本文主要是介绍【手把手】光说不练假把式,这篇全链路压测实践探索,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Hello,大家好呀,前两篇文章,我们说了下关于全链路压测的意义、整体架构,以及5种压测的方案。
前面两篇基本都属于比较理论的内容,今天这篇咱们来点实践的东西,手把手带你搞出一个压测来
如果不清楚之前两篇的文章的小伙伴,可以先看下,在这里
- 大厂钟爱的全链路压测有什么意义?四种压测方案详细对比分析
- 全链路压测的整体架构设计,以及5种实现方案流量染色方案、数据隔离方案、接口隔离方案、零侵入方案、服务监控方案【代码级别】
7 环境准备
7.1 环境服务列表
需要在虚拟机或者linux服务器启动运行环境
| 服务 | ip | 端口 | 备注 |
|---|---|---|---|
| mysql | 172.18.0.10 | 3306 | 数据库服务 |
| rabbitMQ | 172.18.0.20 | 5672,5672 | RabbitMQ消息服务 |
| redis | 172.18.0.30 | 6379 | Redis缓存服务 |
| nacos | 172.18.0.40 | 8848 | 微服务注册中心 |
| skywalking | 172.18.0.50 | 1234,11800,12800 | 链路追踪APM服务端 |
| skywalking-ui | 172.18.0.60 | 8080 | 链路追踪APM服务UI端 |
7.2 应用服务列表
应用服务可以单独部署或者在idea中启动
| 服务 | ip | 端口 | 备注 |
|---|---|---|---|
