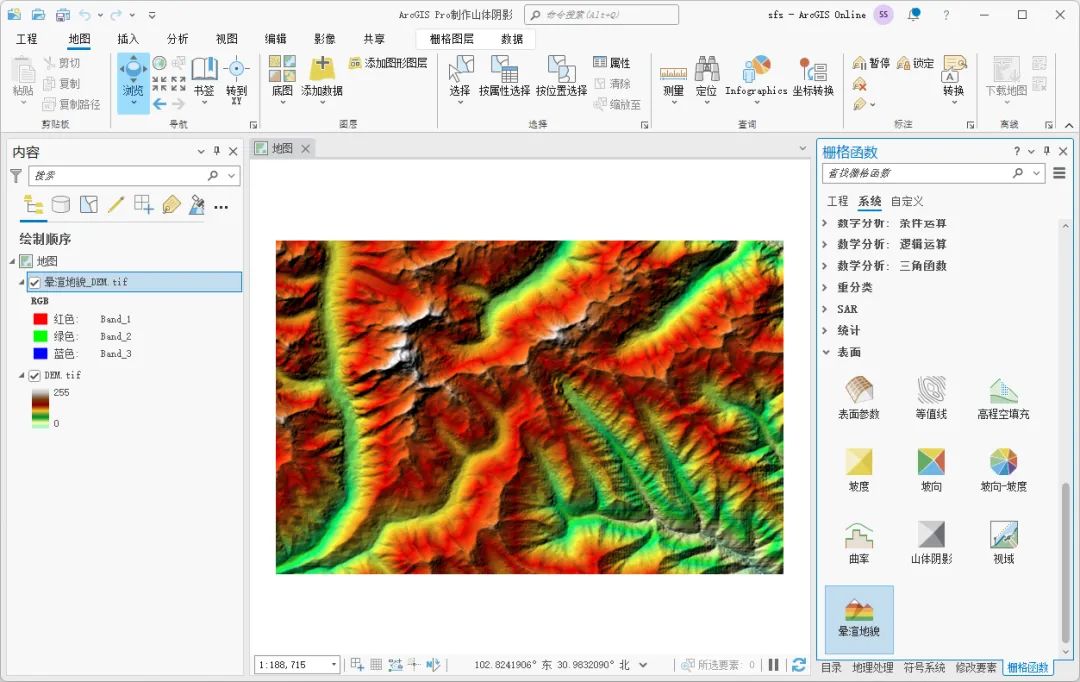
晕渲地貌函数
打开栅格函数,在表面内选择晕渲地貌函数,如下图所示。
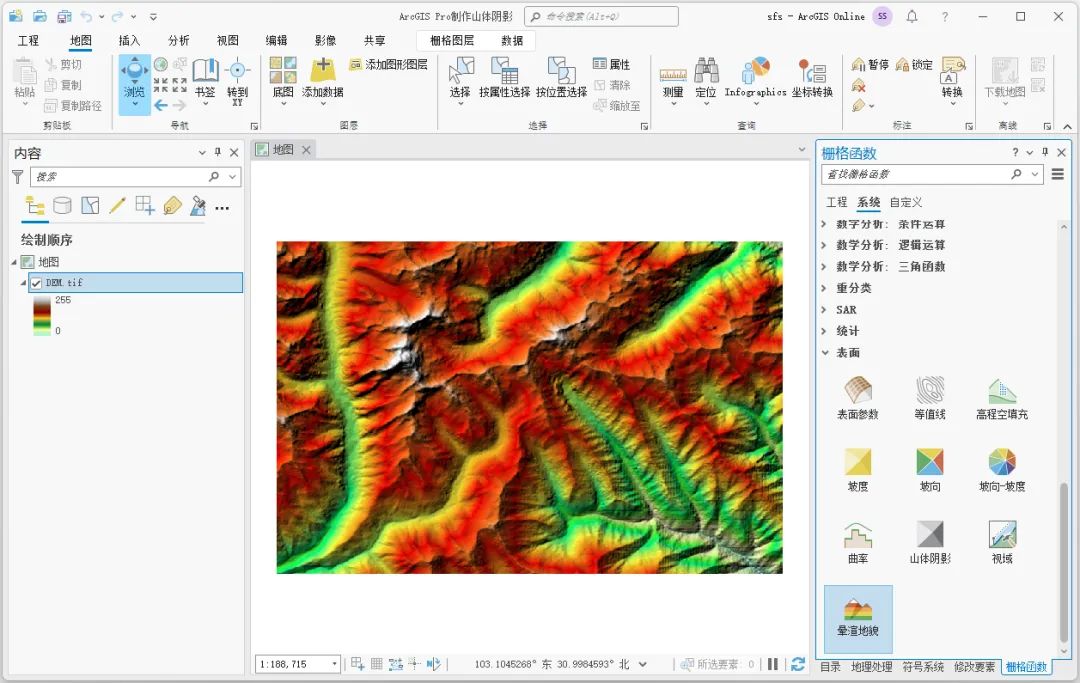
选择晕渲地貌函数
在晕渲地貌属性对话框内,栅格为DEM数据,配色方案类型选择色带,选择合适的色带并设置山体阴影类型等参数,如下图所示。
