本文主要是介绍mysql并行复制_浅析MySQL并行复制,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
01 并行复制的概念
在MySQL的主从复制架构中,主库上经常会并发的执行很多SQL,只要这些SQL没有产生锁等待,那么同一时间并发好几个SQL线程是没有问题的。
我们知道,MySQL的从库是要通过IO_thread去拉取主库上的binlog的,然后存入本地,落盘成relay-log,通过sql_thread来应用这些relay-log。
在MySQL5.6之前的版本中,当主库上有多个线程并发执行SQL时,sql_thread只有一个,在某些TPS比较高的场景下,会出现主库严重延迟的问题。MySQL为了解决这个问题,将sql_thread演化了多个worker的形式,在slave端并行应用relay log中的事务,从而提高relay log的应用速度,减少复制延迟。这就是并行复制的由来。

在MySQL中,复制线程是由参数slave_parallel_workers来控制的,通常情况下,在8G内存、8核CPU的机器上,将该值设置为8比较合适,如果你的CPU核数比较高,那么可以适当调整为8~16之间的数字。
mysql> show variables like 'slave_parallel_workers';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| slave_parallel_workers | 8 |
+------------------------+-------+
1 row in set, 1 warning (0.00 sec)
02 并行复制的演进
并行复制的本质是同时执行的SQL不存在锁争用。
在MySQL5.6版本,MySQL支持的粒度是按照数据库进行并行执行relay log,这种方式能够解决一部分问题,因为不同数据库上的SQL,肯定不会修改表中的同一行内容。这样也就不会产生锁争用。在一些数据库均匀分布,每个数据库使用频率都差不多的场景下,这种并行复制的方法比较好。如果你的业务的数据都集中在一个热点表,这种情况下,并行复制会退化为单线程复制。
随后,在MariaDB中对并行复制做了一定的改进,它的做法是:
1、主库上能够并行提交的事务,也就是已经进入到了redo log commit阶段的事务,在从库上也一定能够并行提交,所以在主库上并行提交的事务,它用一个commit_id对这组事务来进行标识,下一组并行事务的commit_id为本组的commit_id+1
2、将所有的事务的commit_id写入binlog中
3、在从库上应用binlog的时候,将所有的binlog按照commit_id进行划分到不同的worker上
4、本组commit_id的事务全部在从库上提交完成之后,再去拿下一批事务。
这种方法大大增加了从库应用relay log的速度,但是问题是从库在应用前一组事务的时候,后一组事务是处于等待中的,即使前一组的worker有些已经空闲。而在主库上,可能无时无刻不在写入,这样,系统的吞吐量上主从节点就不匹配,主库的吞吐量严重高于从库。
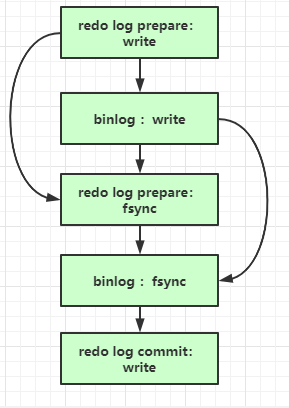
MySQL5.7的并行复制在MariaDB的基础上做了改进,我们知道,事务进入到redo log prepare阶段的时候,由于WAL技术,说明此时事务已经经过了所冲突检测阶段了。MySQL5.7的并行复制时将所有在主库上处于redo log prepare阶段的事务,和该阶段之后的事务,也就是处于redo log commit阶段的事务,在从库并行执行,从而减少worker线程不必要的等待。
这里,有必要再说两个参数,
binnlog_group_commit_sync_delay参数,表示redo log prepare阶段完成之后,延迟多少微秒后才调用fsync;
binlog_group_commit_sync_no_delay_count参数,表示累积多少次redo log prepare:write的操作以后才调用fsync
这两个参数是用于故意拉长binlog从write到fsync的时间,以此减少binlog的写盘次数。在MySQL 5.7的并行复制策略里,它们可以用来制造更多的“同时处于prepare阶段的事务”。这样就增加了备库复制的并行度。
它们既可以“故意”让主库提交得慢些,又可以让备库执行得快些。在MySQL 5.7处理备库延迟的时候,可以考虑调整这两个参数值,来达到提升备库复制并发度的目的。
以上就是浅析MySQL并行复制的详细内容,更多关于MySQL并行复制的资料请关注脚本之家其它相关文章!
这篇关于mysql并行复制_浅析MySQL并行复制的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




