本文主要是介绍量化研究 | 残差动量策略刻画与构建(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

致力于分享量化策略,培训视频,Python,程序化交易等相关内容
作者简介
吕洋洋
某大型资管公司在职量化策略研究员,熟悉数据清洗工作,擅于运用宏观因子、行业因子等进行对期货品种价格影响建模与相关性分析,理解机器学习多元回归法,SVM,XGboost,金融时间序列等底层算法逻辑,部分算法可自定义函数封装。掌 握各种机器学习包与数据计算分析包的运用。包括不限于:Alphalens,pandans,爬虫技术,sklearn,statsmodels 等。
『正文』
ˇ
引言
本期是之前“复权系列”量化研究课题探究的新篇章,本期相对传统CTA策略研究,在基于套利的逻辑基础上,开辟了新的CTA动量捕捉模式。
废话不多说,直接进入正题(笔者最近比较忙,没工夫闲扯了)。残差——该词来源于统计学中的线性回归,回归后无法解释的那部分既是残差,英文称为residual。
一般情况对两组时间序列数据进行回归是统计套利干的事儿,我们如何利用到CTA当中,刻画出择时信号?下面作为该系列的首篇,也是本课题研究的首篇,就先从逻辑→策略构建→代码,一步一步的来构建和实现。
逻辑
在套利当中,我们一般做的是“跨期”、“跨品种”两种套利,但是套利的玩法有很多,其中一种便是将两种具有协整关系的标的资产进行回归,根据回归后的残差进行多空开仓进行套利。而将该逻辑改为趋势择时,实乃笔者一位朋友,偶然之间的发现。在此,笔者也深深感谢这位朋友的无私奉献和耐心给予笔者本人的讲解。
上面谈到了,该逻辑是起于套利,根据两个具有协整性标的资产进行的线性回归刻画,依据残差进行规则性处理后的择时判断,加入传统CTA的波动率止盈止损。
残差

图1 计算残差代码
如上图所示,我们要计算出残差,就要计算出两个品种收盘价格时间序列的斜率和截距,斜率也就是贝塔值。依据中学所学y=ax+b,当我们求得贝塔值→a,随即也就求得b→截距,那么我们首先要求得就是斜率。
斜率

图2 计算斜率公式
上图是计算贝塔值也就是斜率的公式,我们首先要计算出两个标的资产的协方差和某个标的资产的方差,我们举例说明,假设X是铁矿石,Y是螺纹钢,也就是我们需要求出铁矿石和螺纹钢的协方差和铁矿石的方差。
求出协方差同样要按照下面的公式分成两步,第一步求出length周期的平均值,类似均线。第二步求出铁矿石和螺纹钢的变量值与平均值的差值的乘积,后再求期望值(平均)。如下图所示,方差亦然。
方差

图3 计算协方差和方差公式
应用
在我们求得协方差和方差后,根据公式我们即可求得斜率也就是贝塔值。带入到图1中,我们即可求得残差。如下图所示:
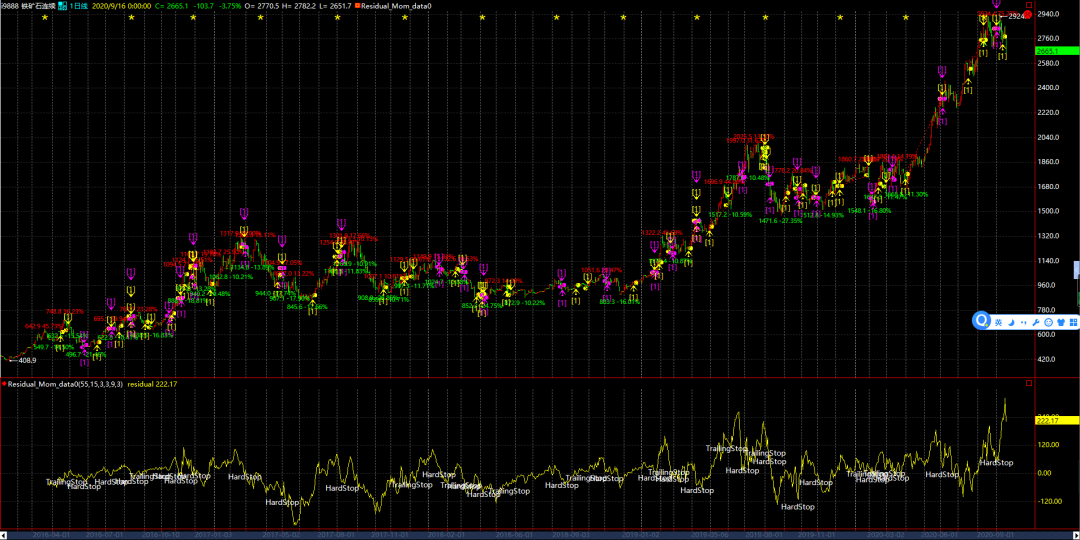
上图子图黄色的线既是残差曲线,本文采用时间周期为2016.1.1-至今。从统计套利了角度来看,一般理论上我们是在黄色线的上下极值区间进行相对应的残差回归操作,但是在残差动量策略里面,我们是要跟随残差的趋势进行开平仓择时信号的处理。
那么我们还要对该时间序列数据进行规则型的刻画处理,在这里笔者只是采用教学式思想,加入一个海龟通道,如下图所示:


