本文主要是介绍1.冷热分离:表数据量大读写缓慢如何优化?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
冷热分离:表数据量大读写缓慢如何优化?
业务场景
我曾经做过供应链相关的架构优化,当时我们平台有一个订单功能,里面的主表有几千万的数据量,加上关联表,数据量达到上亿。
这么庞大的数据量,让平台的查询订单变得格外迟缓,查询一次都要二三十秒,而且多点击几次就会出现宕机。比如业务员多次查询时,数据库的 CPU 会立马狂飙,服务器线程也降不下来。
当时,我们尝试了优化表结构、业务代码、索引、SQL 语句等办法来提高响应速度,但这些方法治标不治本,查询速度还是很慢。
考虑到我们手头上还有其他优先级高的需求需要处理,为此,我们跟业务方反馈:“这功能以后你们能不用就不用,暂时先忍受一下。”可经过一段时间后,业务方实在受不了了,直接跟我们放狠话,无奈之下我们屈服了。
最终,我们决定采用一个性价比高的解决方案,简单方便地解决了这个问题。在处理数据时,我们将数据库分成了冷库和热库 2 个库,不常用数据放冷库,常用数据放热库。
通过这样的方法处理后,因为业务员查询的基本是近期常用的数据,常用的数据量大大减少了,就再也不会出现宕机的情况了,也大大提升了数据库响应速度。
其实上面这个方法,就是“冷热分离”。
比如账单、文章等
什么是冷热分离?
冷热分离就是在处理数据时将数据库分成冷库和热库 2 个库,冷库指存放那些走到了终态的数据的数据库,热库指存放还需要修改的数据的数据库。
什么情况下使用冷热分离?
假设你的业务需求出现了如下情况,就可以考虑使用冷热分离的解决方案:
数据走到终态后,只有读没有写的需求,比如订单完结状态;
用户能接受新旧数据分开查询,比如有些电商网站默认只让查询 3 个月内的订单,如果你要查询 3 个月前的订单,还需要访问另外的单独页面。
冷热分离实现思路
在实际操作过程中,冷热分离整体实现思路如下:
(一)如何判断一个数据到底是冷数据还是热数据?
(二)如何触发冷热数据分离?
(三)如何实现冷热数据分离?
(四)如何使用冷热数据?
(一)如何判断一个数据到底是冷数据还是热数据?
一般而言,在判断一个数据到底是冷数据还是热数据时,我们主要采用主表里的 1 个或多个字段组合的方式作为区分标识。其中,这个字段可以是时间维度,比如“下单时间”这个字段,我们可以把 3 个月前的订单数据当作冷数据,3 个月内的当作热数据。
当然,这个字段也可以是状态维度,比如根据“订单状态”字段来区分,已完结的订单当作冷数据,未完结的订单当作热数据。
我们还可以采用组合字段的方式来区分,比如我们把下单时间 > 3 个月且状态为“已完结”的订单标识为冷数据,其他的当作热数据。
而在实际工作中,最终究竟使用哪种字段来判断,还是需要根据你的实际业务来定。
关于判断冷热数据的逻辑,这里还有 2 个注意要点必须说明:
如果一个数据被标识为冷数据,业务代码不会再对它进行写操作;
不会同时存在读冷/热数据的需求。
(二)如何触发冷热数据分离?
