本文主要是介绍【Redis源码】ziplist压缩表(八),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:
压缩表是一个连续内存空间的线性结构,元素之间紧挨着存储,没有任何空隙。redis为了节省空间,当使用zset和hash容器对象时再元素个数较少时采取了压缩表(ziplist)进行存储。
redis版本:4.0.0

1.压缩表结构介绍
压缩表构成如下:
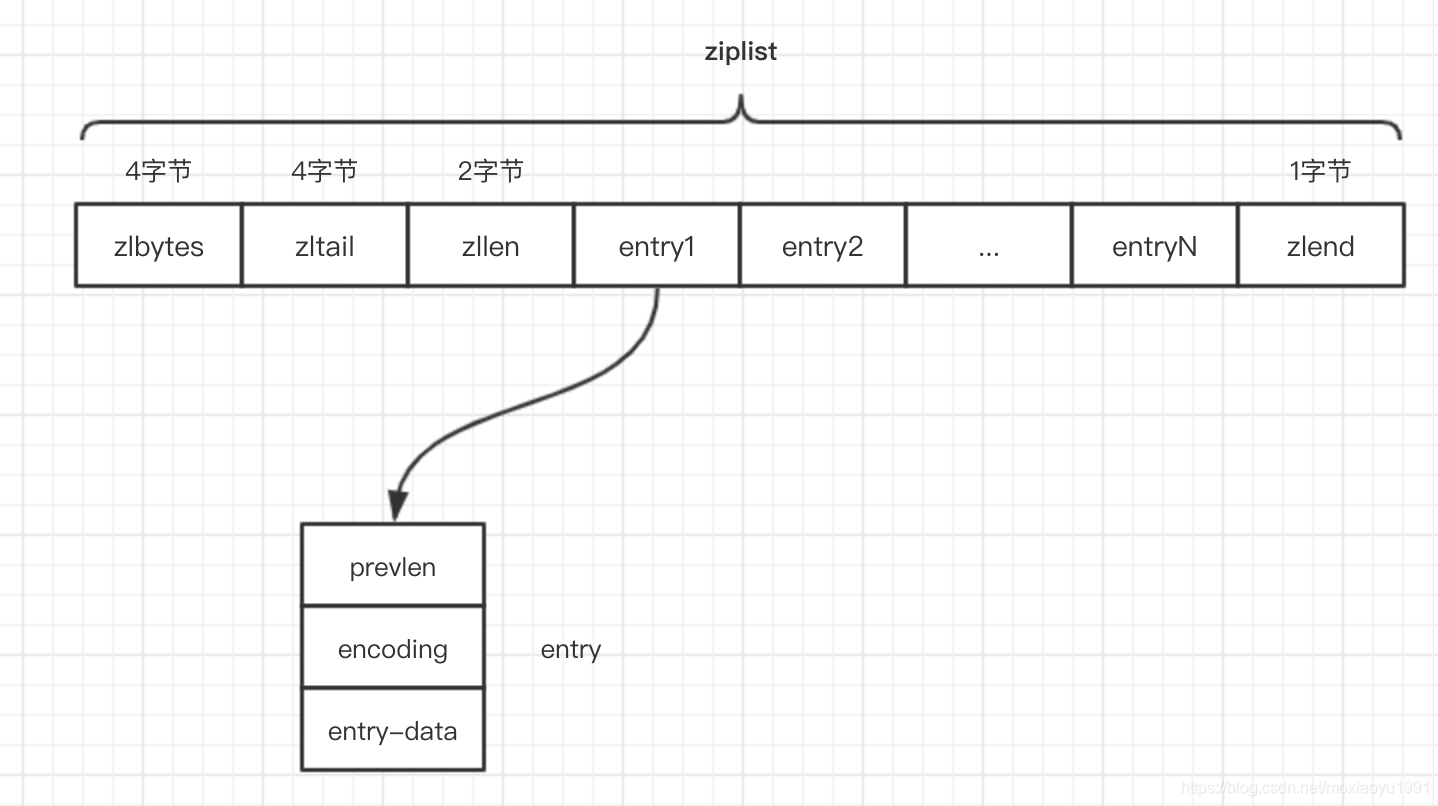
zlbytes :
压缩表字节长度,类型uint32_t占用4个字节,需要存储此值才能调整整个结构的大小。压缩表的大小为2^32 - 1。
zltail:
是列表中最后一个条目的偏移量,类型uint32_t占用4个字节。
zllen:
压缩表个数,类型uint16_t占用2个字节,个数最大数量为2^16-1,也就是65535。必须遍历整个压缩表才能知道它的个数。
entry:
压缩表存储元素,可以是字节数组或者是整数。
zlend:
结束标识,类型uint8_t占用1个字节。该值为255,对应ZIP_END宏,16进制为0xFF。
压缩表各字段间的获取宏如下,ziplist.c中:
//ziplist的zlbytes字段
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))//ziplist的zltail字段
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))//ziplist的zllen字段
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))//最后一个字节,对应zlend字段
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)//ziplist头大小10字节
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))//尾大小1字节
#define ZIPLIST_END_SIZE (sizeof(uint8_t))//ziplist数据头入口也就是第一个entry结构位置
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)//ziplist数据最后一个entry入口,最后一个entry结构位置
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
2.压缩表entry介绍
prevlen:
压缩表中前一个entry的长度,占用1个或者5个字节。
1)若前一个entry占用的字节数小于254,则prevlen字段占1个字节。
2)若前一个entry占用字节数大于或等于254,则prevlen字段占用5个字节。注意此时第一个字节固定为254,即0xFE,另外4个字节以uint32_t存储值。
encoding:
entry的编码,表示当前entry存储数据的类型和数据的长度。
字符串编码规则如下:
| 编码示例 | 字节长度 | 备注 |
| 00pppppp | 1字节 | 长度小于或等于63字节(6位)的字符串值。 “pppppp”表示无符号的6位长度。 |
| 01pppppp|qqqqqqqq | 2字节 | 长度小于或等于16383字节(14位)的长度。 |