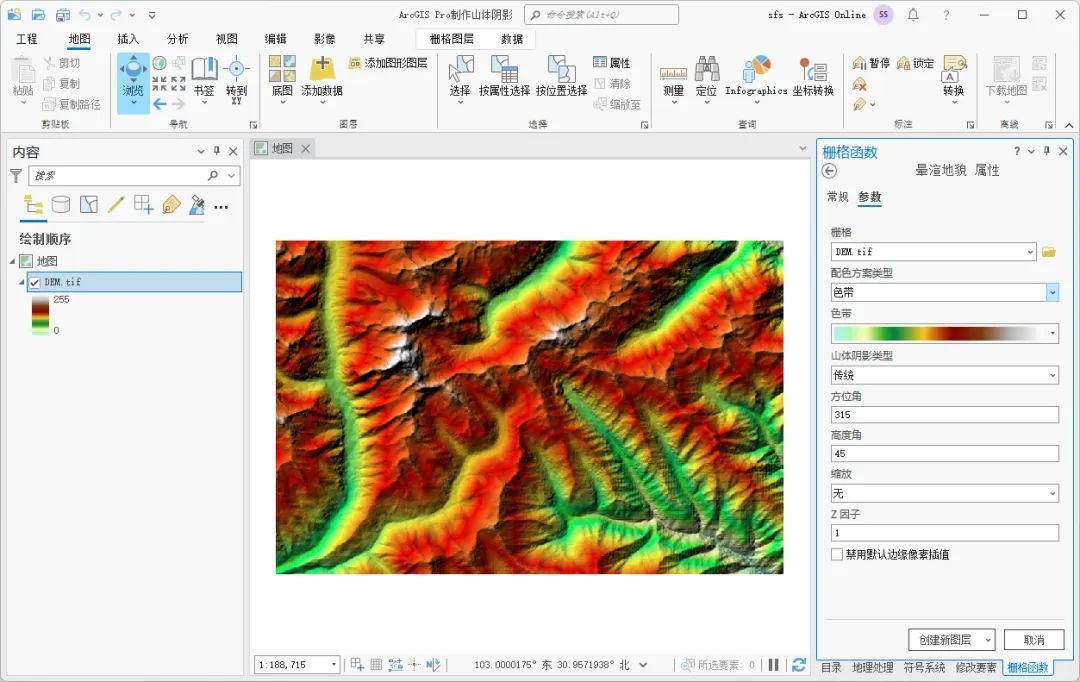
晕渲地貌属性设置
点击创建新图层后可以看到生成的山体阴影,如下图所示。
生成的山体阴影
山体阴影工具
在工具箱内点击“Spatial Analyst工具\表面分析\山体阴影”,调用山体阴影工具,如下图所示。
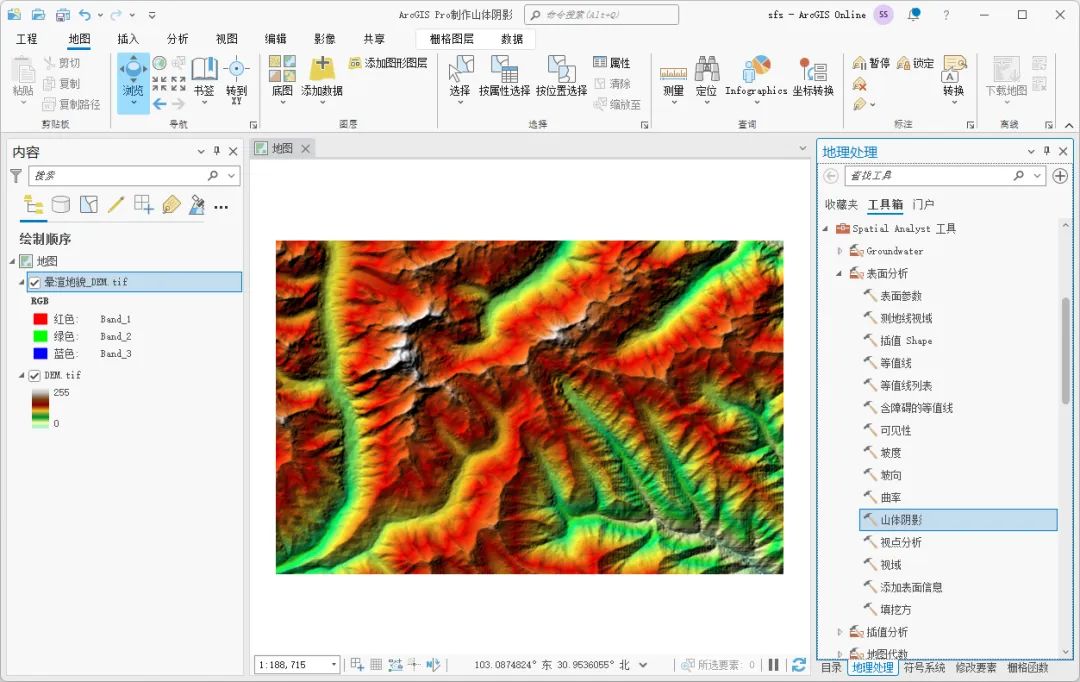
