本文主要是介绍任务调度框架Quartz(三)任务调度框架Quartz实例详解深入理解Scheduler,Job,Trigger,JobDetail,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
任务调度框架Quartz(三)任务调度框架Quartz实例详解深入理解Scheduler,Job,Trigger,JobDetail
2016年11月06日 17:24:50 东陆之滇 阅读数:17636 标签: quartz 任务调度 job trigger scheduler 更多
个人分类: 【任务调度框架Quartz】
所属专栏: 任务调度框架Quartz
版权声明:欢迎转载,但是请附上原文链接! https://blog.csdn.net/zixiao217/article/details/53053598
首先给一个简明扼要的理解: Scheduler 调度程序-任务执行计划表,只有安排进执行计划的任务Job(通过scheduler.scheduleJob方法安排进执行计划),当它预先定义的执行时间到了的时候(任务触发trigger),该任务才会执行。
在上一节中我们的示例中,我们预先安排了一个定时任务:该任务只做一件事,就是打印任务执行时间以及汇报任务已经执行。我们的任务类实现了org.quartz.Job这个接口:public class HelloJob implements Job,才会被安排成定是可执行任务。这一节,我们就详细了解一下Quartz中编程的几个重要接口。
(本文章分享在CSDN平台,更多精彩请阅读 东陆之滇的csdn博客:http://blog.csdn.net/zixiao217)
Quartz编程API几个重要接口
- Scheduler - 用于与调度程序交互的主程序接口。
- Job - 我们预先定义的希望在未来时间能被调度程序执行的任务类,如上一节的HelloJob类。
- JobDetail - 使用JobDetail来定义定时任务的实例。
- Trigger - 触发器,表明任务在什么时候会执行。定义了一个已经被安排的任务将会在什么时候执行的时间条件,比如上一节的实例的每2秒就执行一次。
- JobBuilder -用于声明一个任务实例,也可以定义关于该任务的详情比如任务名、组名等,这个声明的实例将会作为一个实际执行的任务。
- TriggerBuilder - 触发器创建器,用于创建触发器trigger实例。
Scheduler调度程序、SchedulerFactory调度程序工厂
Scheduler调度程序
org.quartz.Scheduler这是Quartz 调度程序的主要接口。
Scheduler维护了一个JobDetails 和Triggers的注册表。一旦在Scheduler注册过了,当定时任务触发时间一到,调度程序就会负责执行预先定义的Job。
调度程序Scheduler实例是通过SchedulerFactory工厂来创建的。一个已经创建的scheduler ,可以通过同一个工厂实例来获取它。 调度程序创建之后,它只是出于”待机”状态,必须在任务执行前调用scheduler的start()方法启用调度程序。你还可以使用shutdown()方法关闭调度程序,使用isShutdown()方法判断该调度程序是否已经处于关闭状态。通过Scheduler的scheduleJob(…)方法的几个重载方法将任务纳入调度程序中。在上一节中我们使用的是scheduleJob(JobDetail jobDetail, Trigger trigger)方法将我们预先定义的定时任务安排进调度计划中。任务安排之后,你就可以调用start()方法启动调度程序了,当任务触发时间到了的时候,该任务将被执行。
SchedulerFactory调度程序工厂
SchedulerFactory有两个默认的实现类:DirectSchedulerFactory和StdSchedulerFactory。
DirectSchedulerFactory
DirectSchedulerFactory是一个org.quartz.SchedulerFactory的单例实现。
这里有一些使用DirectSchedulerFactory的示例代码段:
示例1:你可以使用createVolatileScheduler方法去创建一个不需要写入数据库的调度程序实例:
//创建一个拥有10个线程的调度程序
DirectSchedulerFactory.getInstance().createVolatileScheduler(10);
//记得启用该调度程序
DirectSchedulerFactory.getInstance().getScheduler().start();- 1
- 2
- 3
- 4
为方便起见,提供了几种创建方法。所有创建方法最终会最终会使用所有参数的来创建调度程序:
public void createScheduler(String schedulerName, String schedulerInstanceId, ThreadPool threadPool, JobStore jobStore, String rmiRegistryHost, int rmiRegistryPort)- 1
示例2:
// 创建线程池
SimpleThreadPool threadPool = new SimpleThreadPool(maxThreads, Thread.NORM_PRIORITY);