| 10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt | 5字节 | 特大字符串,长度小于等于 4294967295 (32位)字节的字节数组; |
整型编码规则如下:
| 编码示例 | 字节长度 | 备注 |
| 00pppppp | 1字节 | 长度小于或等于63字节(6位)的字符串值。 “pppppp”表示无符号的6位长度。 |
| 01pppppp|qqqqqqqq | 2字节 | 长度小于或等于16383字节(14位)的长度。 |
| 10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt | 5字节 | 特大字符串,长度小于等于 4294967295 (32位)字节的字节数组; |
entry-data:
数据存储的值。大小由encode
对应的编码宏如下,ziplist.c中:
#define ZIP_STR_MASK 0xc0
#define ZIP_INT_MASK 0x30
#define ZIP_STR_06B (0 << 6)
#define ZIP_STR_14B (1 << 6)
#define ZIP_STR_32B (2 << 6)
#define ZIP_INT_16B (0xc0 | 0<<4)
#define ZIP_INT_32B (0xc0 | 1<<4)
#define ZIP_INT_64B (0xc0 | 2<<4)
#define ZIP_INT_24B (0xc0 | 3<<4)
#define ZIP_INT_8B 0xfe根据以上内容,咱们可以看一下如下hash命令的ziplist存储结构
127.0.0.1:6379> hmset name5 a zhaoyu b hello
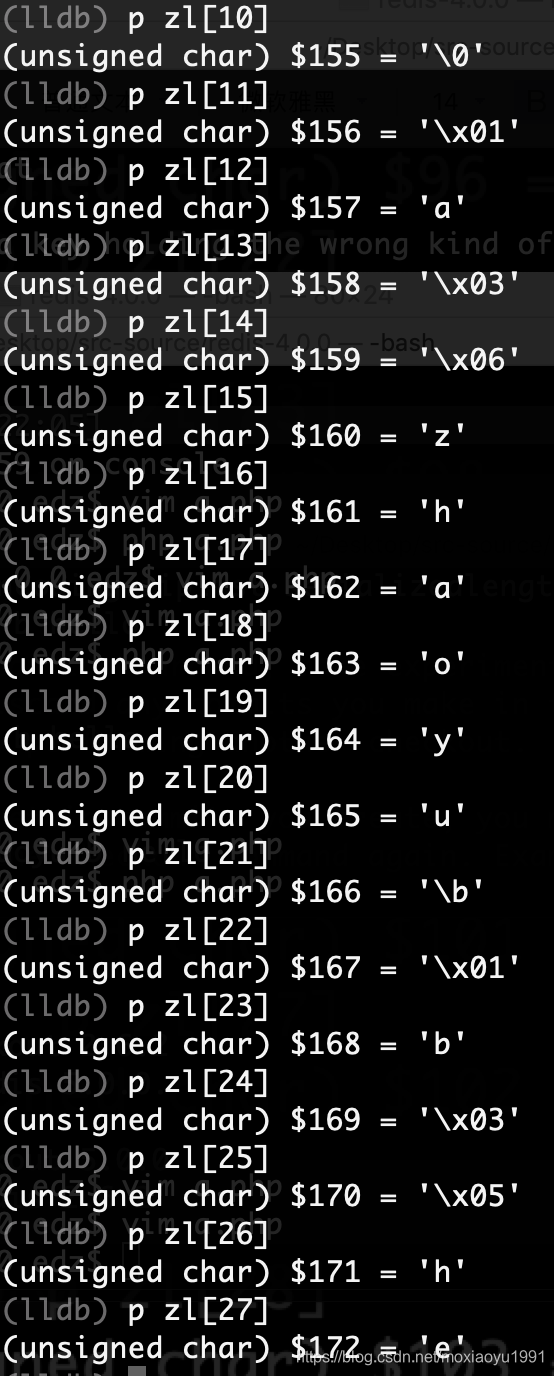
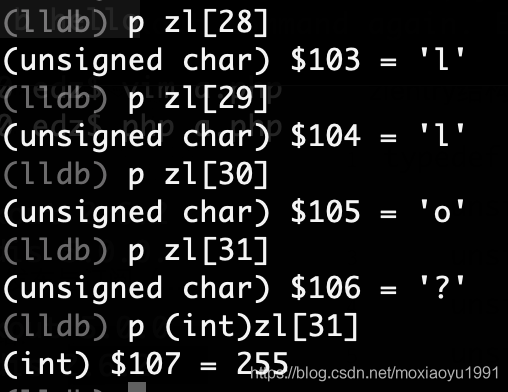
看上面两张图,解析name5点hash数据存储结构。zl为ziplist的字节数组。
1) 0 ~ 9的10个字节对应zlbytes、zltail、zllen三个字段。
2)然后从zl[10]开始,zl[10]等于prevlen字段当前是0。因为zl[10]是第一个entry没有之前所以为0。然后zl[11]等于十六进制0x1,在二进制下是0000 0001,开头两位是00说明对应1字节的字符数组。其次就是占用一个字节,所以我们zl[12]得到a键。也就是我们命令行中的hmset name5 a中的a。
3)从zl[13]对应prevlen字段,当前是0x3。说明前一个entry是3个字节。确实是 zl[10] ~zl[12]三个字节。然后zl[14]等于十六进制0x6,说明是6个字节的的字符数组。刚好得到zhaoyu 6个字符。
4)zl[31]当前等于10进制255对应0xFF。也就是结尾。
zlentry结构体,ziplist.c中:
typedef struct zlentry {unsigned int prevrawlensize; /* 前一个元素的内存大小的编码空间 */unsigned int prevrawlen; /* 前一个元素的内存大小. */unsigned int lensize; /* 当前元素value部分占用内存大小的编码空间 */unsigned int len; /* 当前元素value部分占用内存大小 */unsigned int headersize; /* 当前元素value部分占用内存大小 */unsigned char encoding; /* 编码类型,标志value的类型和占用的字节数. */unsigned char *p; /* 内容 */
