本文主要是介绍【数学建模】【Python】自来水管道铺设问题(第一问),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
代办事项:
状态:未处理
记录时间:2022/6/29/19:43
问题的发现:复习离散图论章节引发的联想和思考及反省
情况说明:在prim.py文件中的距离选取可能存在一定的问题。当下认为,该程序在每次增加“边”的时候,只是进行了已选取点所能延申的最短边,并不一定是总长的最短距离。该问题在初步处理本题目中已经注意,但后续并没有在程序中体现。应该是脱离了prim算法。
对于当前结果的态度:可以在一定程度上可以采用,但应该不是最优。
更改时间暂定为2022年7、8月。
自来水管道铺设问题
原问题
在村村通自来水工程实施过程中,从保证供水质量以及设备维护方便角度出发,某地区需要建设一个中心供水站,12个一级供水站和168个二级供水站,各级供水站的位置坐标如附件表1所示,其中类型A表示中心供水站,类型V代表一级供水站,类型P为二级供水站。附件图1是各级供水站的地理位置图。
现在要将中心供水站A处的自来水通过管道输送到一级供水站和二级供水站。按照设计要求,从中心站A铺设到一级供水站的管道为I型管道,从一级供水站出发铺设到二级供水站的管道为II型管道。
自来水管道铺设技术要求如下:
- 中心供水站只能和一级供水站连接(铺设I型管道),不能和二级供水站直接相连,但一级供水站之间可以连接(铺设I型管道)。
- 一级供水站可以与二级供水站相连(铺设II型管道),且二级供水站之间也可以连接(铺设II型管道)。
- 各级供水站之间的连接管道必须从上一级供水站或同一级供水站的位置坐标出发,不能从任意管道中间的一点进行连接。
- 相邻两个供水站之间(如果有管道相连)所需管道长度可简化为欧氏距离。
请您结合上述管道铺设要求,建立数学模型,完成以下问题
问题1:从中心供水站A出发,自来水管道应该如何铺设才能使管道的总里程最少?以图形给出铺设方案,并给出I型管道和II型管道总里程数。
问题2:由于II型管道市场供应不足,急需减少从一级供水站出发铺设的II型管道总里程,初步方案是将其中两个二级供水站升级为一级供水站。问选取哪两个二级供水站,自来水管道应该如何铺设才能使铺设的II型管道总里程最少?相对问题1的方案,II型管道的总里程减少了多少公里?
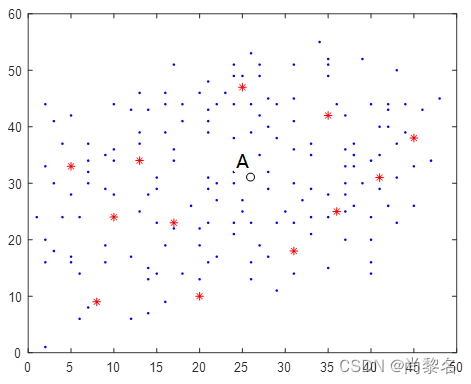
原始数据
# 准备原始数据
# initialData.py
coordinate_A = [26, 31]
coordinate_A_V = [[26, 31], [5, 33], [8, 9], [10, 24], [13, 34], [17, 23], [20, 10], [25, 47], [31, 18], [35, 42], [36, 25],[41, 31], [45, 38]]
coordinate_A_V_P = [[26, 31], [5, 33], [8, 9], [10, 24], [13, 34], [17, 23], [20, 10], [25, 47], [31, 18], [35, 42],[36, 25], [41, 31], [45, 38], [41, 35], [40, 34], [38, 35], [38, 37], [33, 37], [31, 36], [33, 35],[28, 32], [24, 30], [21, 31], [22, 27], [28, 29], [43, 37], [44, 39], [25, 27], [21, 29], [22, 30],[24, 32], [37, 33], [38, 33], [37, 36], [14, 13], [16, 9], [14, 7], [18, 14], [12, 6], [15, 14],[20, 13], [13, 46], [16, 39], [21, 39], [26, 44], [28, 40], [27, 42], [29, 38], [29, 44], [36, 44],[41, 40], [39, 52], [27, 49], [23, 46], [20, 46], [16, 46], [22, 44], [40, 44], [42, 40], [37, 42],[35, 49], [35, 51], [35, 52], [34, 55], [26, 53], [27, 51], [31, 51], [31, 45], [31, 41], [28, 45],[27, 35], [24, 38], [26, 39], [13, 37], [17, 36], [21, 41], [18, 41], [21, 43], [13, 39], [14, 43],[12, 43], [10, 44], [16, 44], [18, 44], [24, 44], [25, 49], [24, 49], [24, 51], [21, 48], [17, 51],[10, 34], [9, 