了解了冷热数据的判断逻辑后,我们就要开始考虑如何触发冷热数据分离了。一般来说,冷热数据分离的触发逻辑分 3 种。
1.直接修改业务代码,每次修改数据时触发冷热分离(比如每次更新了订单的状态,就去触发这个逻辑),如下图所示:
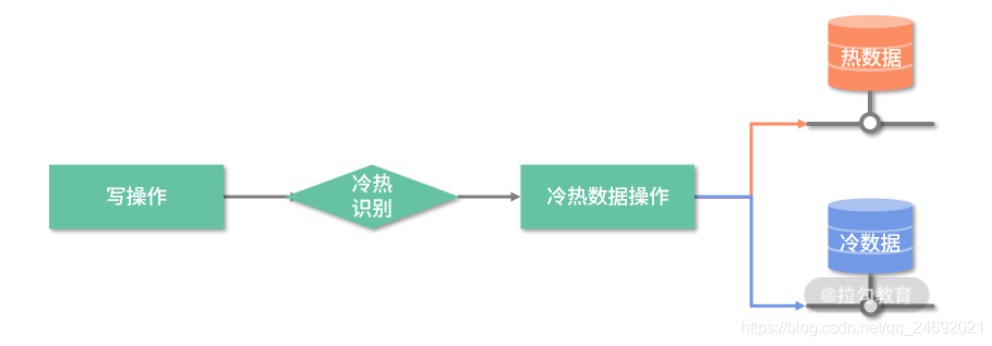
触发逻辑一:直接修改业务代码
2.如果不想修改原来的业务代码,可通过监听数据库变更日志 binlog 的方式来触发,如下图所示:
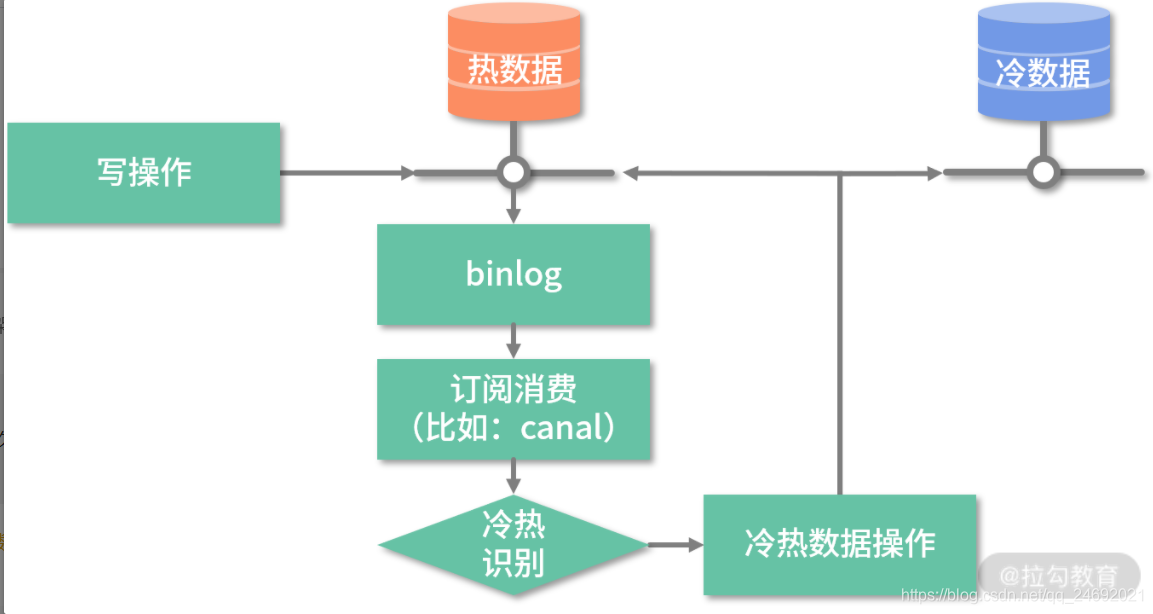
3.通过定时扫描数据库的方式来触发,如下图所示:
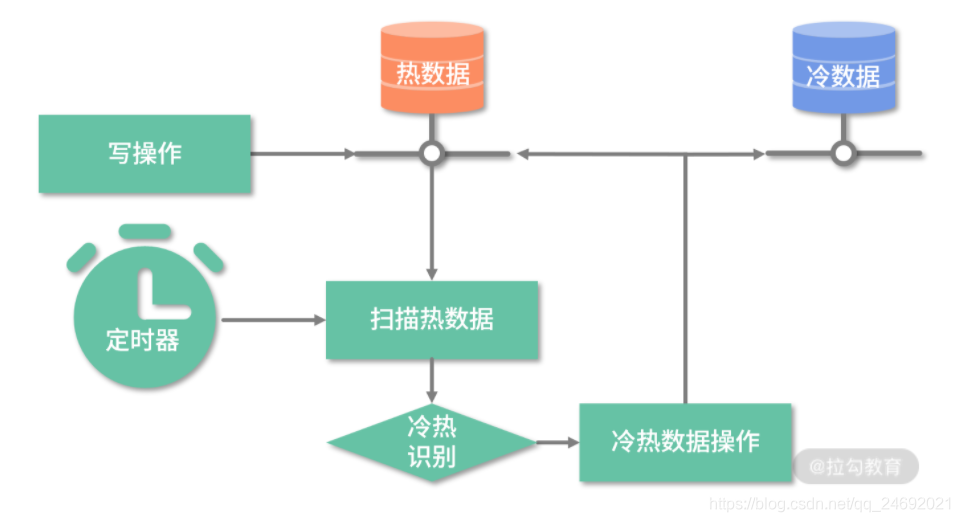
针对以上 3 种触发逻辑,我们到底选哪种比较好呢?待我分析完各自优缺点后,你心里就会有答案了。
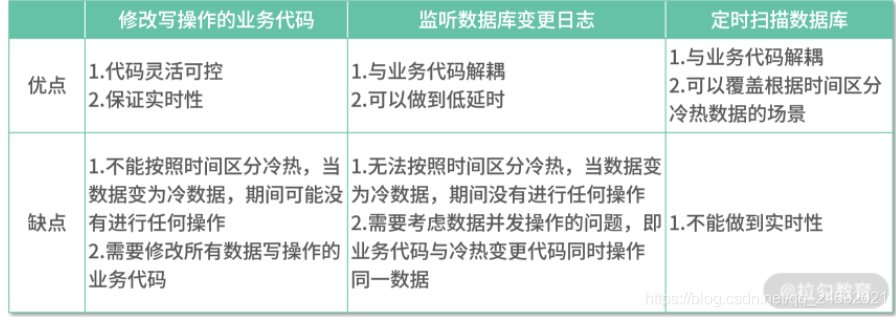
根据以上表格内容对比,我们可以得出每种触发逻辑的建议场景。