} zlentry;zlentry并不是实际的zl中存储的,只是用作解析entry计算使用的结构体。
解码entry函数,ziplist.c中:
void zipEntry(unsigned char *p, zlentry *e) {ZIP_DECODE_PREVLEN(p, e->prevrawlensize, e->prevrawlen); //解码prevlen字段ZIP_DECODE_LENGTH(p + e->prevrawlensize, e->encoding, e->lensize, e->len); //解码encoding长度e->headersize = e->prevrawlensize + e->lensize;e->p = p;
}
解码prevlen字段宏,ziplist.c中:
#define ZIP_BIG_PREVLEN 254#define ZIP_DECODE_PREVLEN(ptr, prevlensize, prevlen) do { \ZIP_DECODE_PREVLENSIZE(ptr, prevlensize); \if ((prevlensize) == 1) { \(prevlen) = (ptr)[0]; \} else if ((prevlensize) == 5) { \assert(sizeof((prevlensize)) == 4); \memcpy(&(prevlen), ((char*)(ptr)) + 1, 4); \memrev32ifbe(&prevlen); \} \
} while(0);#define ZIP_DECODE_PREVLENSIZE(ptr, prevlensize) do { \if ((ptr)[0] < ZIP_BIG_PREVLEN) { \(prevlensize) = 1; \} else { \(prevlensize) = 5; \} \
} while(0);该宏其实是解码prevrawlensize字段,是1个字节还是5个字节空间。
解码的长度宏如下ziplist.c中:
#define ZIP_DECODE_LENGTH(ptr, encoding, lensize, len) do { \ZIP_ENTRY_ENCODING((ptr), (encoding)); \if ((encoding) < ZIP_STR_MASK) { //判断是否为字节数组 \if ((encoding) == ZIP_STR_06B) { //63字节的字节数组 \(lensize) = 1; \(len) = (ptr)[0] & 0x3f; \} else if ((encoding) == ZIP_STR_14B) { //16383字节内的字节数组 \(lensize) = 2; \(len) = (((ptr)[0] & 0x3f) << 8) | (ptr)[1]; \} else if ((encoding) == ZIP_STR_32B) { //特大字节数组 \(lensize) = 5; \(len) = ((ptr)[1] << 24) | \((ptr)[2] << 16) | \((ptr)[3] << 8) | \((ptr)[4]); \} else { \panic("Invalid string encoding 0x%02X", (encoding)); \} \} else { //整型 \(lensize) = 1; \(len) = zipIntSize(encoding); \} \