| order-service | 127.0.0.1 | 8001 | 订单服务 |
| account-service | 127.0.0.1 | 8002 | 账户服务 |
| storage-service | 127.0.0.1 | 8003 | 数据存储服务 |
| notice-service | 127.0.0.1 | 8004 | 通知服务 |
7.3 docker-compose 编排环境
我们的docker-compose只对环境进行了搭建,具体微服务在本地运行或者在容器运行都可以。
version: '2'
services:mysql:image: mysql:5.7hostname: mysqlcontainer_name: mysqlnetworks:docker-network:ipv4_address: 172.18.0.10ports:- "3306:3306"environment:MYSQL_ROOT_PASSWORD: rootvolumes:- "/tmp/etc/mysql:/etc/mysql/conf.d"- "/tmp/data/mysql:/var/lib/mysql"rabbitMQ:image: rabbitmq:managementhostname: rabbitMQcontainer_name: rabbitMQnetworks:docker-network:ipv4_address: 172.18.0.20ports:- "5672:5672"- "15672:15672"redis:image: redishostname: rediscontainer_name: redisnetworks:docker-network:ipv4_address: 172.18.0.30ports:- "6379:6379"volumes:- "/tmp/etc/redis/redis.conf:/etc/redis/redis.conf"- "/tmp/data/redis:/data"command:redis-server /etc/redis/redis.confnacos:image: nacos/nacos-serverhostname: nacoscontainer_name: nacosdepends_on:- mysqlnetworks:docker-network:ipv4_address: 172.18.0.40ports:- "8848:8848"environment:MODE: standalonevolumes:- "/tmp/etc/nacos/application.properties:/home/nacos/conf/application.properties"skywalking:image: apache/skywalking-oap-serverhostname: skywalkingcontainer_name: skywalkingnetworks:docker-network:ipv4_address: 172.18.0.50ports:- "1234:1234"- "11800:11800"- "12800:12800"skywalkingui:image: apache/skywalking-uihostname: skywalkinguicontainer_name: skywalkinguidepends_on:- skywalkingnetworks:docker-network:ipv4_address: 172.18.0.60environment:SW_OAP_ADDRESS: 172.18.0.50:12800ports:- "8080:8080"
networks:docker-network:ipam:config:- subnet: 172.18.0.0/16gateway: 172.18.0.1
7.4 初始化数据
-
初始化用户数据以及产品数据
-
将feign,hystrix,ribbon等统一配置配置到nacos
# 配置超时时间 feign:hystrix:enabled: true #开启熔断httpclient:enabled: true hystrix:threadpool:default:coreSize: 50maxQueueSize: 1500queueSizeRejectionThreshold: 1000command:default:execution:timeout:enabled: trueisolation:thread:timeoutInMilliseconds: 60000 ribbon:ConnectTimeout: 10000ReadTimeout: 50000
8 全链路压测测试
8.1 jmeter配置
配置好压测数据,并且配置压测线程数1000 进行10轮压测
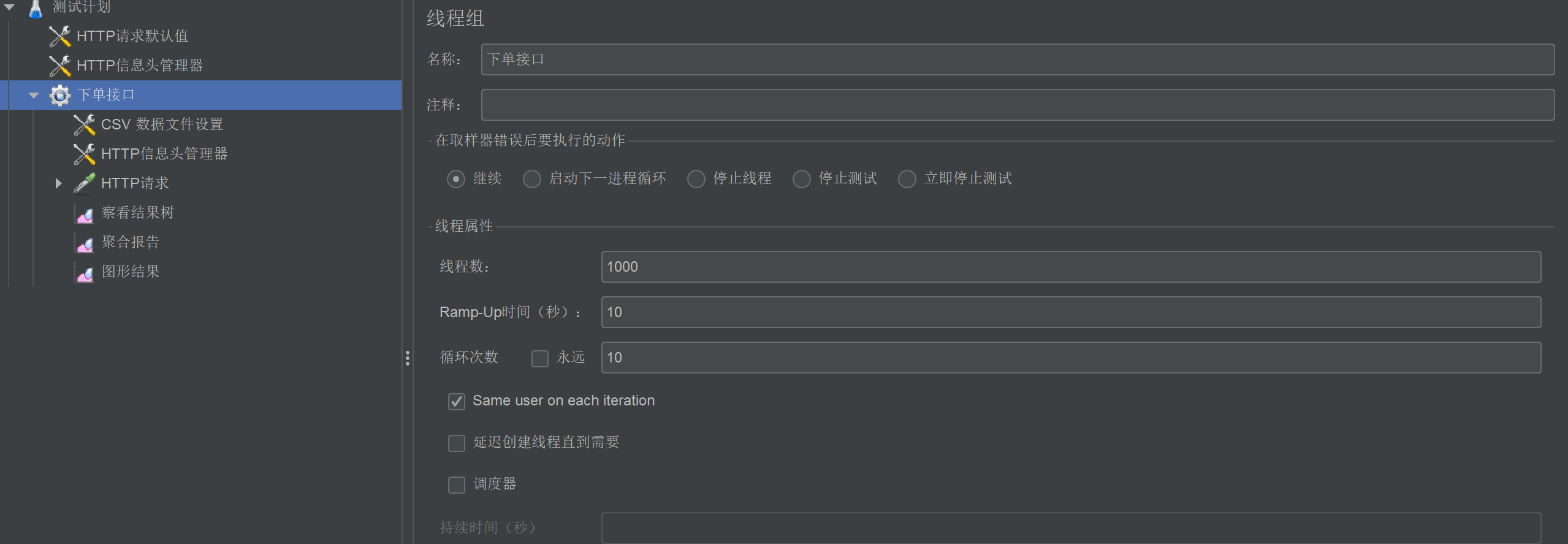
8.2 第一轮压测
8.2.1 链路分析优化
我们找到一个调用时长1S左右的链路,分析发现在存储服务调用时,耗时较长,但是数据库调用耗时并不长,基本说明是存储服务的连接池耗尽导致调用过长。