修改写操作的业务代码:建议在业务代码比较简单,并且不按照时间区分冷热数据时使用。
监听数据库变更日志:建议在业务代码比较复杂,不敢随意变更,并且不按照时间区分冷热数据时使用。
定时扫描数据库:建议在按照时间区分冷热数据时使用。
我做架构那会儿就是按照时间区分冷热数据,所以选用了定时扫描数据库的触发方式。因此,到底选择哪种触发方式,还是需要根据你的具体业务需求决定。
(三)如何分离冷热数据?
在讲解如何分离冷热数据之前,我们先来了解下分离冷热数据的基本逻辑,只有掌握了基本原理,才能真正理解事物本质。
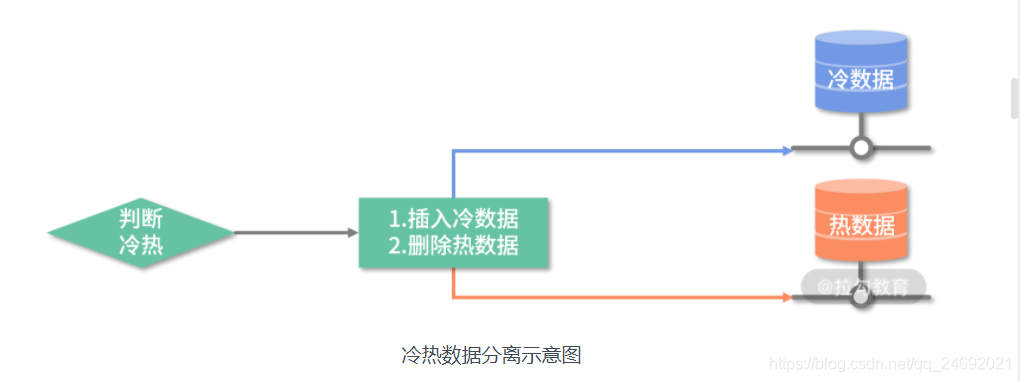
分离冷热数据的基本逻辑如下:
判断数据是冷是热;
将要分离的数据插入冷数据库中;
再从热数据库中删除分离的数据。
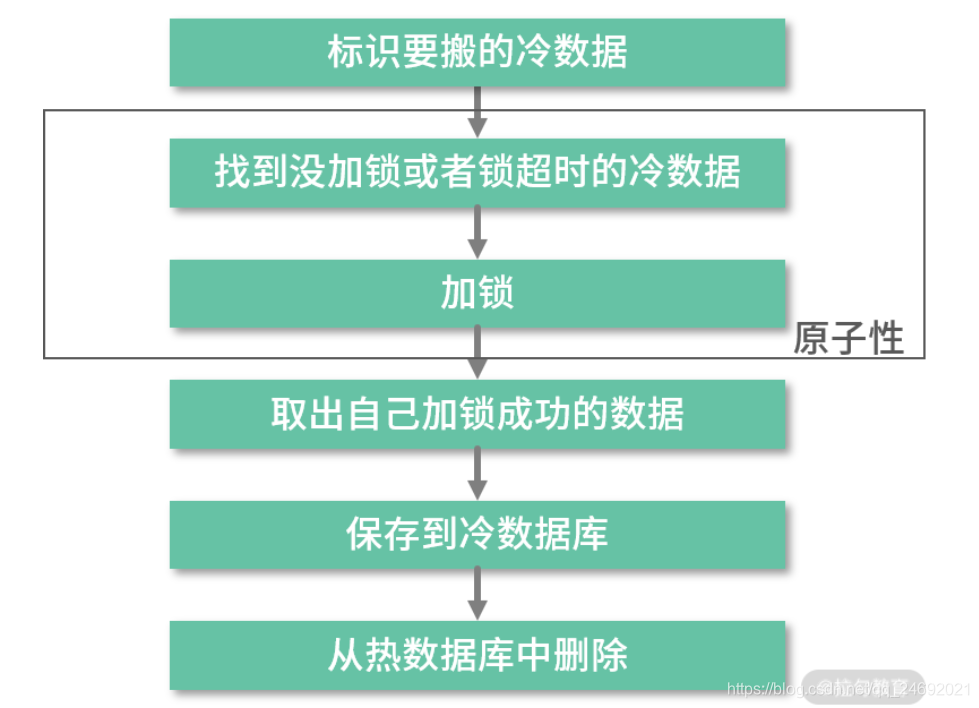
(1)一致性:同时修改多个数据库,如何保证数据的一致性?