调用山体阴影工具
在显示的山体阴影对话框内,输入栅格为DEM数据,设置输出栅格和方位角等参数,如下图所示。
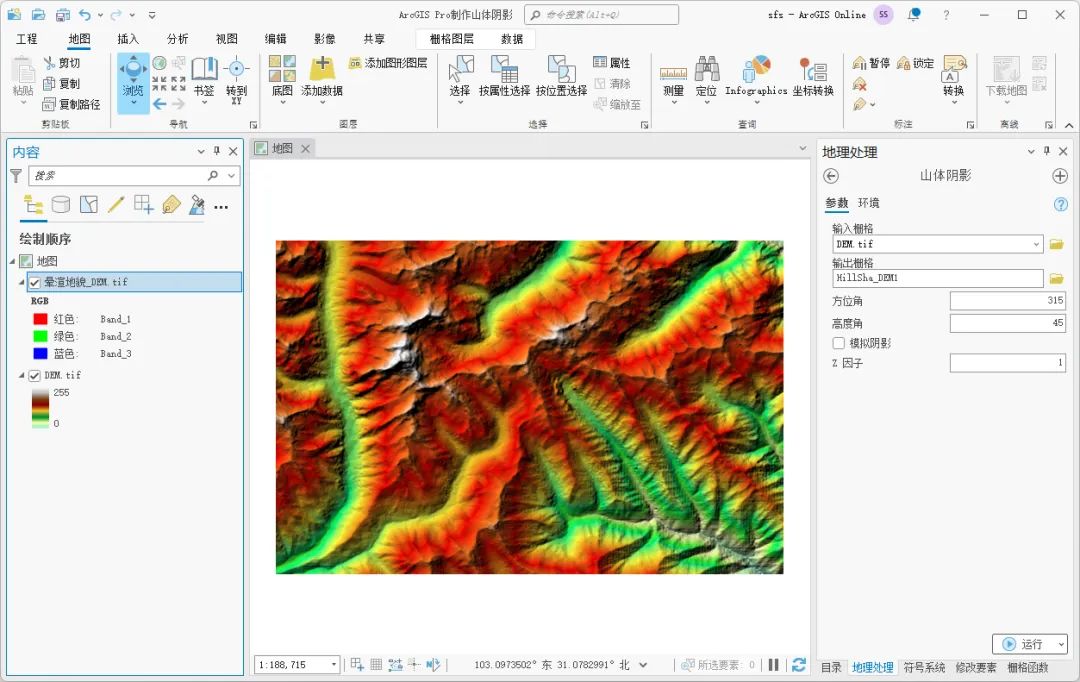
山体阴影设置
调整DEM的色带,并将生成的山体阴影图层适当透明即可看到最终的效果,如下图所示。
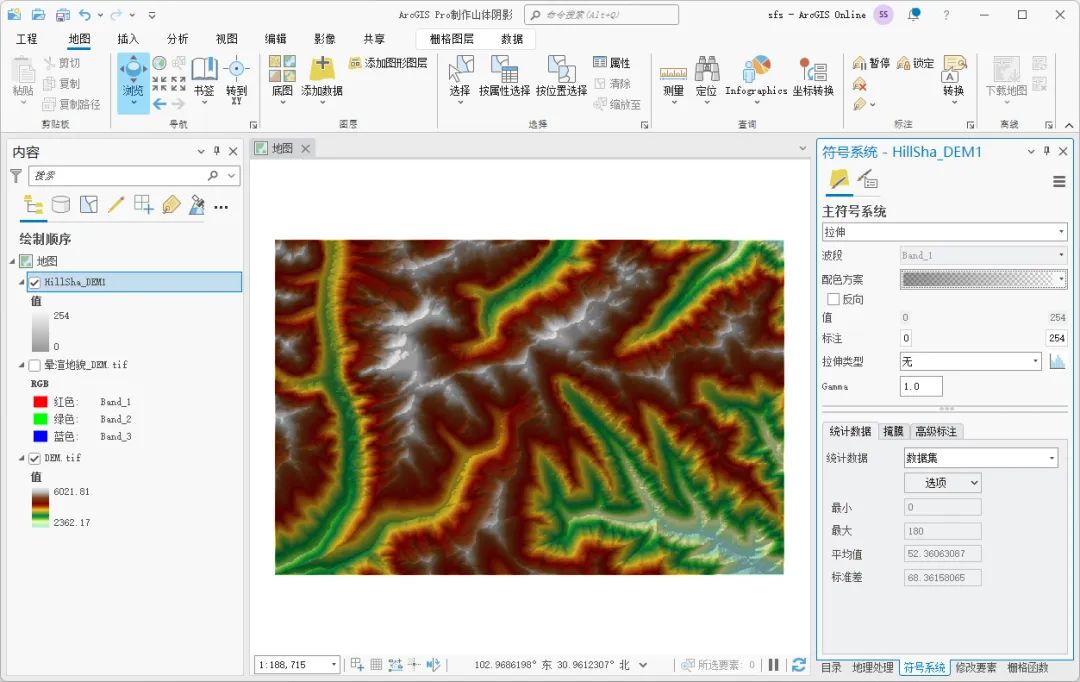
最终效果
结语
以上就是3种在ArcGIS Pro中制作山体阴影的方法的详细说明,主要包括了数据来源、符号系统渲染、晕渲地貌函数和山体阴影工具等功能。
这篇关于3种在ArcGIS Pro中制作山体阴影的方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