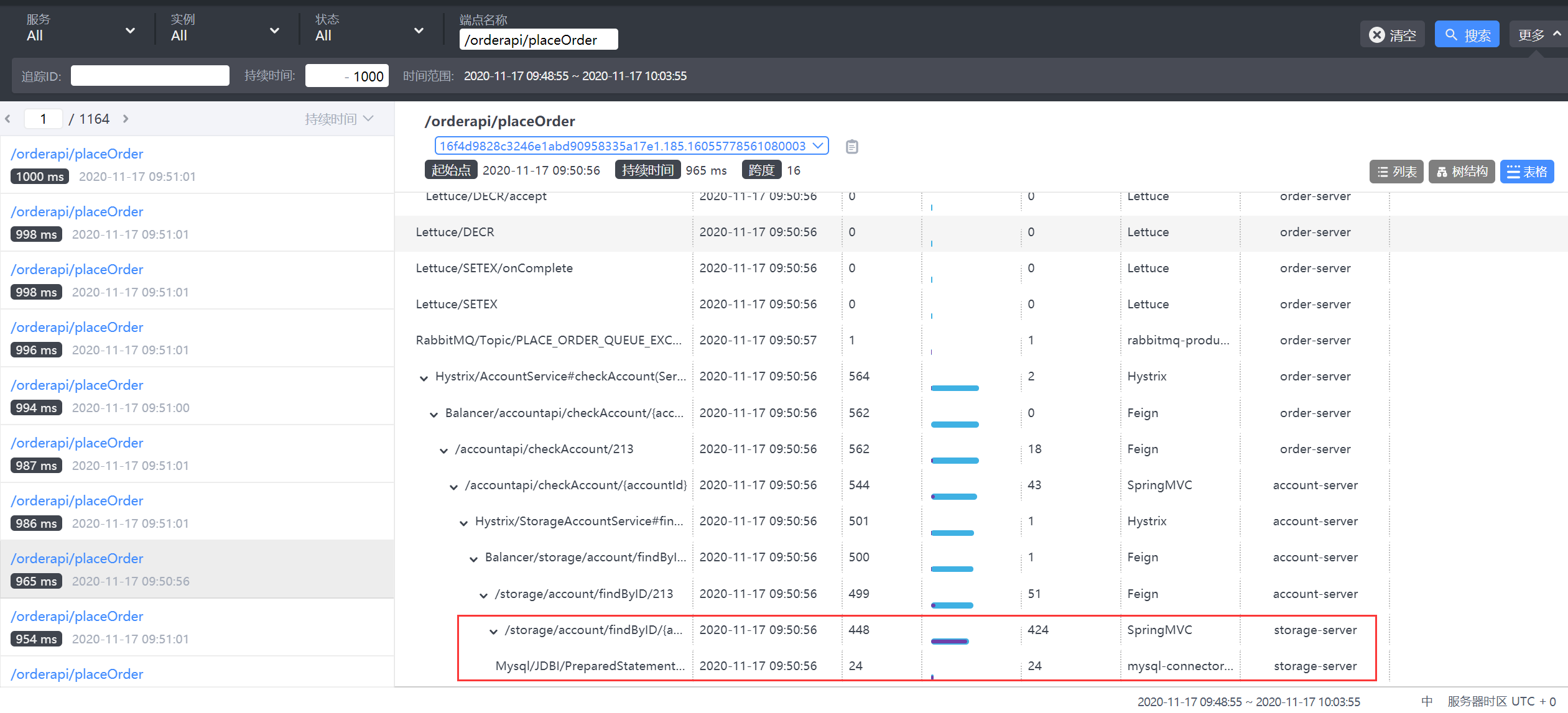
8.2.2 数据库连接池优化
调整存储服务的连接池,由原来的最大10 改为100
initialSize: 10
minIdle: 20
maxActive: 100
8.3 第二轮压测
结果已经由原来的服务内部的耗时 变为了fegin的耗时,这种情况下可以考虑使用fegin的连接池优化或者新增节点
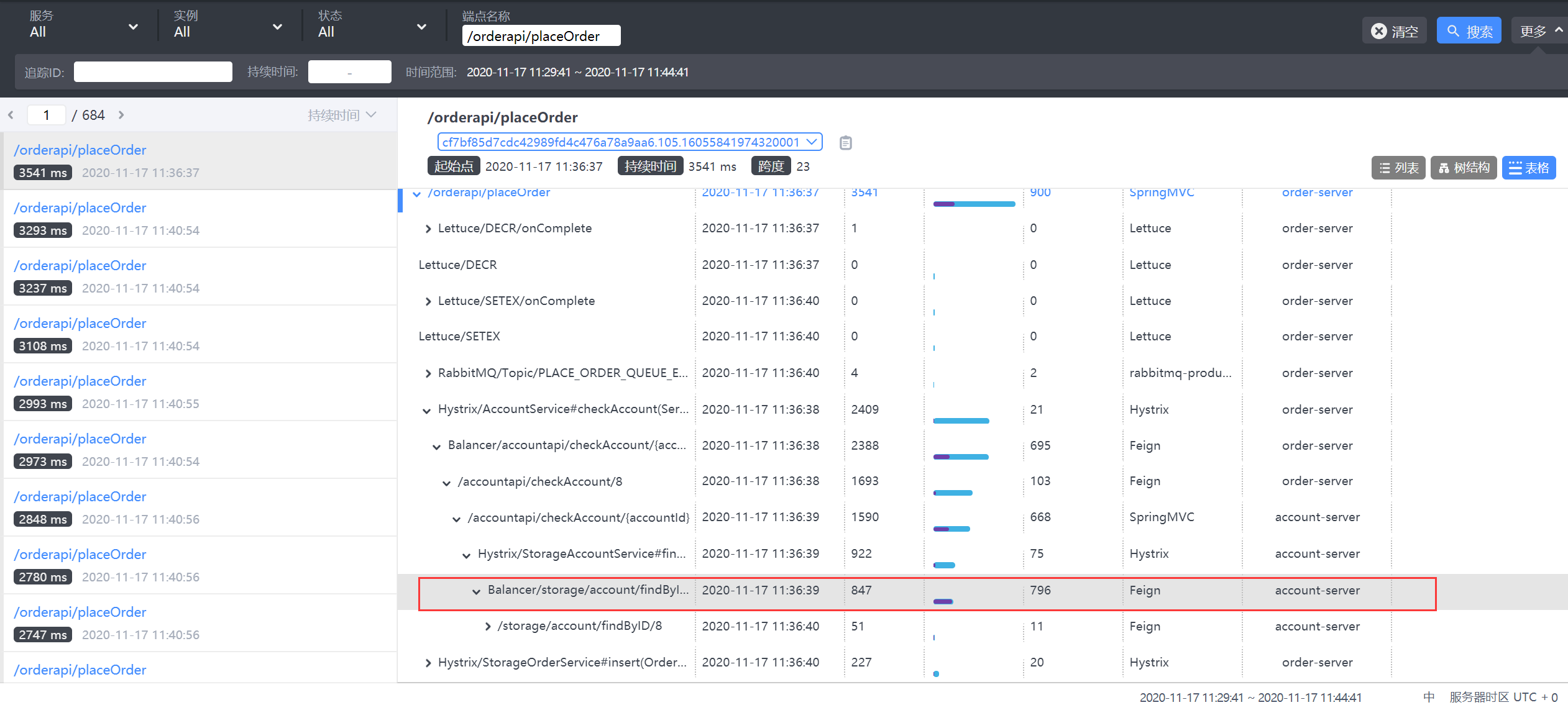
8.3.1 观察消费节点
发现消费速度很慢,产生了大量消息堆积
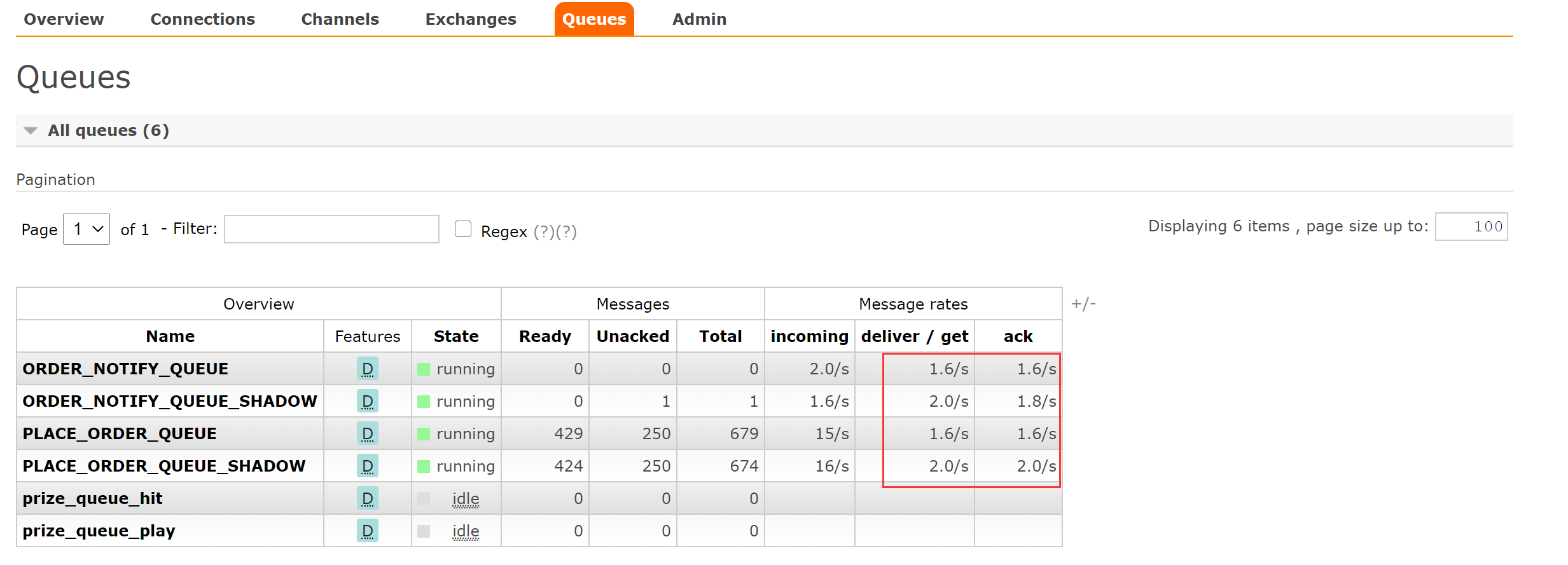
检查
storage-service的actualPlaceOrder端点信息
发现平均响应时间在200ms左右
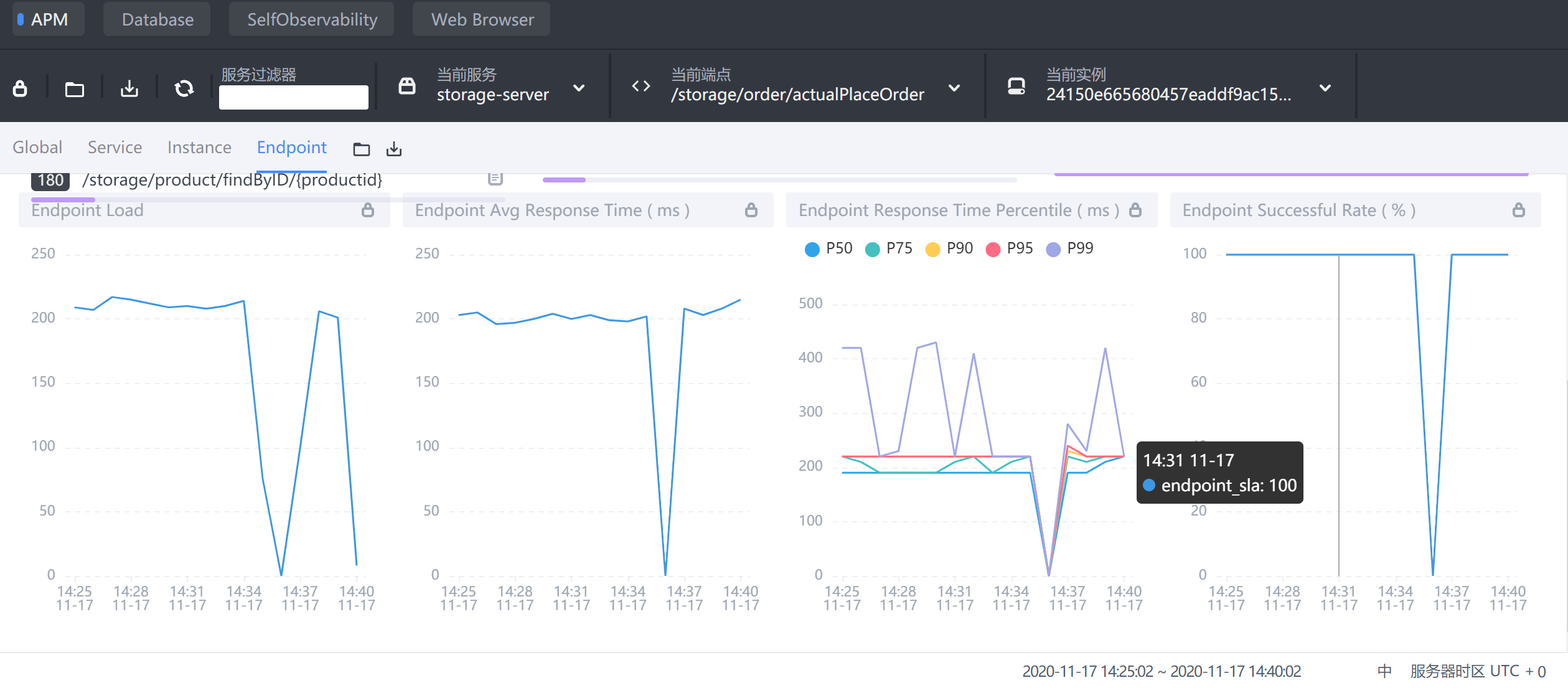
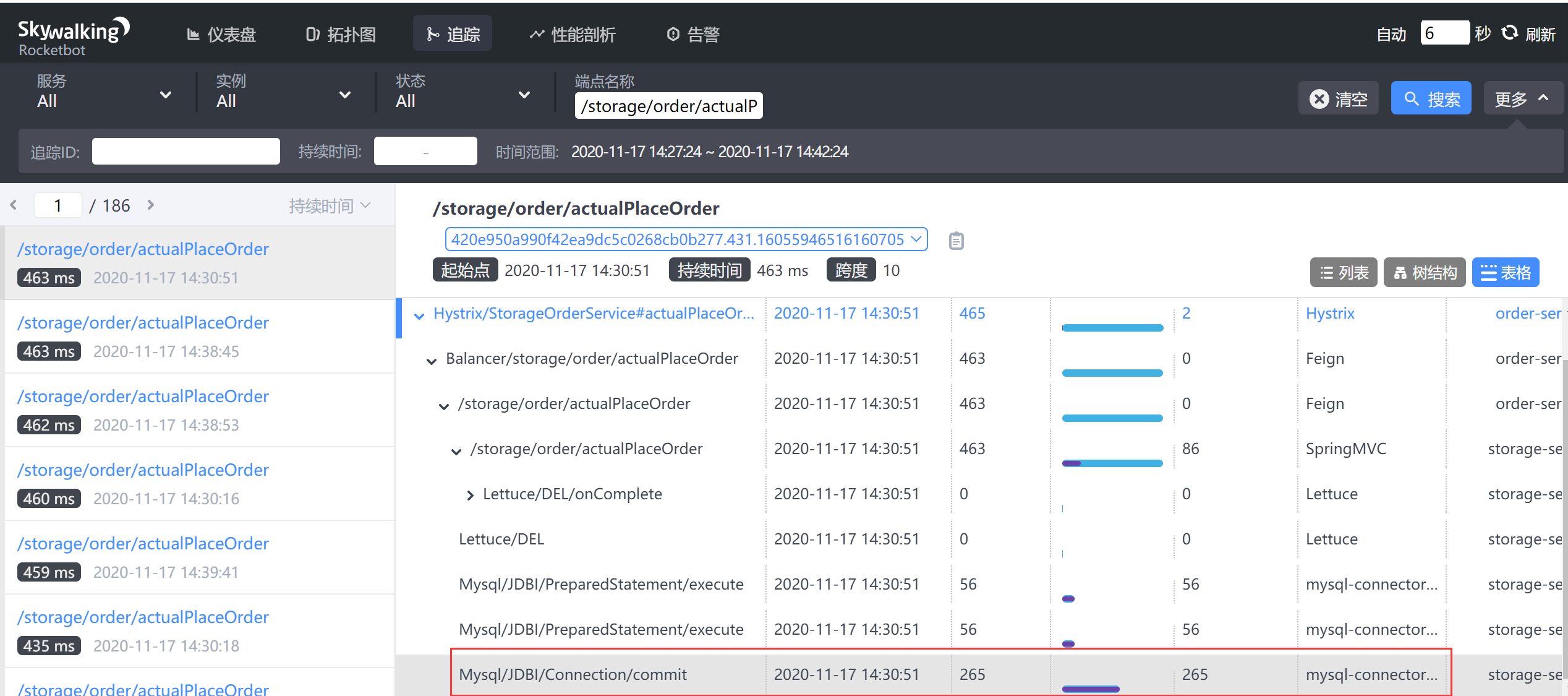
检查断点链路/storage/order/actualPlaceOrder
发现是事务提交慢造成的,这个时候就需要优化mysql服务器了
9 Skywalking 使用
9.1 Skywalking 模块栏目

Skywalking web UI 主要包括如下几个大的功能模块:
- 仪表盘:查看被监控服务的运行状态
- 拓扑图:以拓扑图的方式展现服务直接的关系,并以此为入口查看相关信息
- 追踪:以接口列表的方式展现,追踪接口内部调用过程
- 性能剖析:单独端点进行采样分析,并可查看堆栈信息
- 告警:触发告警的告警列表,包括实例,请求超时等。
- 自动刷新:刷新当前数据内容。