这里提到的一致性要求,指我们如何保证任何一步出错后数据还是一致的,解决方案为只要保证每一步都可以重试且操作都有幂等性就行,具体逻辑分为四步。
- 在热数据库中,给要搬的数据加个标识: ColdFlag=WaittingForMove。(实际处理中标识字段的值用数字就可以,这里是为了方便理解。)
- 找出所有待搬的数据(ColdFlag=WaittingForMove):这步是为了确保前面有些线程因为部分原因失败,出现有些待搬的数据没有搬的情况。
- 在冷数据库中保存一份数据,但在保存逻辑中需加个判断以此保证幂等性(这里需要用事务包围起来),通俗点说就是假如我们保存的数据在冷数据库已经存在了,也要确保这个逻辑可以继续进行。
- 从热数据库中删除对应的数据。
(2)数据量:假设数据量大,一次性处理不完,该怎么办?是否需要使用批量处理?
前面讲了 3 种冷热分离的触发逻辑,前 2 种基本不会出现数据量大的问题,因为每次只需要操作那一瞬间变更的数据,但如果采用定时扫描的逻辑就需要考虑数据量这个问题了。
这个实现逻辑也很简单,在搬数据的地方我们加个批量逻辑就可以了。为方便理解,我们来看一个示例。
假设我们每次可以搬 50 条数据:
a. 在热数据库中给要搬的数据加个标识:ColdFlag=WaittingForMove;
b. 找出前 50 条待搬的数据(ColdFlag=WaittingForMove);
c. 在冷数据库中保存一份数据;
d. 从热数据库中删除对应的数据;
e. 循环执行 b。
(3)并发性:假设数据量大到要分到多个地方并行处理,该怎么办?
在定时搬运冷热数据的场景里(比如每天),假设每天处理的数据量大到连单线程批量处理都来不及,我们该怎么办?这时我们就可以开多个线程并发处理了。(虽然大部分情况下多线程较快,但我曾碰到过这种情况:当单线程 batch size 到一定数值时效率特别高,比多线程任何 batch size 都快。所以,希望同学们到时多留意下,如果遇到多线程速度不快,我们就考虑控制单线程。)
当多线程同时搬运冷热数据,我们需要考虑如下实现逻辑。
第 1 步:如何启动多线程?
因为我们采用的是定时器触发逻辑,这种触发逻辑性价比最高的方式是设置多个定时器,并让每个定时器之间的间隔短一些,然后每次定时启动一个线程就开始搬运数据。
还有一个比较合适的方式是自建一个线程池,然后定时触发后面的操作:先计算待搬动的热数据的数量,再计算要同时启动的线程数,如果大于线程池的数量就取线程池的线程数,假设这个数量为 N,最后循环 N 次启动线程池的线程搬运冷热数据。
第 2 步:某线程宣布某个数据正在操作,其他线程不要动(锁)。
关于这个逻辑,我们需要考虑 3 个特性。
- 获取锁的原子性: 当一个线程发现某个待处理的数据没有加锁,然后给它加锁,这 2 步操作必须是原子性的,即要么一起成功,要么一起失败。实际操作为先在表中加上 LockThread 和 LockTime 两个字段,然后通过一条 SQL 语句找出待迁移的未加锁或锁超时的数据,再更新 LockThread=当前线程,LockTime=当前时间,最后利用 MySQL 的更新锁机制实现原子性。
- 获取锁必须与开始处理保证一致性: 当前线程开始处理这条数据时,需要再次检查下操作的数据是否由当前线程锁定成功,实际操作为再次查询一下 LockThread= 当前线程的数据,再处理查询出来的数据。
- 释放锁必须与处理完成保证一致性: 当前线程处理完数据后,必须保证锁释放出去。
第 3 步:某线程正常处理完后,数据不在热库,直接跑到了冷库,这是正常的逻辑,倒没有什么特别需要注意的点。
第 4 步:某线程失败退出了,结果锁没释放怎么办(锁超时)?
