本文主要是介绍(转)Apollo 2.0 框架及源码分析(三) | 感知模块 | Radar Fusion,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
https://zhuanlan.zhihu.com/p/33852112
文章提到了几个点:
一、雷达radar部分:
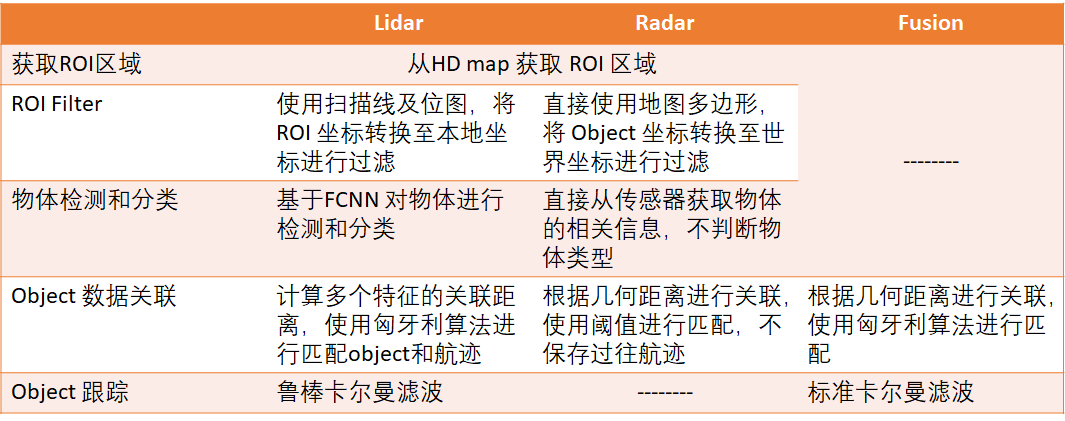
Apollo 2.0 的坐标体系是以 Lidar 为基准的。Apollo 可能认为 Velodyne 的位置是最准确的,因此 Camera 的位置标定参考 Velodyne, Radar 的标定参考 Camera。
阿波罗的感知几乎都依赖高精地图预先做ROI处理,以减少传感器数据处理的计算量浪费。
radar部分的代码,用到了一些方法来判断radar返回的对象是不是背景杂波。
Apollo 推荐使用的毫米波为Continental 的 ARS 408-21。ARS 408-21的介绍文档里也有简单提到,它可以对障碍物进行分类。但可靠性未知。该radar能追踪120个objects:大陆的Radar能够detect到超过120个object(没有进行过fusion的只有一点的cluster single point cluster)。 这种量产的Radar一般自带简单的detection和tracking算法。所以raw_object会有id,一般自带的算法会有 id, heading, velocity,object size, distance这些信息。在实际的测试过程中,该ID号是不能够作为跟踪关联的依据的,因为ID号在障碍物交叉的时候会出错。因此还应该再做一次关联!