35], [7, 37], [4, 37], [5, 42], [2, 44], [7, 32], [7, 30], [1, 24], [2, 16], [3, 18],[2, 20], [4, 24], [5, 28], [6, 24], [9, 29], [2, 33], [7, 34], [3, 30], [3, 41], [10, 36], [17, 34],[20, 22], [24, 21], [22, 17], [21, 16], [27, 19], [26, 16], [9, 16], [12, 17], [14, 15], [19, 26],[14, 28], [13, 25], [9, 19], [2, 1], [6, 6], [7, 8], [6, 14], [5, 17], [5, 16], [16, 19], [26, 13],[29, 11], [31, 14], [28, 17], [20, 19], [17, 22], [15, 23], [21, 23], [24, 23], [26, 23], [25, 25],[15, 31], [15, 29], [10, 28], [38, 26], [37, 25], [33, 21], [40, 24], [44, 44], [41, 30], [33, 24],[32, 27], [40, 14], [42, 26], [45, 33], [29, 23], [31, 30], [30, 25], [31, 23], [35, 15], [40, 16],[40, 20], [37, 20], [35, 24], [43, 23], [45, 26], [37, 28], [35, 28], [33, 29], [37, 30], [39, 30],[41, 29], [43, 31], [47, 34], [46, 43], [42, 43], [48, 45], [42, 44], [43, 50]]
问题一
从中心供水站A出发,自来水管道应该如何铺设才能使管道的总里程最少?以图形给出铺设方案,并给出I型管道和II型管道总里程数。
问题分析
依据要求,中心供水站只能和一级供水站连接(铺设I型管道),不能和二级供水站直接相连,但一级供水站之间可以连接(铺设I型管道)。故将问题1分成两部分进行研究,但两部分都遵循prim算法。第一部分,中心供水站与一级供水站做最小生成树;第二部分,由一级供水站出发,做一级供水站和二级供水站的最小生成树。
符号意义
| 符号 | 意义 |
|---|---|
| route_A_V | 中心供水站与一级供水站的连线 |
| route_A_V_P | 所有供水站的连线 |
| Already_sites | 已经连通的站点 |
| distance_sites | 站点之间的欧式距离(作为权重) |
| Bool | 用于管理权重数据的数组(对数据进行显现和屏蔽) |
代码实现
代码总共分为五个部分,全部通过python3实现。分别为pipeLaying.py文件、initialData.py文件、prim.py文件、distance.py文件、bool.py文件(在附录中都已给出)。
initialData.py文件用于准备原始数据。通过数组储存供水站的坐标。其中coordinate_A, coordinate_A_V, coordinate_A_V_P,分别用于存储中心供水站A、中心供水站A和一级供水站V、中心供水站A一级供水站V二级供水站P的坐标。
distance.py文件用于计算各个供水站之间的距离,作为后续选取路径的依据即权重。其中构造了Distance(coordinate_sites)函数,返回值为一个数组distance。
bool.py文件用于管理数据,目的在于当相关路径被选取后,将与其端点相关的不适宜的路径全部屏蔽,即对于通过Distance(coordinate_sites)函数计算得到的数据做显现或屏蔽。对于数据的正确管理,在本次代码实现中有关键性作用。
prim.py文件是prim算法的体现,问题的解决与结果的导出都依靠Prim(coordinate_sites)函数实现。在实现过程中,凭借Distance(coordinate_sites)函数提供的数据作为权重依据。同时,通过BoolSites(coordinate_sites)函数对于循环过程数据的管理避免循环的重复。
pipeLaying.py文件主要在于输出结果以及通过route_A_V,route_A_V_P,绘制管道连接图,并输出图像。
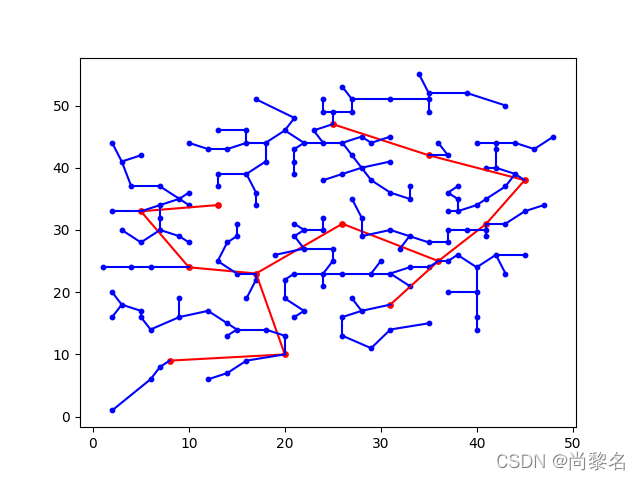
结果呈现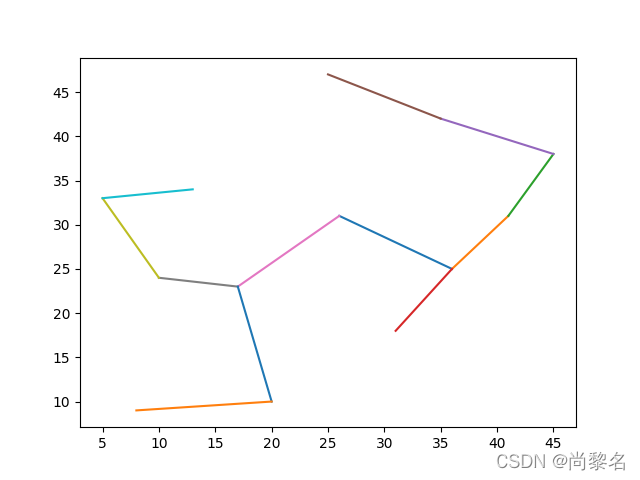
代码附录
# distance.pyimport numpy as np
import math as m# 计算站点之间距离,并返回一个数组
