本文主要是介绍【网站可用性自动化监测】python+seleium,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【网站可用性自动化监测】python+seleium
- 前倾提要:做了网络安全后重保期间需要对用户系统每日进行监测,相关监测脚本网上其实也有很多,但能自己个性化做一下也挺好,太久没做小程序需要写下代码巩固。
- 本次程序开发目的是重保期间每天分三个时间点对多个网站进行访问监测可用性,并截图,如发现异常把异常站点推送至微信助手并记录
- 分三大功能函数:网站访问、网站列表读取、定时执行函数
前倾提要:做了网络安全后重保期间需要对用户系统每日进行监测,相关监测脚本网上其实也有很多,但能自己个性化做一下也挺好,太久没做小程序需要写下代码巩固。
本次程序开发目的是重保期间每天分三个时间点对多个网站进行访问监测可用性,并截图,如发现异常把异常站点推送至微信助手并记录
分三大功能函数:网站访问、网站列表读取、定时执行函数
第一部分网站列表读取 代码片.
def get_page_png(urls, browser,now_folder):die_domain = []'''从一个地址列表里,逐个访问,可以访问的地址就截图'''for url in urls:png_namea = url.replace('//', '_').replace('.', '_').replace('/', '_').replace(':',"_")png_name = png_namea + '.png'try:# 屏蔽requests的ssl warning警告信息urllib3.disable_warnings()response = requests.get(url=url, headers=headers, timeout=10, verify=False)if response.status_code == 200:# 访问url# print('url:',url)browser.get(url)# 保存截图browser.save_screenshot(f"./{now_folder}/{png_name}")print(f"{png_name} 保存成功")except:now_404 = f"{url} 无法访问!"print(now_404)mychat(now_404)die_domain.append(url)passnow_die_domain(die_domain)
第二部分网站访问 代码片.
def main():'''主函数'''# 构造urlprint(time.strftime("%Y-%m-%d %H:%M"))urls = []with open("domain_list.txt", "r") as f:for domain in f.readlines():urls.append(domain.strip())# 选项设置options = webdriver.ChromeOptions()# 指定chrome浏览器路径# options.binary_location = r"C:\\Program Files\\Google\\Chrome\\Application"# 终端不显示日志options.add_experimental_option('excludeSwitches', ['enable-logging'])# # 设置无头模式# chrome_options = Options()# chrome_options.add_argument('--headless')# chrome_options.add_argument('--disable_gpu')# 设置无头模式options.add_argument('--headless')options.add_argument('--disable_gpu')# 实例化一个浏览器对象# browser = webdriver.Chrome(executable_path='./chromedriver.exe', options=options)# s = Service("chromedriver.exe")browser = webdriver.Chrome(options=options)# 设置屏幕最大化browser.maximize_window()# 执行浏览器访问now_folder = new_folder()get_page_png(urls, browser,now_folder)# 访问结束后退出browser.quit()
第三部分定时执行 代码片.
def mytime():schedule.every().day.at("10:00").do(main)#里面时间进行修改schedule.every().day.at("13:00").do(main)schedule.every().day.at("16:00").do(main)while True:try:schedule.run_pending()time.sleep(1)except Exception as e:print('报错:',e)
完整代码 代码片.