} while(0);获得zip的整型大小,可以看一下整型编码规则表,代码ziplist.c中:
unsigned int zipIntSize(unsigned char encoding) {switch(encoding) {case ZIP_INT_8B: return 1; //case ZIP_INT_16B: return 2;case ZIP_INT_24B: return 3;case ZIP_INT_32B: return 4;case ZIP_INT_64B: return 8;}if (encoding >= ZIP_INT_IMM_MIN && encoding <= ZIP_INT_IMM_MAX)return 0; /* 4 bit immediate */panic("Invalid integer encoding 0x%02X", encoding);return 0;
}3.压缩表ziplist的API说明
| 函数名称 | 用途 | 复杂度 | 连锁更新 |
| ziplistNew | 创建一个新的压缩表 | O(1) | 无 |
| ziplistPush | 创建一个包含给定值的新节点, 并将这个新节点添加到压缩列表的表头或者表尾 | 平均 O(N^2) | 使用 |
| ziplistInsert | 将包含给定值的新节点插入到给定节点之后 | 平均 O(N^2) | 使用 |
| ziplistIndex | 返回压缩列表给定索引上的节点 | O(N) | 无 |
| ziplistFind | 在压缩列表中查找并返回包含了给定值的节点 | 因为节点的值可能是一个字节数组, 所以检查节点值和给定值是否相同的复杂度为 O(N^2) | 无 |
| ziplistNext | 返回给定节点的下一个节点 | O(1) | 无 |
| ziplistPrev | 返回给定节点的前一个节点 | O(1) | 无 |
| ziplistGet | 获取给定节点所保存的值 | O(1) | 无 |
| ziplistDelete | 从压缩列表中删除给定的节点 | 平均 O(N^2) | 使用 |
| ziplistDeleteRange | 删除压缩列表在给定索引上的连续多个节点 | 平均 O(N^2) | 使用 |
| ziplistBlobLen | 返回压缩列表目前占用的内存字节数 | O(1) | 无 |
| ziplistLen | 返回压缩列表目前包含的节点数量 | 节点数量小于 65535 时 O(N) | 无 |
总结
1)ziplist在zset和hash中使用到,元素个数较少时用到。
2)压缩表是一个字节数组,比较紧凑的结构。
3)压缩表可以存储存储多个节点,也就是entry。每个节点可以存储字节数组和整型两种数据。
4)压缩表支持最大个数65535个。
5)压缩表插入和删除可能会引起连锁更新。
这篇关于【Redis源码】ziplist压缩表(八)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







