本文主要是介绍mysql join 400秒_三张关联表,大表;单次查询耗时400s,有group by order by 如何优化...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
问题SQL:
select
p.person_id as personId,
p.person_name as personName,
p.native_place as nativePlace,
ci.company_name as companyName,
pp.seal_number as sealNumber,
GROUP_CONCAT(pp.major) as major,
pp.register_name as registerName
from qyt_person p
left join qyt_person_practising pp on p.person_id=pp.person_id
left join qyt_company_info ci on p.company_id=ci.company_id
group by p.person_id,pp.register_name
order by p.create_time desc
limit 1,10
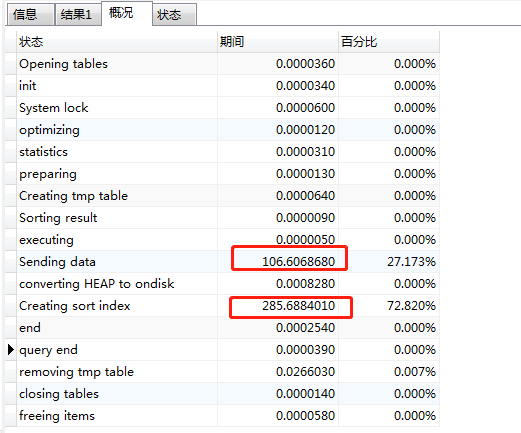
SQL总耗时393秒,通过Explain分析,发现为200万数据的表建立了临时表,且做了一次排序操作

通过查看SQL运行分析,也看出来,构造临时表耗时106秒,排序用了285秒(没索引的排序慢)
解决思路:根据业务需求再次审视如何减少数据量
1、业务需求:最新人员可以先取出来10名
2、取出来后再关联查询他们所在企业,所获证书(有索引,查询快)
3、这种小的临时表排序的耗时就可以接受了
4、SQL语句有子查询功能,可以把200万的表数据缩减为10人的小表
SQL语句如下:
select
p.person_id as personId,
p.person_name as personName,
p.native_place as nativePlace,
p.create_time as createTime,
ci.company_name as companyName,
pp.seal_number as sealNumber,
GROUP_CONCAT(pp.major) as major,
pp.register_name as registerName
from (SELECT person_id, person_name, native_place,company_id ,create_time from qyt_person order by create_time desc limit 0,10) p
left join qyt_person_practising pp on p.person_id=pp.person_id
left join qyt_company_info ci on p.company_id=ci.company_id
group by p.person_id,pp.register_name
ORDER BY p.create_time desc
limit 0,10
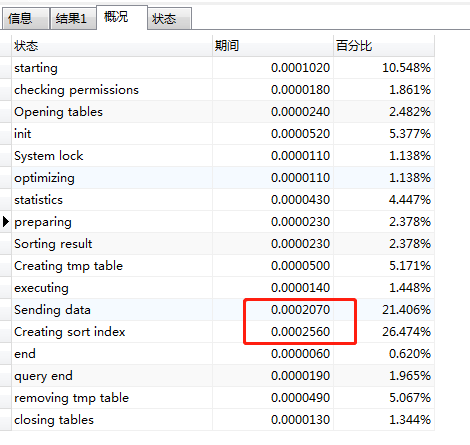
结果完美!响应时间为0.017秒
通过Explain分析,临时表就10条记录,所以处理耗时非常少

大块的时间还是损耗在构造临时表和排序上,但是这个时间必须得损失
这篇关于mysql join 400秒_三张关联表,大表;单次查询耗时400s,有group by order by 如何优化...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