threadPool.initialize(); // 创建job存储器
JobStore jobStore = new RAMJobStore();//使用所有参数创建调度程序
DirectSchedulerFactory.getInstance().createScheduler("My Quartz Scheduler", "My Instance", threadPool, jobStore, "localhost", 1099); // 不要忘了调用start()方法来启动调度程序
DirectSchedulerFactory.getInstance().getScheduler("My Quartz Scheduler", "My Instance").start();你也可使用JDBCJobStore,形如:
DBConnectionManager.getInstance().addConnectionProvider("someDatasource", new JNDIConnectionProvider("someDatasourceJNDIName"));JobStoreTX jdbcJobStore = new JobStoreTX(); jdbcJobStore.setDataSource("someDatasource"); jdbcJobStore.setPostgresStyleBlobs(true); jdbcJobStore.setTablePrefix("QRTZ_"); jdbcJobStore.setInstanceId("My Instance");- 1
- 2
- 3
StdSchedulerFactory
StdSchedulerFactory是org.quartz.SchedulerFactory的实现类,它是基于Quartz属性文件创建Quartz Scheduler 调度程序的。我们在上一节实例中使用的就是StdSchedulerFactory,因为我们指定了属性文件quartz.properties。
默认情况下是加载当前工作目录下的”quartz.properties”属性文件。如果加载失败,会去加载org/quartz包下的”quartz.properties”属性文件。我们使用JD-GUI反编译工具打开quartz.jar,可以在org/quartz包下找到其默认的属性文件的配置信息:
org.quartz.scheduler.instanceName: DefaultQuartzScheduler
org.quartz.scheduler.rmi.export: false
org.quartz.scheduler.rmi.proxy: false
org.quartz.scheduler.wrapJobExecutionInUserTransaction: falseorg.quartz.threadPool.class: org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount: 10
org.quartz.threadPool.threadPriority: 5
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread: trueorg.quartz.jobStore.misfireThreshold: 60000org.quartz.jobStore.class: org.quartz.simpl.RAMJobStore
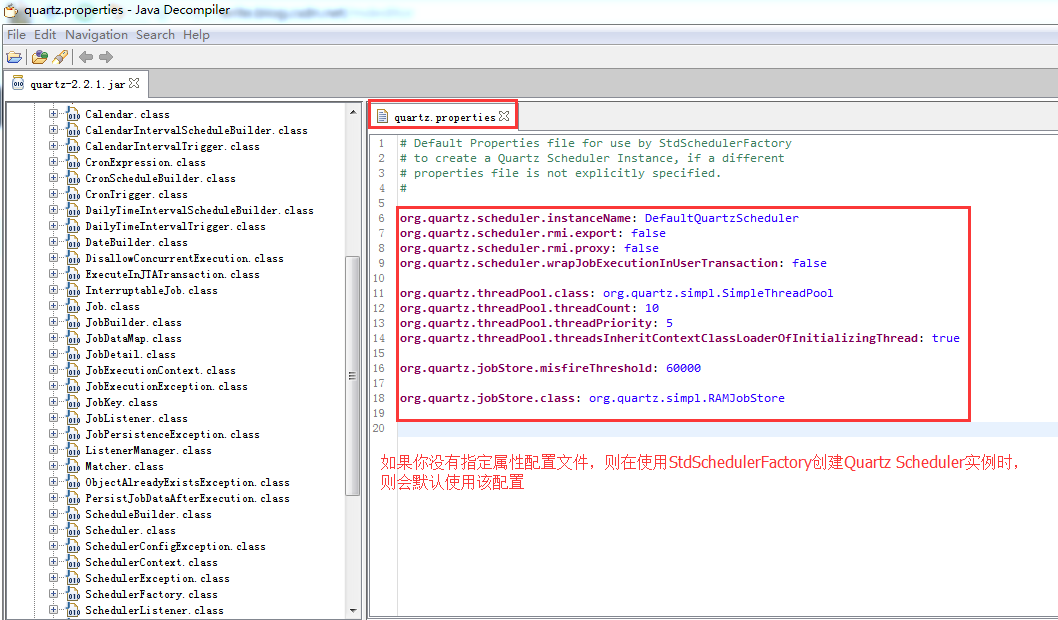
如果你不想使用默认的文件名,你可以指定org.quartz.properties属性指向你的属性配置文件。要不然,你可以在调用getScheduler()方法之前调用initialize(xx)方法初始化工厂配置。
属性配置文件中,还可以引用其他配置文件的信息,你可以使用$@来引用:
quartz1.properties
org.quartz.scheduler.instanceName=HelloScheduler- 1
quartz2.properties
org.quartz.scheduler.instanceName=$@org.quartz.scheduler.instanceName- 1
参照以下StdSchedulerFactory的属性配置,实际使用中你自己可以指定一些符合需求的参数,例如指定存储器可以配置org.quartz.jobStore.class的值。
PROPERTIES_FILE = "org.quartz.properties";PROP_SCHED_INSTANCE_NAME = "org.quartz.scheduler.instanceName";PROP_SCHED_INSTANCE_ID = "org.quartz.scheduler.instanceId";PROP_SCHED_INSTANCE_ID_GENERATOR_CLASS = "org.quartz.scheduler.instanceIdGenerator.class";PROP_SCHED_THREAD_NAME = "org.quartz.scheduler.threadName";PROP_SCHED_SKIP_UPDATE_CHECK = "org.quartz.scheduler.skipUpdateCheck";PROP_SCHED_BATCH_TIME_WINDOW = "org.quartz.scheduler.batchTriggerAcquisitionFireAheadTimeWindow";PROP_SCHED_MAX_BATCH_SIZE = "org.quartz.scheduler.batchTriggerAcquisitionMaxCount";PROP_SCHED_JMX_EXPORT = "org.quartz.scheduler.jmx.export";PROP_SCHED_JMX_OBJECT_NAME = "org.quartz.scheduler.jmx.objectName";PROP_SCHED_JMX_PROXY = "org.quartz.scheduler.jmx.proxy";PROP_SCHED_JMX_PROXY_CLASS = "org.quartz.scheduler.jmx.proxy.class";PROP_SCHED_RMI_EXPORT = "org.quartz.scheduler.rmi.export";PROP_SCHED_RMI_PROXY = "org.quartz.scheduler.rmi.proxy";PROP_SCHED_RMI_HOST = "org.quartz.scheduler.rmi.registryHost";PROP_SCHED_RMI_PORT = "org.quartz.scheduler.rmi.registryPort";PROP_SCHED_RMI_SERVER_PORT = "org.quartz.scheduler.rmi.serverPort";PROP_SCHED_RMI_CREATE_REGISTRY = "org.quartz.scheduler.rmi.createRegistry";PROP_SCHED_RMI_BIND_NAME = "org.quartz.scheduler.rmi.bindName";PROP_SCHED_WRAP_JOB_IN_USER_TX = "org.quartz.scheduler.wrapJobExecutionInUserTransaction";PROP_SCHED_USER_TX_URL = "org.quartz.scheduler.userTransactionURL";PROP_SCHED_IDLE_WAIT_TIME = "org.quartz.scheduler.idleWaitTime";PROP_SCHED_DB_FAILURE_RETRY_INTERVAL = "org.quartz.scheduler.dbFailureRetryInterval";PROP_SCHED_MAKE_SCHEDULER_THREAD_DAEMON = "org.quartz.scheduler.makeSchedulerThreadDaemon";PROP_SCHED_SCHEDULER_THREADS_INHERIT_CONTEXT_CLASS_LOADER_OF_INITIALIZING_THREAD = "org.quartz.scheduler.threadsInheritContextClassLoaderOfInitializer";PROP_SCHED_CLASS_LOAD_HELPER_CLASS = "org.quartz.scheduler.classLoadHelper.class";PROP_SCHED_JOB_FACTORY_CLASS = "org.quartz.scheduler.jobFactory.class";PROP_SCHED_INTERRUPT_JOBS_ON_SHUTDOWN = "org.quartz.scheduler.interruptJobsOnShutdown";PROP_SCHED_INTERRUPT_JOBS_ON_SHUTDOWN_WITH_WAIT = "org.quartz.scheduler.interruptJobsOnShutdownWithWait";PROP_THREAD_POOL_CLASS = "org.quartz.threadPool.class";PROP_JOB_STORE_CLASS = "org.quartz.jobStore.class";PROP_JOB_STORE_USE_PROP = "org.quartz.jobStore.useProperties";PROP_CONNECTION_PROVIDER_CLASS = "connectionProvider.class";Job定时任务实例类
一个任务是一个实现org.quartz.Job接口的类,任务类必须含有空构造器,它只有一个简单的方法:
void execute(JobExecutionContext context)throws JobExecutionException;当关联这个任务实例的触发器表明的执行时间到了的时候,调度程序Scheduler 会调用这个方法来执行任务,我们的任务内容就可以在这个方法中执行。