9.2 仪表盘

- 第一栏:不同内容主题的监控面板,应用/数据库/容器等
- 第二栏:操作,包括编辑/导出当前数据/倒入展示数据/不同服务端点筛选展示
- 第三栏:不同纬度展示,服务/实例/端点
9.3 展示栏
9.3.1 Global全局维度
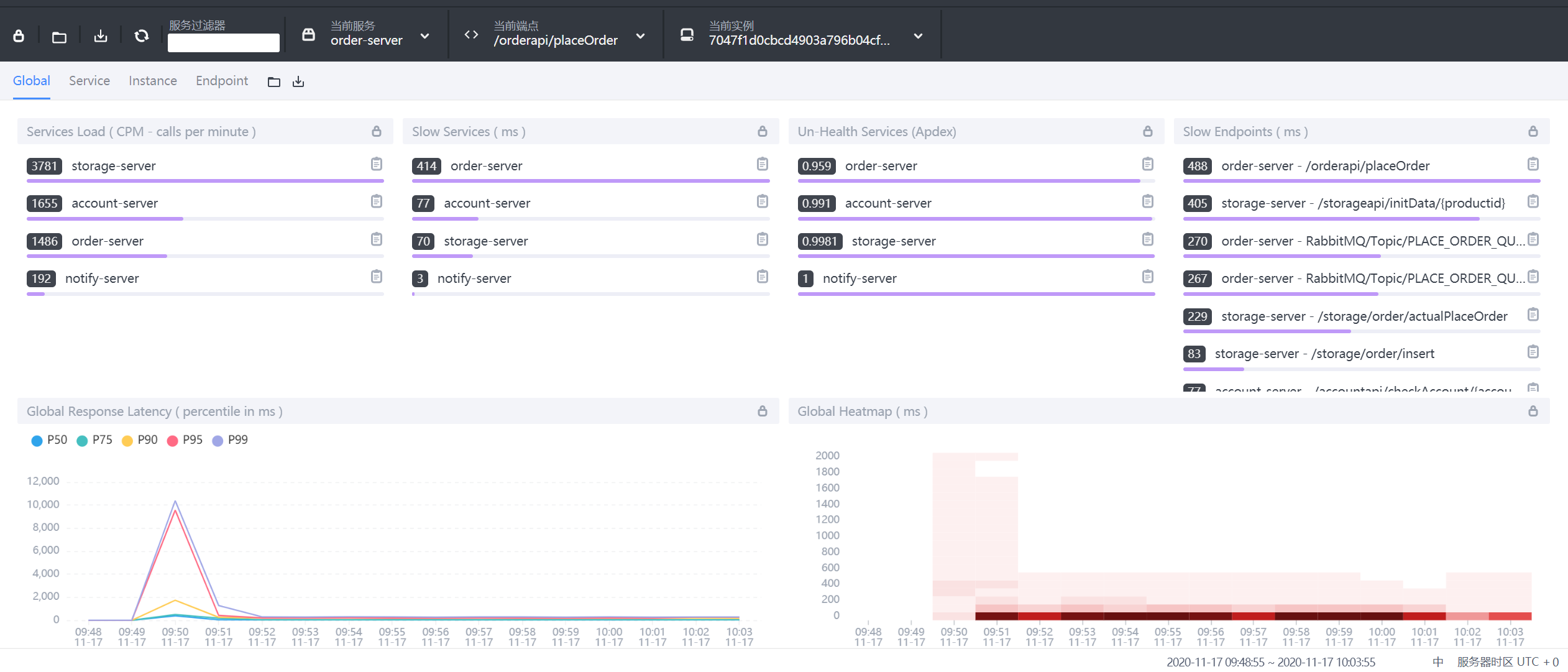
- 第一栏:Global、Server、Instance、Endpoint不同展示面板,可以调整内部内容
- Services load:服务每分钟请求数
- Slow Services:慢响应服务,单位ms
- Un-Health services(Apdex):Apdex性能指标,1为满分。
- Global Response Latency:百分比响应延时,不同百分比的延时时间,单位ms
- Global Heatmap:服务响应时间热力分布图,根据时间段内不同响应时间的数量显示颜色深度
- 底部栏:展示数据的时间区间,点击可以调整。
9.3.2 Service服务维度
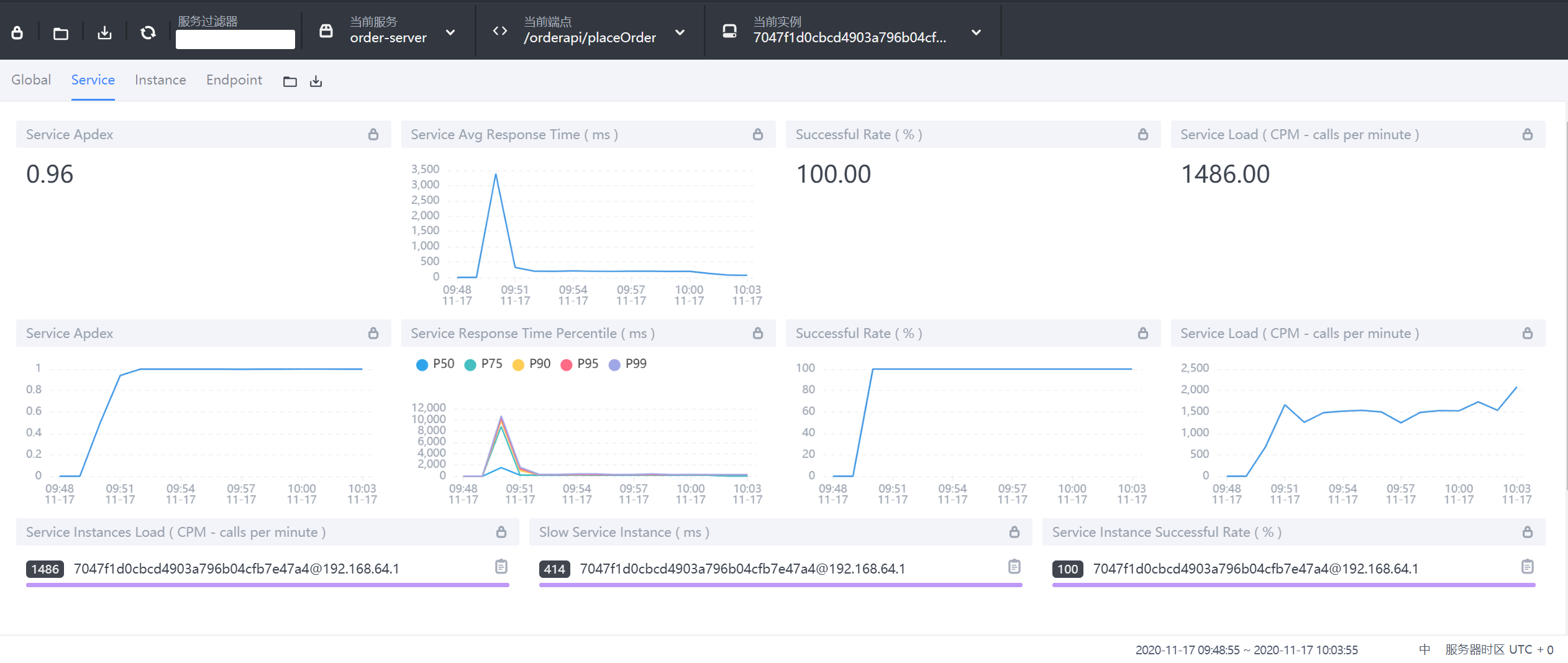
- Service Apdex(数字):当前服务的评分
- Service Apdex(折线图):不同时间的Apdex评分
- Successful Rate(数字):请求成功率
- Successful Rate(折线图):不同时间的请求成功率
- Servce Load(数字):每分钟请求数
- Servce Load(折线图):不同时间的每分钟请求数
- Service Avg Response Times:平均响应延时,单位ms