#!/usr/bin/env python
# -*- coding:utf-8 -*-import requests
import os
import time
import urllib3
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import schedule
#import itchat#此库是调用网页版微信,可自动化使用微信,但测试中发现大部分用户在扫描二维码阶段出现异常,排查结果说是微信安全屏蔽了此接口调用,运气好的可以试试(我可以使用)#根据时间创建保存网站截图的文件夹
def new_folder():s = time.strftime("%Y%m%d%H%M")os.mkdir("http_pic" + s)f = "http_pic" + sreturn fdef get_page_png(urls, browser,now_folder):die_domain = []'''从一个地址列表里,逐个访问,可以访问的地址就截图'''for url in urls:png_namea = url.replace('//', '_').replace('.', '_').replace('/', '_').replace(':',"_")png_name = png_namea + '.png'try:# 屏蔽requests的ssl warning警告信息urllib3.disable_warnings()response = requests.get(url=url, headers=headers, timeout=10, verify=False)if response.status_code == 200:# 访问url# print('url:',url)browser.get(url)# 保存截图browser.save_screenshot(f"./{now_folder}/{png_name}")print(f"{png_name} 保存成功")except:now_404 = f"{url} 无法访问!"print(now_404)#mychat(now_404)#发送无法网站站点给微信助手die_domain.append(url)passnow_die_domain(die_domain)#导出无法访问站点.txt文件
def now_die_domain(die_domain):if die_domain:f = open("无法访问的站点.txt", "a")f.write(time.strftime(f"%Y-%m-%d %H:%M") + "\n")for domain in die_domain:f.write(domain + "\n")f.close()def main():'''主函数'''# 构造urlprint(time.strftime("%Y-%m-%d %H:%M"))urls = []with open("domain_list.txt", "r") as f:for domain in f.readlines():urls.append(domain.strip())# 选项设置options = webdriver.ChromeOptions()# 指定chrome浏览器路径# options.binary_location = r"C:\\Program Files\\Google\\Chrome\\Application"# 终端不显示日志options.add_experimental_option('excludeSwitches', ['enable-logging'])# # 设置无头模式# chrome_options = Options()# chrome_options.add_argument('--headless')# chrome_options.add_argument('--disable_gpu')# 设置无头模式options.add_argument('--headless')options.add_argument('--disable_gpu')# 实例化一个浏览器对象# browser = webdriver.Chrome(executable_path='./chromedriver.exe', options=options)# s = Service("chromedriver.exe")browser = webdriver.Chrome(options=options)# 设置屏幕最大化browser.maximize_window()# 执行浏览器访问now_folder = new_folder()get_page_png(urls, browser,now_folder)# 访问结束后退出browser.quit()#把无法访问站点发送给微信助手,可以用腾讯短信功能代替,但需要开发对应小程序并申请(https://cloud.tencent.com/search/%E7%9F%AD%E4%BF%A1/1_1)
def mychat(now_404):a = now_404itchat.send(a, toUserName='filehelper')# print('已发送',a)def mytime():schedule.every().day.at("10:00").do(main)schedule.every().day.at("13:00").do(main)schedule.every().day.at("16:00").do(main)while True:try:schedule.run_pending()time.sleep(1)except Exception as e:print('报错:',e)if __name__ == '__main__':#itchat.auto_login(hotReload=True)#微信二维码headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36",}mytime()程序运行效果 代码片
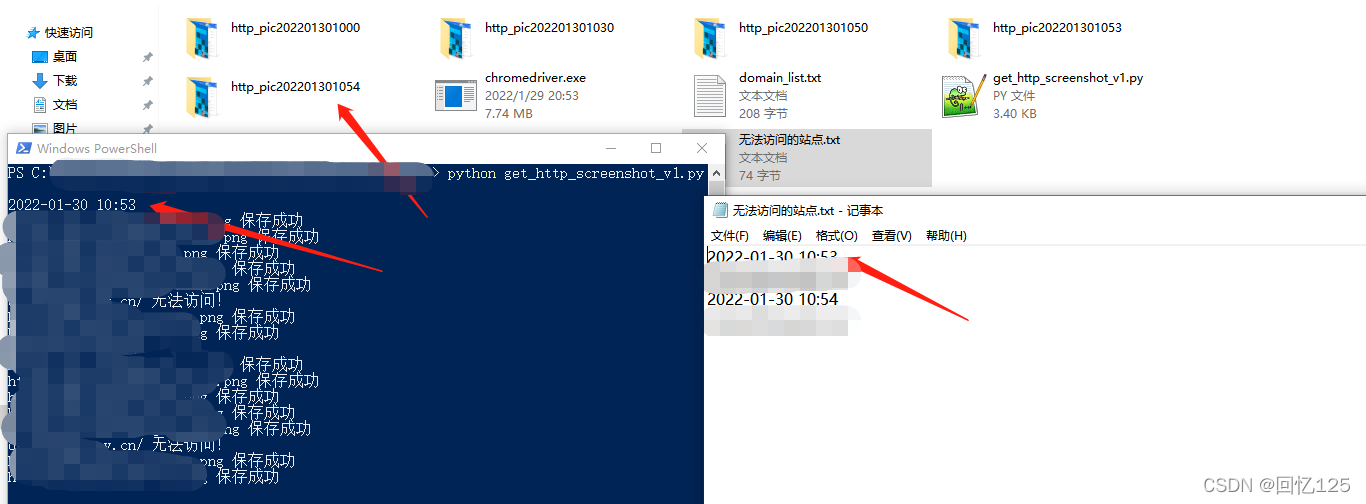
.
备注:seleium需要指定浏览器和匹配driver文件,本脚本使用的是chrome及对应版本driver(driver下载链接http://chromedriver.storage.googleapis.com/index.html)
这篇关于【网站可用性自动化监测】python+seleium的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