public class HelloJob implements Job {@Overridepublic void execute(JobExecutionContext context) throws JobExecutionException {System.out.println("现在是北京时间:" + DateUtil.getCurrDateTime() + " - helloJob任务执行");}}在该方法退出之前,会设置一个结果对象到JobExecutionContext 中。尽管这个结果对Quartz来说没什么意义,但是JobListeners或者TriggerListeners 来说,是可以监听查看job的执行情况的。后面会详细讲解监听器的内容。
JobDataMap提供了一种”初始化成员属性数据的机制”,在实现该Job接口的时候可能会用到。
Job实例化的过程
可能很多人对于一个Job实例的组成以及创建过程感到迷惑,笔者曾经也是如此,所以现在请耐心理解。
你可以创建一个Job类,在调度程序(任务计划表)中创建很多JobDetai可以存储很多初始化定义信息——每一个都可以设置自己的属性和JobDataMap——将他们全部添加到调度程序中去。
这里举个例子说明一下,你可以创建一个任务类实现Job接口,不妨称之为”SalesReportJob”,我们用它做销售报表使用。我们可以通过JobDataMap指定销售员的名称和销售报表的依据等等。这就会创建多个JobDetails了,例如”SalesReportForJoe”,”SalesReportForMike”分别对应在JobDataMap中指定的名字”joe”和”mike”。
重要:当触发器的执行时间到了的时候,会加载与之关联的JobDetail,并在调度程序Scheduler中通过JobFactory的配置实例化它引用的Job。JobFactory 调用newInstance()创建一个任务实例,然后调用setter 方法设置在JobDataMap定义好的名字。你可以实现JobFactory,比如使用IOC或DI机制初始化的任务实例。
Job的声明和并发
关于Job的声明和并发需要说明一下,以下一对注解使用在你的Job类中,可以影响Quartz的行为:
@DisallowConcurrentExecution : 可以添加到你的任务类中,它会告诉Quartz不要执行多个任务实例。
注意措辞,在上面的”SalesReportJob”类添加该注解,将会只有一个”SalesReportForJoe”实例在给定的时间执行,但是”SalesReportForMike”是可以执行的。这个约束是基于JobDetail的,而不是基于任务类的。
@PersistJobDataAfterExecution : 告诉Quartz在任务执行成功完毕之后(没有抛出异常),修改JobDetail的JobDataMap备份,以供下一个任务使用。
如果你使用了@PersistJobDataAfterExecution 注解的话,强烈建议同时使用@DisallowConcurrentExecution注解,以避免当两个同样的job并发执行的时候产生的存储数据迷惑。
Job的其他一些属性
- 持久化 - 如果一个任务不是持久化的,则当没有触发器关联它的时候,Quartz会从scheduler中删除它。
- 请求恢复 - 如果一个任务请求恢复,一般是该任务执行期间发生了系统崩溃或者其他关闭进程的操作,当服务再次启动的时候,会再次执行该任务。这种情况下,JobExecutionContext.isRecovering()会返回true。
JobDetail定义任务实例的一些属性特征
org.quartz.JobDetail接口负责传输给定的任务实例的属性到Scheduler。JobDetail是通过JobBuilder创建的。
Quartz不会存储一个真实的Job类实例,但是允许你通过JobDetail定义一个任务实例——JobDetail是用来定义任务实例的。
任务Job有一个名称name 和组group 来关联。在一个Scheduler中这二者的组合必须是唯一的。
触发器任务计划执行表的执行”机制”。多个触发器可以指向同一个工作,但一个触发器只能指向一个工作。
JobDataMap任务数据映射
JobDataMap用来保存任务实例的状态信息。
当一个Job被添加到调度程序(任务执行计划表)scheduler的时候,JobDataMap实例就会存储一次关于该任务的状态信息数据。也可以使用@PersistJobDataAfterExecution注解标明在一个任务执行完毕之后就存储一次。
JobDataMap实例也可以村粗一个触发器trigger。这是非常有用的,特别是当你的任务被多个触发器引用的时候,根据不同的触发时机,你可以提供不同的输入条件。
JobExecutionContext 也可以再执行时包含一个方便的JobDataMap ,它合并了触发器的 JobDataMap (如果有的话)和Job的 JobDataMap (如果有的话)。
这里我们改一下上一节的程序作为示例,在定义JobDetail的时候,将一些数据放入JobDataMap 中:
// 定义一个job,并且绑定HelloJob类JobDetail job = newJob(HelloJob.class).withIdentity("job1", "group1").usingJobData("jobSays", "Hello World!").usingJobData("myFloatValue", 3.141f).build();然后在任务执行的时候,可以获取JobDataMap 中的数据:
package org.byron4j.quartz;import org.byron4j.utils.DateUtil;
