本文主要是介绍Python提取PDF表格(基于AUTOSAR_SWS_CANDriver.pdf),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
个人学习笔记,仅供参考。
需求:提取AUTOSAR SWS中所有的API接口信息,用于生成C代码。
此处以AUTOSAR_SWS_CANDriver.pdf为例,若需要提取多个SWS文件,遍历各个文件即可。
1.Python包
pdfplumber是一款完全用python开发的pdf解析库,对于线框完全的表格,pdfminer能给出比较好的抽取效果,但是对于线框不完全(包含无线框)的表格,其效果就差了不少。因为在实际项目所需处理的pdf文档中,线框完全及不完全的表格都比较多。

备注:安装时,可能会因为网络问题,导致pdfplumber安装失败,可以切换国内镜像进行安装,具体命令如下:
pip install pdfplumber -i http://pypi.douban.com/simple
其他国内源如下:
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
2.实现思路
目标表格
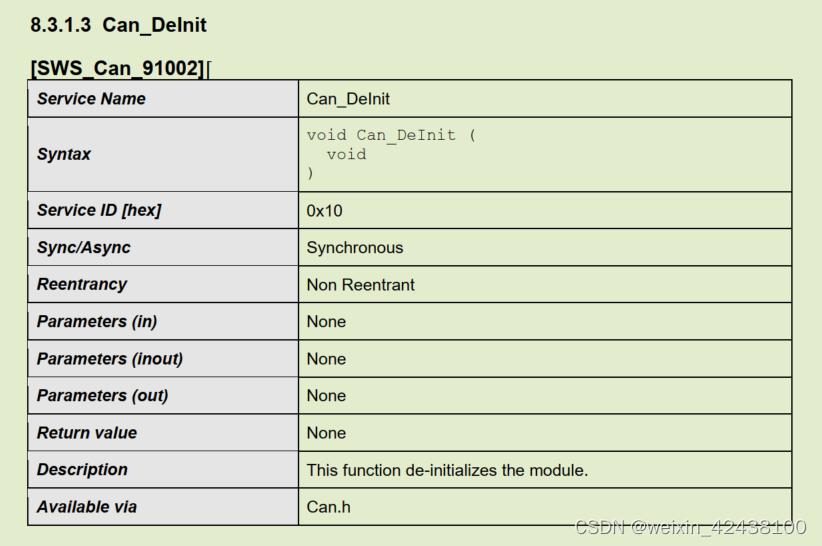
具体步骤
1、使用extract_tables解析当前page所有表格,判断一个单元格为“Service Name”(关键字)
2、若存在Service Name,将此表格的内容追加到总表
3、读取当前表的同时判断是否是完整的表格,如果不是,则继续读取下一页,在一起追加到总表
备注:第一个单元格不是“Service Name”,存在两种情况,一是非我们想要的表格,另一个是部分我们需要的,后者在步骤3中处理掉,所以无影响
参考代码
import pdfplumberinputFile = "AUTOSAR_SWS_CANDriver.pdf"
functionList = []
# 前15页无有效信息,为提高效率,减少扫描页数
startPage = 15def readPdfFile():global functionListtable_settings = {"vertical_strategy": "lines", # 对于完整的表格,vertical_strategy与horizontal_strategy都配置为lines"horizontal_strategy": "lines","snap_y_tolerance": 10, # y方向上较短的线条extract_tables也会识别为表格的边界,最后导致识别出错# 这里将最小像素点设置为10(小于10丢弃线条丢弃)}with pdfplumber.open(inputFile) as pdf:######################################### 仅前期调试使用,具体使用时,可以屏蔽first_page = pdf.pages[63] # 指定(63+1)页PDF内容im = first_page.to_image() # 转换为image个数im.reset().debug_tablefinder(table_settings) # 将table_settings配置效果输出到图片方便观看im.save('xx.PNG', format="PNG", quantize=True, colors=256, bits=8)########################################for j in range(len(pdf.pages) - startPage):page = pdf.pages[j + startPage]table = page.extract_tables(table_settings)for i