- Global Response Time Percentile:百分比响应延时
- Servce Instances Load:每个服务实例的每分钟请求数
- Show Service Instance:每个服务实例的最大延时
- Service Instance Successful Rate:每个服务实例的请求成功率
9.3.3 Instance实例维度
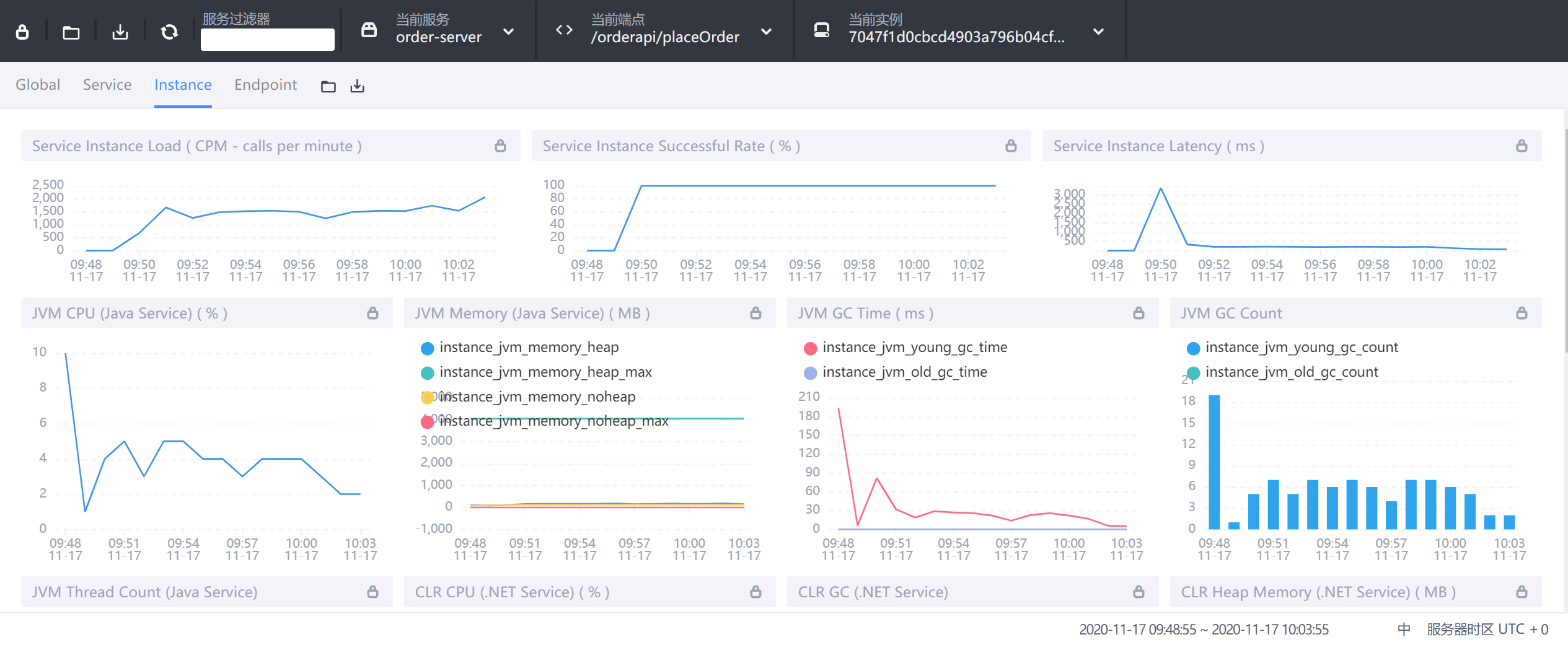
- Service Instance Load:当前实例的每分钟请求数
- Service Instance Successful Rate:当前实例的请求成功率
- Service Instance Latency:当前实例的响应延时
- JVM CPU:jvm占用CPU的百分比
- JVM Memory:JVM内存占用大小,单位m
- JVM GC Time:JVM垃圾回收时间,包含YGC和OGC
- JVM GC Count:JVM垃圾回收次数,包含YGC和OGC
- CLR XX:类似JVM虚拟机,这里用不上就不做解释了
9.3.4 Endpoint端点(API)维度
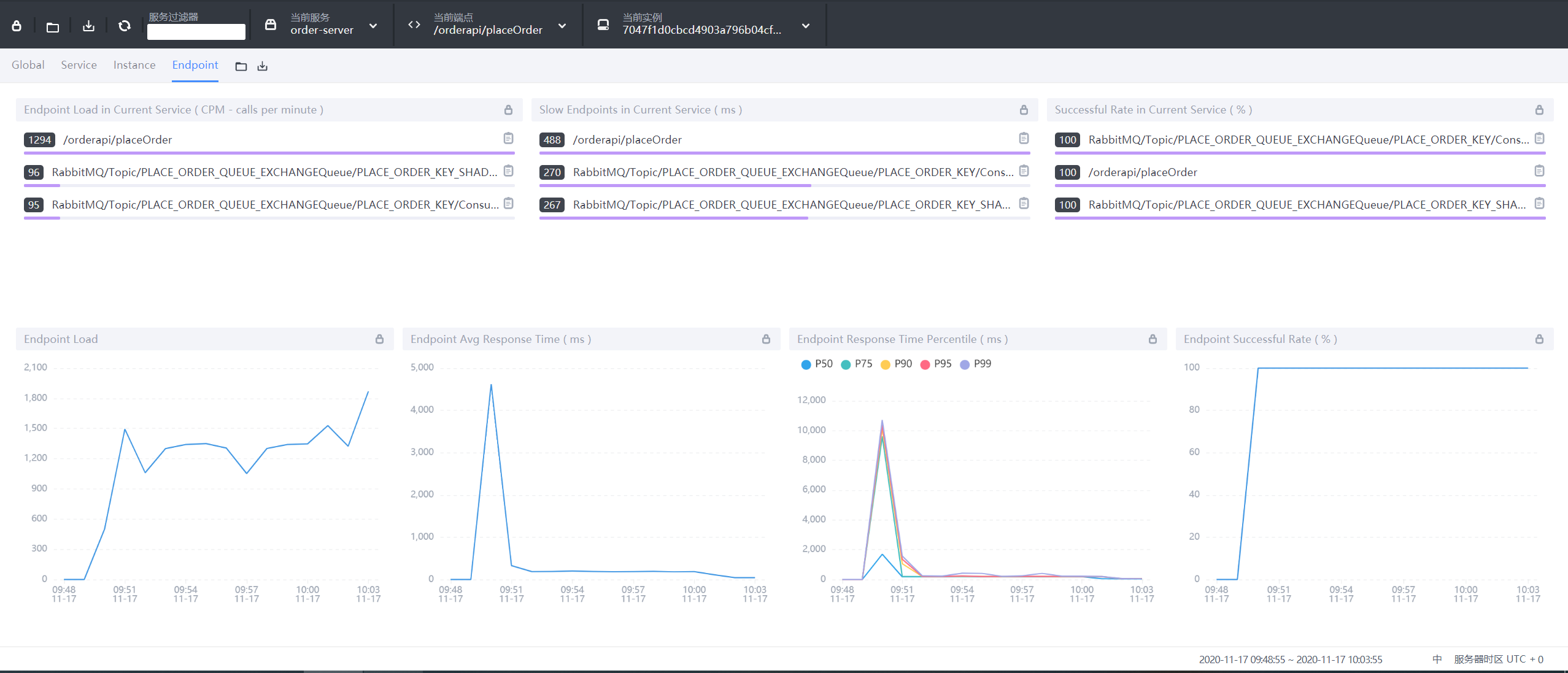
- Endpoint Load in Current Service:每个端点的每分钟请求数
- Slow Endpoints in Current Service:每个端点的最慢请求时间,单位ms
- Successful Rate in Current Service:每个端点的请求成功率
- Endpoint Load:当前端点每个时间段的请求数据
- Endpoint Avg Response Time:当前端点每个时间段的请求行响应时间