import org.quartz.Job;
import org.quartz.JobDataMap;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.quartz.JobKey;/*** 实现org.quartz.Job接口,声明该类是一个可执行任务类* * @author Administrator**/
public class HelloJob implements Job {@Overridepublic void execute(JobExecutionContext context) throws JobExecutionException {System.out.println("现在是北京时间:" + DateUtil.getCurrDateTime() + " - helloJob任务执行");JobKey key = context.getJobDetail().getKey();JobDataMap dataMap = context.getJobDetail().getJobDataMap();String jobSays = dataMap.getString("jobSays");float myFloatValue = dataMap.getFloat("myFloatValue");System.err.println("Instance " + key + " of HelloJob says: " + jobSays + ", and val is: " + myFloatValue);}}
控制台输出:
scheduleName = MyScheduler
现在是北京时间:2016-11-06 16:24:57 - helloJob任务执行
Instance group1.job1 of HelloJob says: Hello World!, and val is: 3.141
现在是北京时间:2016-11-06 16:24:59 - helloJob任务执行
Instance group1.job1 of HelloJob says: Hello World!, and val is: 3.141
现在是北京时间:2016-11-06 16:25:01 - helloJob任务执行
Instance group1.job1 of HelloJob says: Hello World!, and val is: 3.141我们在触发器也添加数据:
JobDetail job = newJob(HelloJob.class).withIdentity("job1", "group1").usingJobData("jobSays", "Hello World!").usingJobData("myFloatValue", 3.141f).build();// 声明一个触发器,现在就执行(schedule.start()方法开始调用的时候执行);并且每间隔2秒就执行一次
Trigger trigger = newTrigger().withIdentity("trigger1", "group1").usingJobData("trigger_key", "每2秒执行一次").startNow().withSchedule(simpleSchedule().withIntervalInSeconds(2).repeatForever()) .build();HelloJob的execute方法改成如下:
public void execute(JobExecutionContext context) throws JobExecutionException {JobKey key = context.getJobDetail().getKey();//使用归并的JobDataMapJobDataMap dataMap = context.getMergedJobDataMap(); String jobSays = dataMap.getString("jobSays");float myFloatValue = dataMap.getFloat("myFloatValue");String triggerSays = dataMap.getString("trigger_key");System.err.println("Instance " + key + " of HelloJob says: " + jobSays + ", and val is: " + myFloatValue+ ";trigger says:" + triggerSays);}控制台输出如下,得到了job、trigger的JobDataMap 的数据:
scheduleName = MyScheduler
Instance group1.job1 of HelloJob says: Hello World!, and val is: 3.141;trigger says:每2秒执行一次
Instance group1.job1 of HelloJob says: Hello World!, and val is: 3.141;trigger says:每2秒执行一次Trigger触发器
Trigger触发器,可以理解为安排了一个任务,这个任务是在每年9月10日早上9点向你敬爱的老师发送一天祝福短信,触发器就是指每年9月10日早上9点触发执行这个任务。
触发器使用TriggerBuilder来实例化。