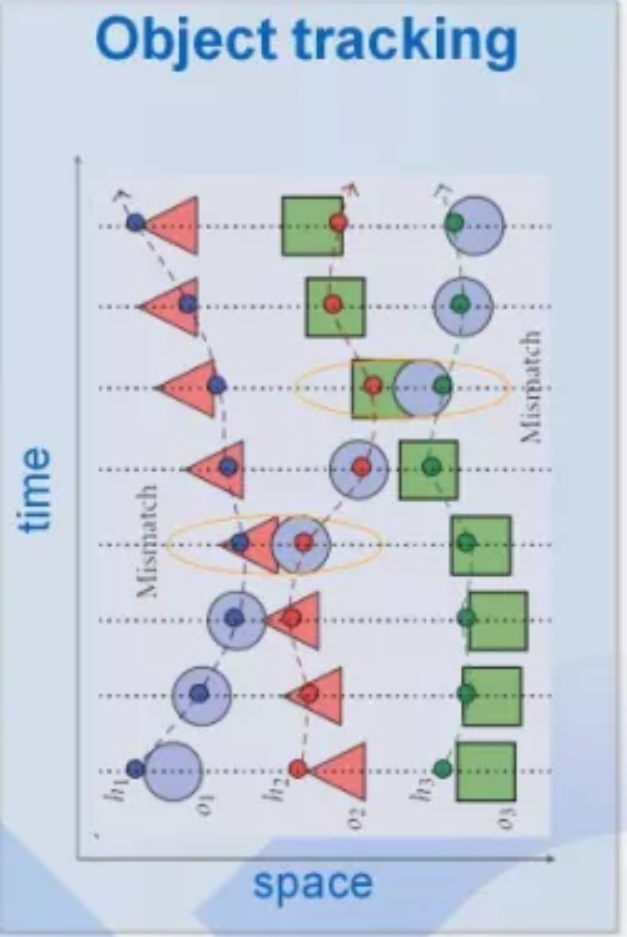
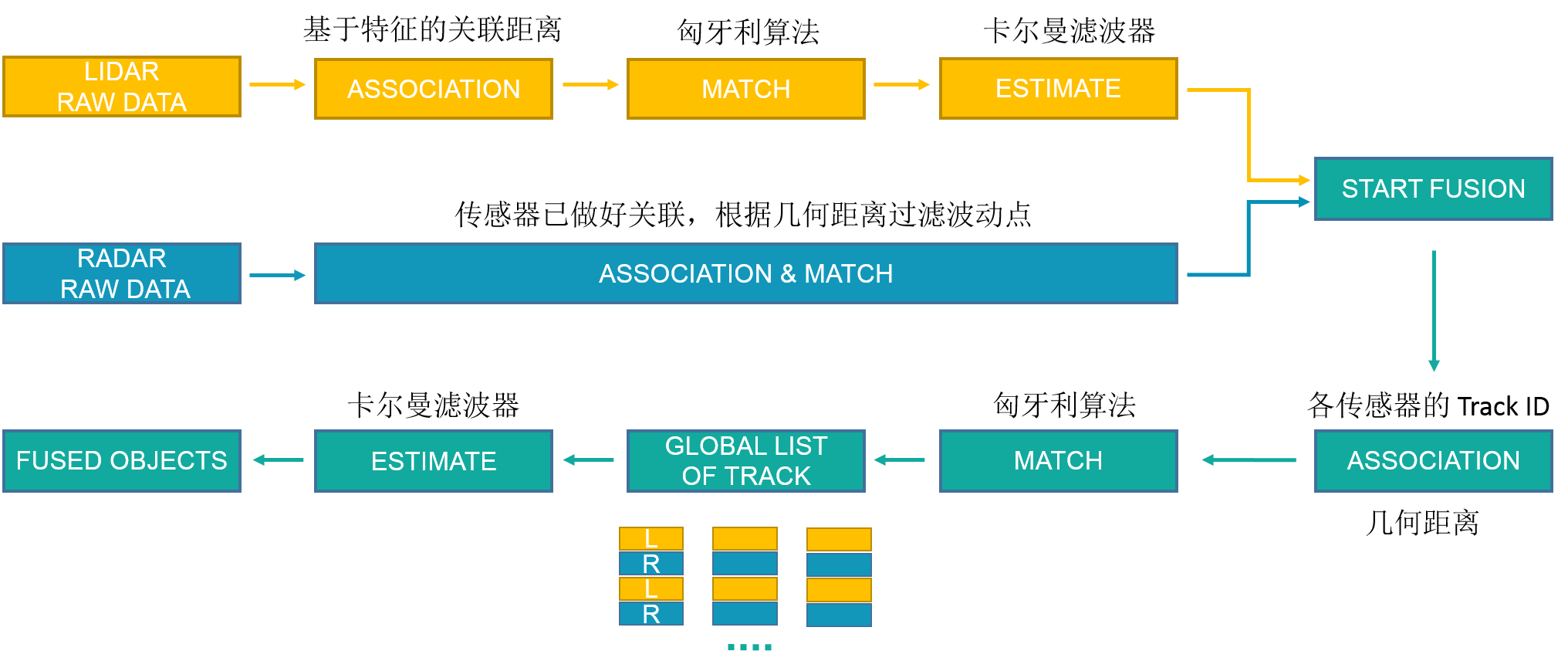
二、融合部分(radar 和 lidar):
object-level 的数据融合,该部分的输入为各传感器处理后的得到的object。
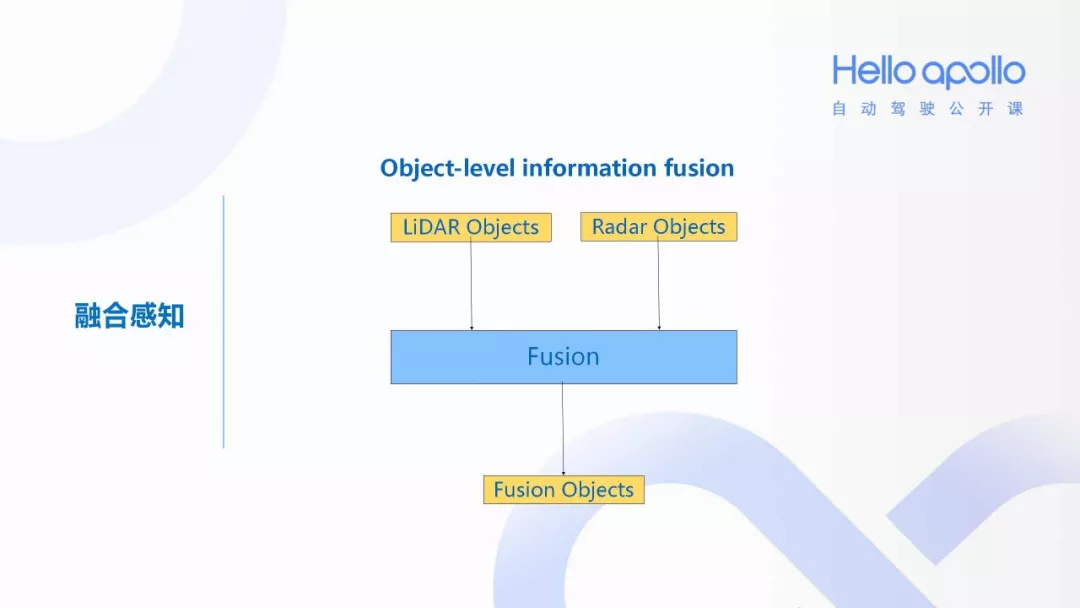
多源信息的数据融合中,根据数据抽象层次,融合可分为三个级别:
- 数据级融合 传感器裸数据融合,精度高、实时性差,要求传感器是同类的
- 特征级融合 融合传感器抽象的特征向量(速度,方向等),数据量小、损失部分信息
- 决策级融合 传感器自身先做出决策,融合决策结果,精度低、通信量小、抗干扰强
Apollo 应该是在特征层面对 objects 进行了融合。每当节点收到新的一帧数据的时候,融合部分就被调用。融合部分的输入为 SensorObjects, 输出为融合后的 object, 其大体的流程如下图所示。

传感器的数据融合有两部分内容比较重要,即 数据关联 和 动态预估。
数据关联用的是基于几何距离的HM匈牙利算法。
动态预估用的是:使用了非简化的估计误差协方差矩阵 更新公式:
- 标准卡尔曼滤波:
- Apollo:
结合 Wikipedia 上关于卡尔曼滤波的介绍,我先总结下该问题的背景:
- Apollo 使用的估计误差协方差矩阵
的更新公式是所谓的 Joseph form,而标准卡尔曼滤波通常使用的是简化版的更新公式
- 简化版的更新公式计算量小,实践中应用广,但只在 卡尔曼增益为最优 时有效
- 必须使用 Joseph form 的两种情况:
- 使用了非最优卡尔曼增益
- 算法精度过低,造成了数值稳定性相关的问题
阿波罗平台的计算力强大,因此为了算法精度,选择了非简化的P
三、总结:
这篇关于(转)Apollo 2.0 框架及源码分析(三) | 感知模块 | Radar Fusion的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