- Endpoint Response Time Percentile:当前端点每个时间段的响应时间占比
- Endpoint Successful Rate:当前端点每个时间段的请求成功率
9.4 拓扑图
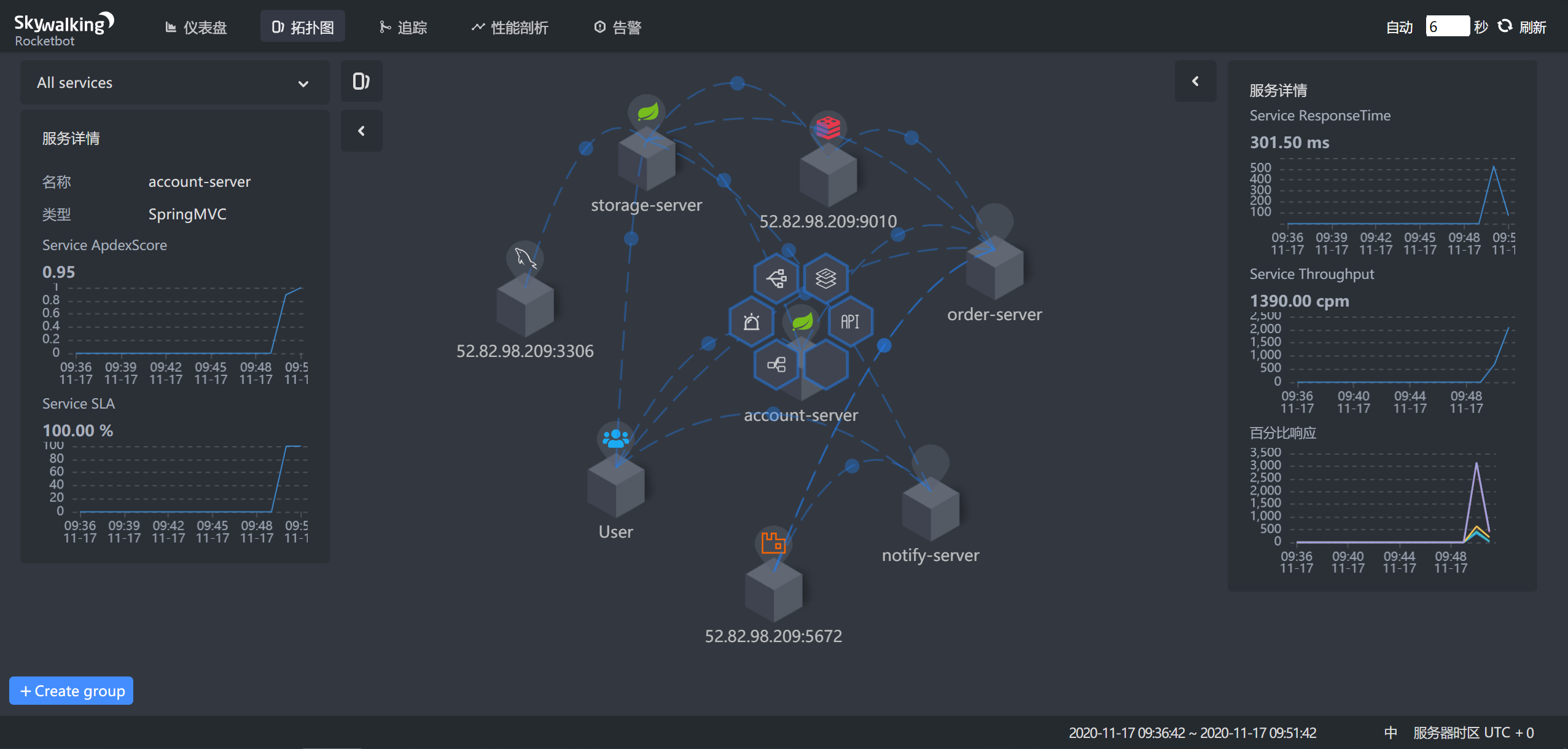
- 1:选择不同的服务关联拓扑
- 2:查看单个服务相关内容
- 3:服务间连接情况
- 4:分组展示服务拓扑
9.5 追踪
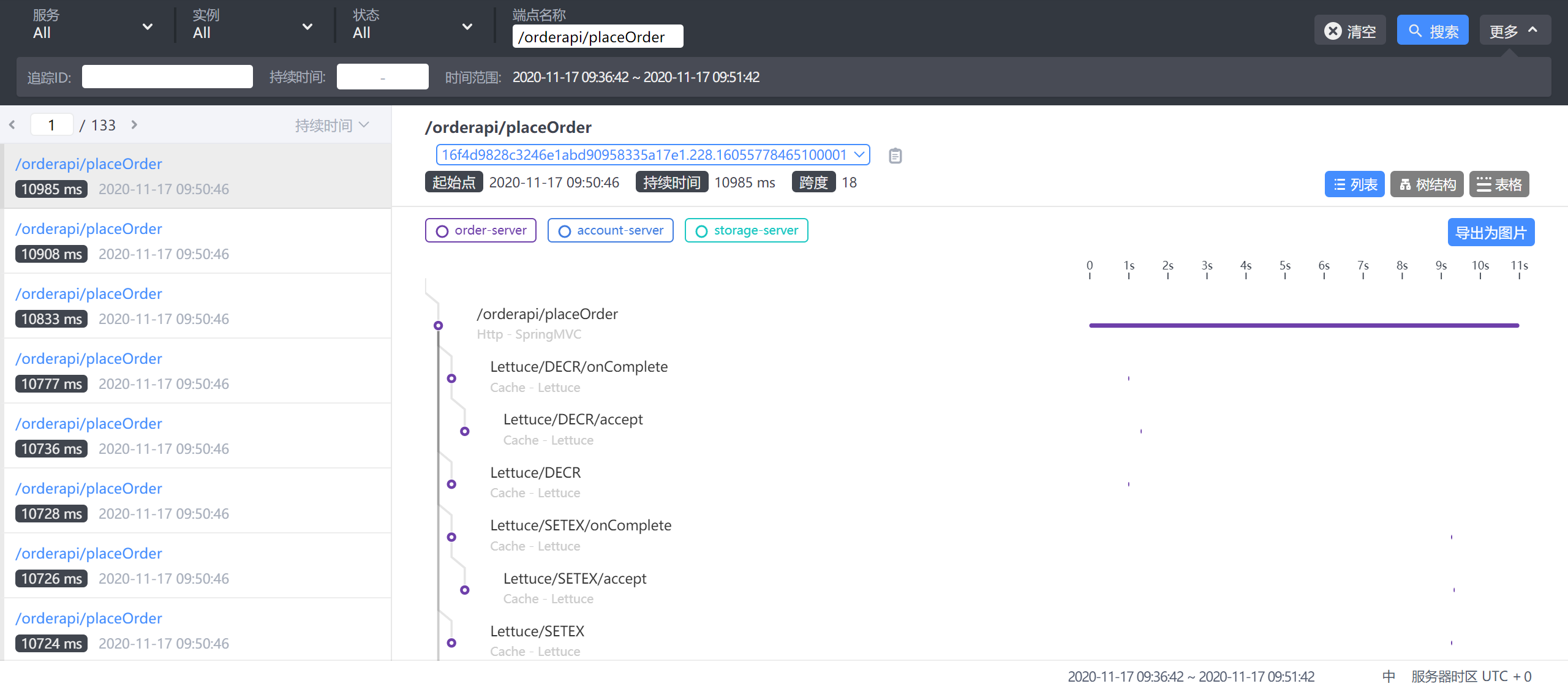
- 左侧:api接口列表,红色-异常请求,蓝色-正常请求
- 右侧:api追踪列表,api请求连接各端点的先后顺序和时间
9.6 性能剖析
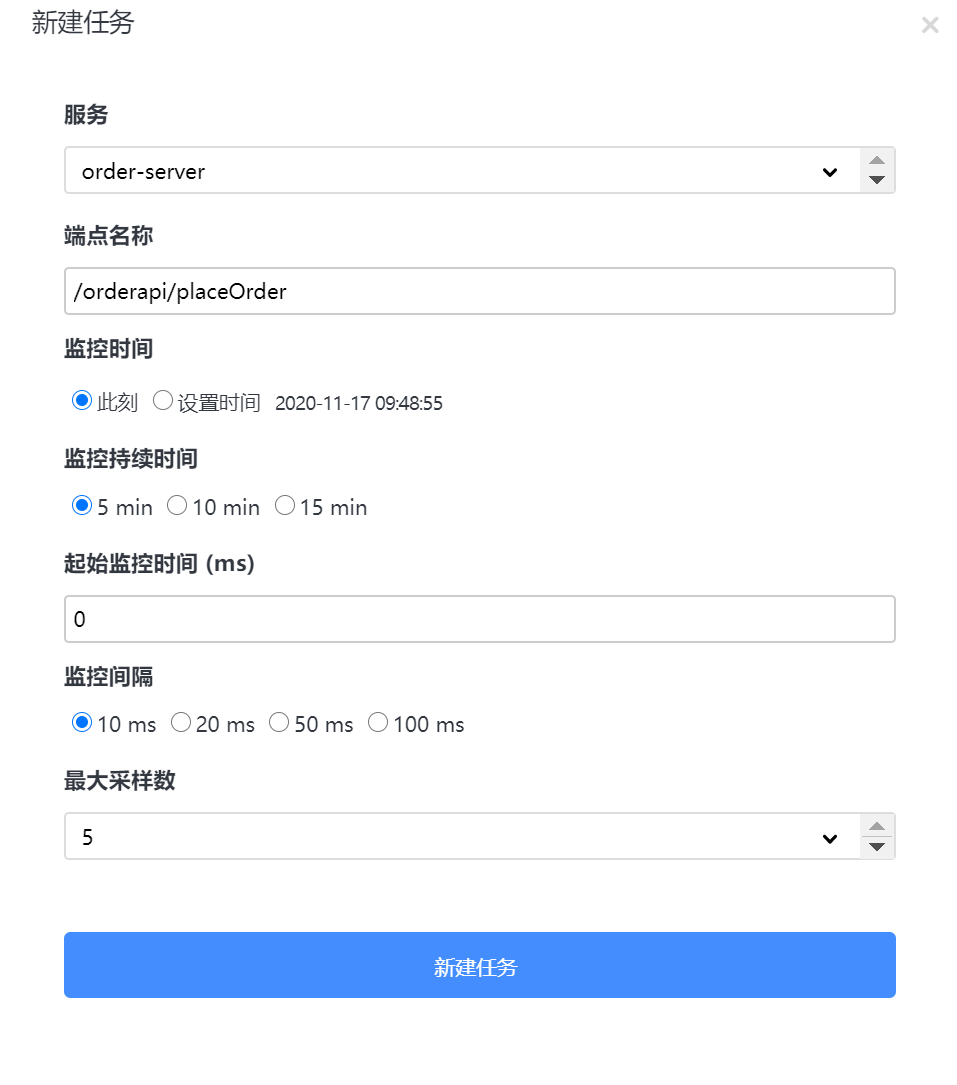
- 服务:需要分析的服务
- 端点:链路监控中端点的名称,可以再链路追踪中查看端点名称
- 监控时间:采集数据的开始时间
- 监控持续时间:监控采集多长时间
- 起始监控时间:多少秒后进行采集
- 监控间隔:多少秒采集一次
- 最大采集数:最大采集多少样本
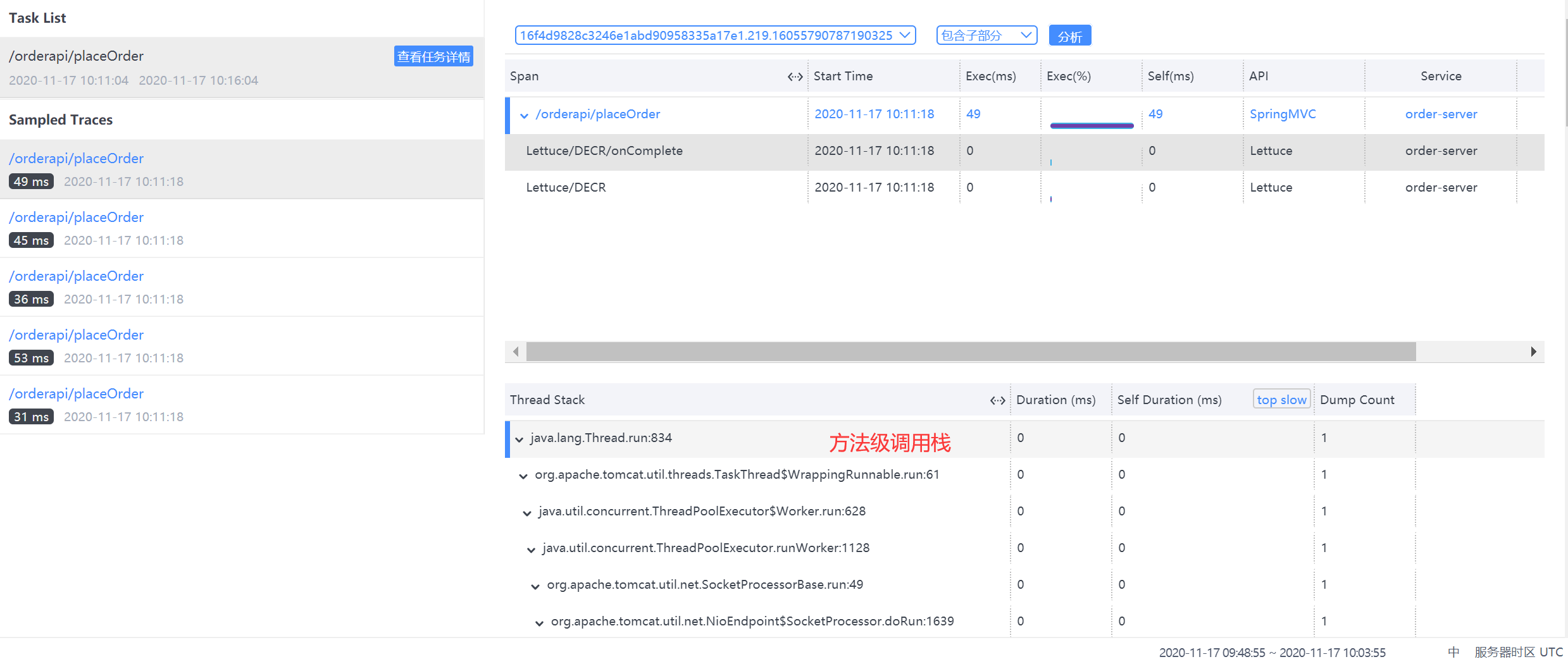
查看监控结果
本文由
传智教育博学谷教研团队发布。如果本文对您有帮助,欢迎
关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。转载请注明出处!
这篇关于【手把手】光说不练假把式,这篇全链路压测实践探索的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