def Distance(coordinate_sites):number_sites = len(coordinate_sites)distance = np.zeros((number_sites,number_sites))for i in range(number_sites):for j in range(number_sites):distance_i_j = m.sqrt((coordinate_sites[i][0] - coordinate_sites[j][0])**2 + (coordinate_sites[i][1] - coordinate_sites[j][1])**2)if distance_i_j !=0:distance[i,j] = distance_i_jelse:distance_i_j = 1000 #粗略估计,算出的不同两点间的距离都小于1000(大数即可),将1000作为自身到自身的距离,return distance
#bool.pyimport numpy as npdef BoolSites(coordinate_sites):if len(coordinate_sites) == 13:bool_A_V = np.zeros((13, 13))return bool_A_Velif len(coordinate_sites) == 181:bool_A_V_P = np.zeros((181, 181))for i in range(13):for j in range(13):bool_A_V_P[i, j] = 1bool_A_V_P[0, :] = 1bool_A_V_P[:, 0] = 1return bool_A_V_P
# prim.pyimport numpy as np
from bool import BoolSites
from distance import Distance
from initialData import *def Prim(coordinate_sites):number = len(coordinate_sites)distance_sites = Distance(coordinate_sites)Bool = BoolSites(coordinate_sites) #用于屏蔽处理if number ==13:Already_sites = [0] #已经连上的站点,从中心供水站A开始计数0route_sites = [] # 选取的站点连接路线elif number == 181:Already_sites = Prim(coordinate_A_V)[1] #因为下面的while len(Already_sites) != number中的Already_sites是以之前的为基础route_sites = Prim(coordinate_A_V)[0]while len(Already_sites) != number:# 做屏蔽处理for i in Already_sites:for j in Already_sites:if Bool[i, j] == 0 and [i, j] not in route_sites and [j, i] not in route_sites:Bool[i, j] = 1Bool[j, i] = 1min_distance = 1000 # 用于判断选取最短距离,即局部最小权count = 0original_len = len(Already_sites)# 循环用于选择并增加新路径for i in Already_sites:# 在结束一次循环后,对于Already_sites的更改会反馈到‘for i in Already_sites'中,因为是列表。# 所以该判别语句用语循环的跳出。if original_len < len(Already_sites) and i == Already_sites[-1]:break# Bool[i,j]为0,表示可以建立新的连线;通过min_distance判断# 这里的min_distance会保留到下一个i的循环,继续对count=1时扩充的位置进行修正和确定for j in range(1, number):if min_distance >= distance_sites[i][j] and Bool[i, j] == 0:min_distance = distance_sites[i][j]count = count + 1# 相当于在route_sites和Already_sites中分别扩充一个位置if count == 1:route_sites.append([i, j])Bool[i, j] = 1Bool[j, i] = 1Already_sites.append(j)# 在本次的i下,对扩充的位置进行数据的修正和确定else:# print(count)Bool[route_sites[len(route_sites) - 1][0], route_sites[len(route_sites) - 1][1]] = 0Bool[route_sites[len(route_sites) - 