止盈止损我们采用的是波动率刻画的方法进行止盈止损,如下图所示:

代码如下:

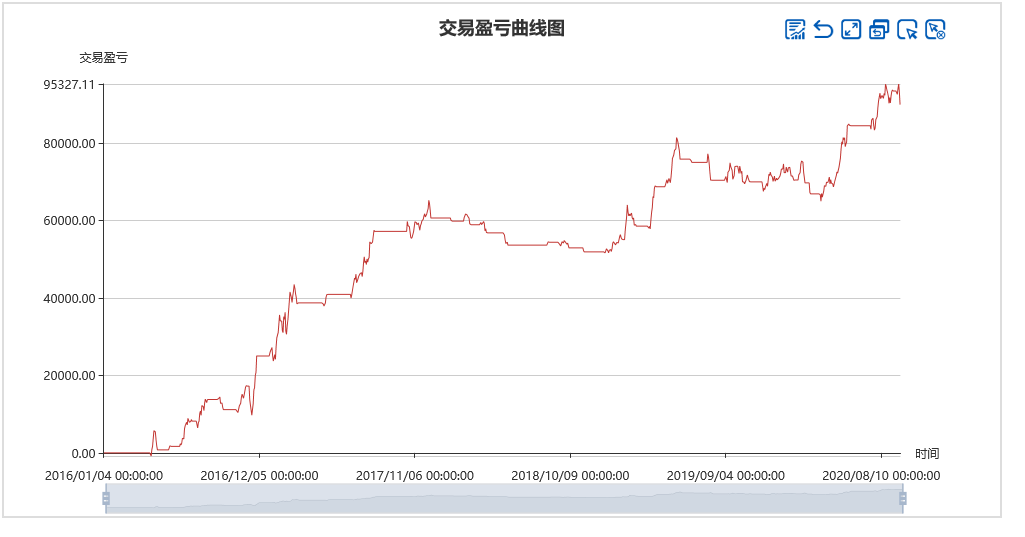
至此,整个策略的进出场我们已经构建完成了,除了策略自身改进迭代以外,本策略采用的日线周期,缺点是交易次数少,也就是频率较低,作为策略的补充所用。最后放上一张样本内外参数优化过的绩效回测图:
结语
本篇是量化研究模块的第二课题——残差动量的第一篇,后续笔者将采用更加“广义”的思路进行策略的迭代和深入的量化研究。本篇内容不仅仅局限于螺纹和铁矿石,可以延展到任何产业链的品种,例如:RB-J,MA-PP,MA-EG,AL-CU,JM-ZC,油脂类等等产业链品种当中。在这里我就不进行重复量的工作,感兴趣的大家可以自行探索和研究。当然也可以加入我们的VIP客户群,找小松鼠客服即可。
最后非常感谢我的朋友濮元恺提供的思路,为我后续的策略开发提供了广阔的思想。
本策略仅作学习交流使用,实盘交易盈亏投资者个人负责。
这篇关于量化研究 | 残差动量策略刻画与构建(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