触发器有一个TriggerKey关联,这在一个Scheduler中必须是唯一的。
触发器任务计划执行表的执行”机制”。多个触发器可以指向同一个工作,但一个触发器只能指向一个工作。
触发器可以传送数据给job——通过将数据放进触发器的JobDataMap。
触发器常用属性
触发器也有很多属性,这些属性都是在使用TriggerBuilder 定义触发器时设置的。
- TriggerKey - 唯一标识触发器,这在一个Scheduler中必须是唯一的
- “startTime” - 开始时间,通常使用startAt(java.util.Date)
- “endTime” - 结束时间,设置了结束时间则在这之后,不再触发
触发器的优先级
有时候,你会安排很多任务,但是Quartz并没有更多的资源去处理它。这种情况下,你必须需要很好地控制哪个任务先执行了。这时候你可以使用设置priority 属性(使用方法withPriority(int))来控制触发器的优先级。
注意:优先级只有触发器出发时间一样的时候才有意义。
注意:当一个任务请求恢复执行时,它的优先级和原始优先级是一样的。
JobBuilder用于创建JobDetail;TriggerBuilder 用于创建触发器Trigger
JobBuilder用于创建JobDetail。总是把保持在有效状态,合理的使用默认设置在你调用build() 方法的时候。如果你没有调用withIdentity(..)指定job的名字,它会自动给你生成一个。
TriggerBuilder 用于创建触发器Trigger。如果你没有调用withSchedule(..) 方法,会使用默认的schedule 。如果没有使用withIdentity(..) 会自动生成一个触发器名称给你。
Quartz通过一种领域特定语言(DSL)提供了一种自己的builder的风格API来创建任务调度相关的实体。DSL可以通过对类的静态方法的使用来调用:TriggerBuilder, JobBuilder, DateBuilder, JobKey, TriggerKey 以及其它的关于Schedule创建的实现。
客户端可以使用类似示例使用DSL:
/*静态引入builder*/
import static org.quartz.JobBuilder.newJob;
import static org.quartz.SimpleScheduleBuilder.simpleSchedule;
import static org.quartz.TriggerBuilder.newTrigger;JobDetail job = newJob(MyJob.class).withIdentity("myJob").build();Trigger trigger = newTrigger() .withIdentity(triggerKey("myTrigger", "myTriggerGroup")).withSchedule(simpleSchedule().withIntervalInHours(1).repeatForever()).startAt(futureDate(10, MINUTES)).build();
scheduler.scheduleJob(job, trigger);总结:Scheduler—job—trigger
我们以一个现实生活中的例子为例:
Scheduler就是定时任务执行计划表,目前共有两个job安排进了执行计划:元旦放假不上班,春节放假团圆在家,这些都是ZF预先定义好的执行计划。”元旦放假不上班”、”春节放假团圆在家”是两个job,第一个job的触发时间是每年1月1日(触发器1),第二个job是每年的农历初一(触发器2)。

发表评论
添加代码片
- HTML/XML
- objective-c
- Ruby
- PHP
- C
- C++
- JavaScript
- Python
- Java
- CSS
- SQL
- 其它
还能输入1000个字符

qq_35605246: 你好,最近遇到quartz集群的一个问题,非常苦恼,望给点建议或思路,谢谢。 描述:该任务每天5点执行,三台服务器,A服务器从05:00:00.092~05:11:47.263执行结束(执行结果是成功的),B服务器从05:05:50.082~05:11:47.270执行结束(结果失败,因为A服务器正在执行中,例如锁表等),C服务器从05:11:40.092~05:11:47.320执行结束(结果失败,和B服务器一样),从结果看quartz会有这样大概5分钟左右的机制吗?如果5分钟左右没有执行完,集群时,另一台quartz会接手继续执行?(1年前#3楼)查看回复(1)举报回复
-

东陆之滇回复 qq_35605246:您好,可以使用@DisallowConcurrentExecution注解可以添加到你的任务类中,它会告诉Quartz不要执行多个任务实例(1年前)举报回复

唯一本尊: 好文章,准确,明白,但是有个地方可能没说清楚,group其实可以不用的(1年前#2楼)举报回复

Magical*Man: 讲解详细 内容充实(1年前#1楼)举报回复
这篇关于任务调度框架Quartz(三)任务调度框架Quartz实例详解深入理解Scheduler,Job,Trigger,JobDetail的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