1][1], route_sites[len(route_sites) - 1][0]] = 0route_sites[len(route_sites) - 1] = [i, j]Bool[route_sites[len(route_sites) - 1][0], route_sites[len(route_sites) - 1][1]] = 1Bool[route_sites[len(route_sites) - 1][1], route_sites[len(route_sites) - 1][0]] = 1Already_sites[len(Already_sites) - 1] = j# 以下两次屏蔽处理没有实际意义Bool[:, Already_sites[-1]] = 1Bool[Already_sites[-1], :] = 1return [route_sites, Already_sites] # 导出路径结果
# pipeLaying.pyfrom distance import Distance
import numpy as np
from prim import Prim
import matplotlib.pyplot as plt
from initialData import *route_A_V = Prim(coordinate_A_V)[0]
print(route_A_V)
# 绘制AV站点之间的最优路线图
for i in route_A_V:x = [coordinate_A_V[i[0]][0], coordinate_A_V[i[1]][0]]y = [coordinate_A_V[i[0]][1], coordinate_A_V[i[1]][1]]plt.plot(x, y)
plt.show()route_A_V_P = Prim(coordinate_A_V_P)[0]
print(route_A_V_P)
# 绘制AVP站点之间的最优路线图
x = []
y = []
for i in coordinate_A_V_P:x.append(i[0])y.append(i[1])
plt.scatter(x[:13], y[:13], 15, "red")
plt.scatter(x[13:], y[13:], 10, "blue")
count = 0
sum_pipeline_A_V = 0
sum_pipeline_A_V_P = 0
for i in route_A_V_P:count += 1x = [coordinate_A_V_P[i[0]][0], coordinate_A_V_P[i[1]][0]]y = [coordinate_A_V_P[i[0]][1], coordinate_A_V_P[i[1]][1]]if count <= 12:plt.plot(x, y, color='red')sum_pipeline_A_V += Distance(coordinate_A_V_P)[i[0], i[1]]else:plt.plot(x, y, color='blue')sum_pipeline_A_V_P += Distance(coordinate_A_V_P)[i[0], i[1]]
print("sum_pipeline_A_V={}, sum_pipeline_A_V_P={}, sum_pipeline_A_V_P - sum_pipeline_A_V={}".format(sum_pipeline_A_V, sum_pipeline_A_V_P, sum_pipeline_A_V_P - sum_pipeline_A_V))
plt.show()
注
将所有代码分文件复制后,调试好环境是可以正常运行的。通过最后一个文件得结果,最后一个文件运行时,有时长,等待后出来第一个图,把图叉掉,输出第一部分结果,等待,出来第二个图,叉掉出结果。(具体情况,实操)
对于本文指出用了Prim算法,虽然是自己写得代码,但是和能够搜到的prim算法得代码……额,好吧。直说了,就是当时能搜到的没看懂,或者是代码本身不能用,再或者就是黎名自己不能根据代码进行套用(被恶心到了),然后自己根据算法本身大致的意思写的,比网上能看到的繁琐很多,感觉应该还算是Prim吧?!!发出来,就是分享和自我记录的。以后有机会再改改。//(数据结构算法什么的还没怎么看过,时间复杂度和空间的占用应该还有很多不足)
相对简单的应该是用Matlab处理的。可以去找找
把原始数据放上去就是为了让写作业的你们能够直接复制的,懂得都懂,拿到作业就是一个表格,用程序把数据跑进去,也OK,但这样更直接。
代码绝对是可以用PyCharm跑出来的,跑不出来就是环境没调试好。
你需要相信我。
第二题
下一篇吧,后面在放上来。
那时你应该还在。
这篇关于【数学建模】【Python】自来水管道铺设问题(第一问)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