锁无法释放: 如果锁定这个数据的线程异常退出了且来不及释放锁,导致其他线程无法处理这个数据,此时该怎么办?解决方案为给锁设置一个超时时间,如果锁超时了还未释放,其他线程可正常处理该数据。
设置超时时间时,我们还应考虑如果正在处理的线程并未退出,因还在处理数据导致了超时,此时又该怎么办?解决方案为尽量给超时的时间设置成超过处理数据的合理时间,且处理冷热数据的代码里必须保证是幂等性的。
最后,我们还得考虑一个极端情况:如果当前线程还在处理数据,此时正在处理的数据的锁超时了,另外一个线程把正在处理的数据又进行了加锁,此时该怎么办?我们只需要在每一步加判断容错即可,因为搬运冷热数据的代码比较简单,通过这样的操作当前线程的处理就不会破坏数据的一致性。
考虑到前面逻辑比较复杂,这里我们特地画了一个分离的流程图,如下图所示:
学到这,冷热分离的 4 个问题,我们已经解决了 3 个,解决最后 1 个问题——如何使用冷热数据,我们就算大功告成了。
(四)如何使用冷热数据?
在功能设计的查询界面上,一般都会有一个选项供我们选择需要查询冷数据还是热数据,如果界面上没有提供,我们可以直接在业务代码里区分。(说明:在判断是冷数据还是热数据时,我们必须确保用户不允许有同时读冷热数据的需求。)

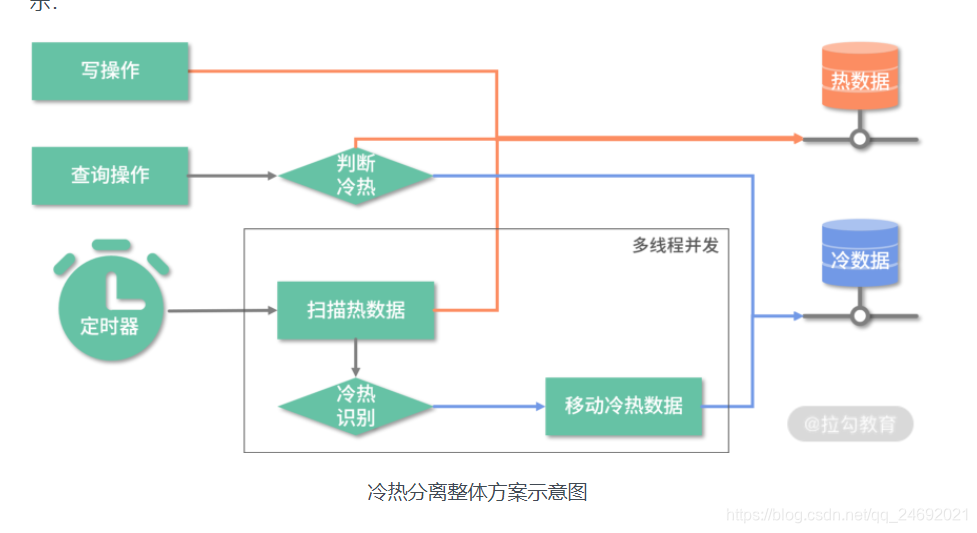
整体方案
课程讲到这,我们再把 01 讲整个知识点串起来下,串完后就形成了一个整体解决方案,如下图所示:
一步一步学到这,思路是不是感觉瞬间清晰了很多?
历史数据如何迁移?
一般而言,只要跟持久化层有关的架构方案,我们都需要考虑历史数据的迁移问题,即如何让旧架构的历史数据适用于新的架构?
因为前面的分离逻辑在考虑失败重试的场景时,刚好覆盖了这个问题,所以这个问题的解决方案也很简单,我们只需要给所有的历史数据加上标识:ColdFlag=WaittingForMove 后,程序就会自动迁移了。
冷热分离解决方案的不足
不得不说,冷热分离解决方案确实能解决写操作慢和热数据慢的问题,但仍然存在诸多不足。
不足一: 用户查询冷数据速度依旧很慢,如果查询冷数据的用户比例很低,比如只有 1%,那么这个方案就没问题。
不足二: 业务无法再修改冷数据,因为冷数据多到一定程度时,系统承受不住。
这篇关于1.冷热分离:表数据量大读写缓慢如何优化?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