in range(len(table)): # 遍历所有表格row = table[i]if row[0][0] == 'Service Name': # 找表头tempList = row # 先复制已有的信息if (i == (len(table)-1)) and (row[-1][0] != 'Available via'): # 最后一个表,且缺少最后一行,继续读取下一页的第一个表page1 = pdf.pages[j + startPage + 1] # 继续读取下一页table1 = page1.extract_tables(table_settings)for table1_1 in table1[0]: # 只需要读取第一个表格(其他的会在在下次循环中写入)if table1_1[0] == '': # 如果第一个表格的第一个参数为空,代表第一行的参数的补充,并不是新的参数,所以此处拼接上去tempList[-1][1] += '\n' + table1_1[1]else: # 如果不为空,代表是新参数,直接追加即可tempList.append(table1_1)functionList.append(tempList) # 最后汇总到总表格内if __name__ == '__main__':readPdfFile()for i in functionList:print(i)print('共%d个函数' % len(functionList))
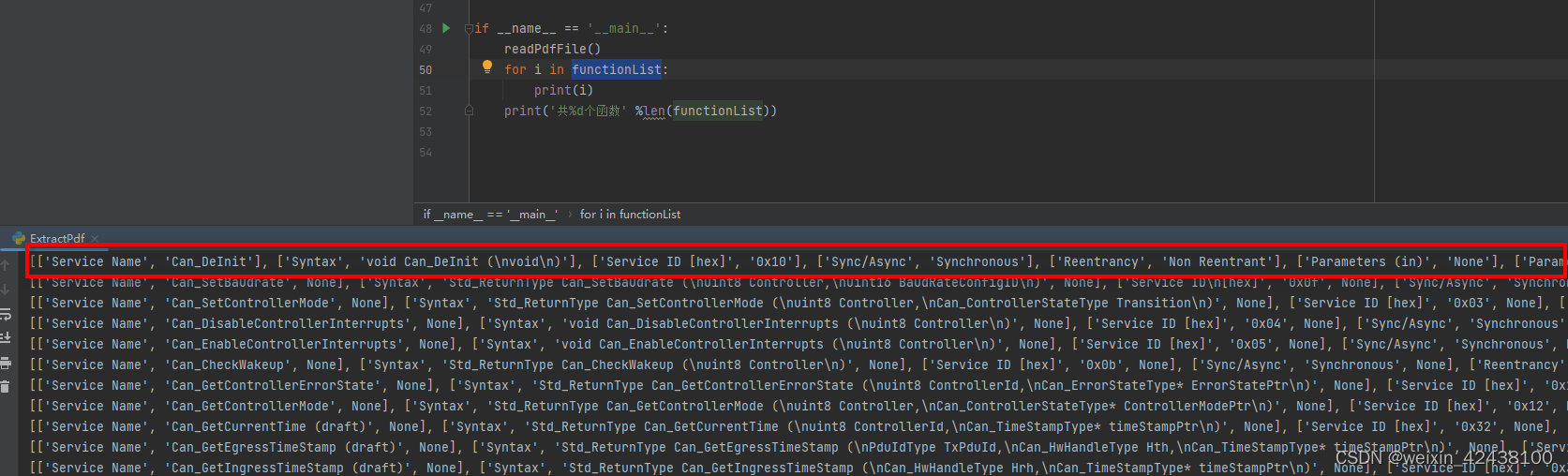
3.输出结果
最终保存到全局列表functionList中,后续可根据各自的开发规范/要求输出相应的代码。
4. 配置说明
table_settings = {"vertical_strategy": "lines", # 对于完整的表格,vertical_strategy与horizontal_strategy都配置为lines"horizontal_strategy": "lines","snap_y_tolerance": 10, # y方向上较短的线条extract_tables也会识别为表格的边界,最后导致识别出错# 这里将最小像素点设置为10(小于10丢弃线条丢弃)}
4.1 snap_y_tolerance默认值效果
这里可以发现识别了很多无效的边界进入,导致组成了很多多余的单元格,最终识别出错,或者无法识别

备注:四个正交连接的小圆圈框起来的区域认为是一个单元格,此处不是很明显,具体可以看下图
4.2 snap_y_tolerance配置为10效果
可以很明显看见,上面很多短的边界被忽略掉了。

备注:“Syntax”出个人了解不应该识别出来,但是此处任然识别出来了,可能因为左侧的两点未连接,所以不影响最终结果,此处未进行深入研究,知道的小伙伴,欢迎讨论
5. 参考资料
1、https://zhuanlan.zhihu.com/p/352722932
2、https://github.com/jsvine/pdfplumber#visual-debugging
3、https://github.com/jsvine/pdfplumber/blob/stable/examples/notebooks/extract-table-nics.ipynb
4、https://zhuanlan.zhihu.com/p/100460222
5、https://zhuanlan.zhihu.com/p/100462752
6、https://zhuanlan.zhihu.com/p/100464246
这篇关于Python提取PDF表格(基于AUTOSAR_SWS_CANDriver.pdf)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




