本文主要是介绍LightDB 23.3 通过GUC参数控制commit fetch,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
commit游标提交之后,可以继续使用fetch进行结果集的操作。commit和fetch结合使用功能开发时不考虑分布式。后续,又对分布式进行了测试,发现持有portal后,代码中会对querydesc进行非空判断。当querydesc为空时,LightDB数据库崩溃。修改成对querydesc作非空判断之后,又会导致之前使用一个全局变量接收portal的方案失败。现在一个sql执行完,portal就会释放掉。在事务中调用打开游标的函数, 由于portal被释放,打开的游标就不能继续被fetch,故报游标不存在。
解决方案
因此决定将commit游标提交之后,可以继续使用fetch进行结果集的操作的功能利用GUC参数lightdb_cursor_after_commit 进行限制,去掉之前使用全局变量存储持有的portal的全部逻辑。
lightdb_cursor_after_commit 为off,不能在一个事务提交之后,再去fetch
操作这个结果集;为on时,一个事务提交之后,这个游标还可以继续使用。
测试
lightdb_cursor_after_commit 设置成 off
set lightdb_cursor_after_commit to off;
create function fg(ref inout refcursor) return int as
begin
open ref for select * from nested_tab;
return 0;
end;
/
CREATE FUNCTION
lightdb@test_createdb_oracle=# begin;
BEGIN
lightdb@test_createdb_oracle=*# select fg('cf');fg
----0
(1 row)lightdb@test_createdb_oracle=*# fetch all in cf;id | name | job | age
----+-------+-------+-----1 | asda | gfdgd | 122 | sdfsd | cvxvx | 143 | uyiy | mmbv | 16
(3 rows)
lightdb_cursor_after_commit 设置成 on
set lightdb_cursor_after_commit to on;
create or replace function fg(ref inout refcursor) return int as
begin
open ref for select * from nested_tab;
return 0;
end;
/
lightdb@test_createdb_oracle=# begin;
BEGIN
lightdb@test_createdb_oracle=*# select fg('cf');fg
----0
(1 row)lightdb@test_createdb_oracle=*# fetch all in cf;id | name | job | age
----+-------+-------+-----1 | asda | gfdgd | 122 | sdfsd | cvxvx | 143 | uyiy | mmbv | 16
(3 rows)lightdb@test_createdb_oracle=*# commit;
COMMIT
lightdb@test_createdb_oracle=# fetch all in cf;id | name | job | age
----+------+-----+-----
(0 rows)lightdb@test_createdb_oracle=# fetch all in cf;
ERROR: cursor "cf" does not exist
java测试:
package test;import java.math.BigDecimal;
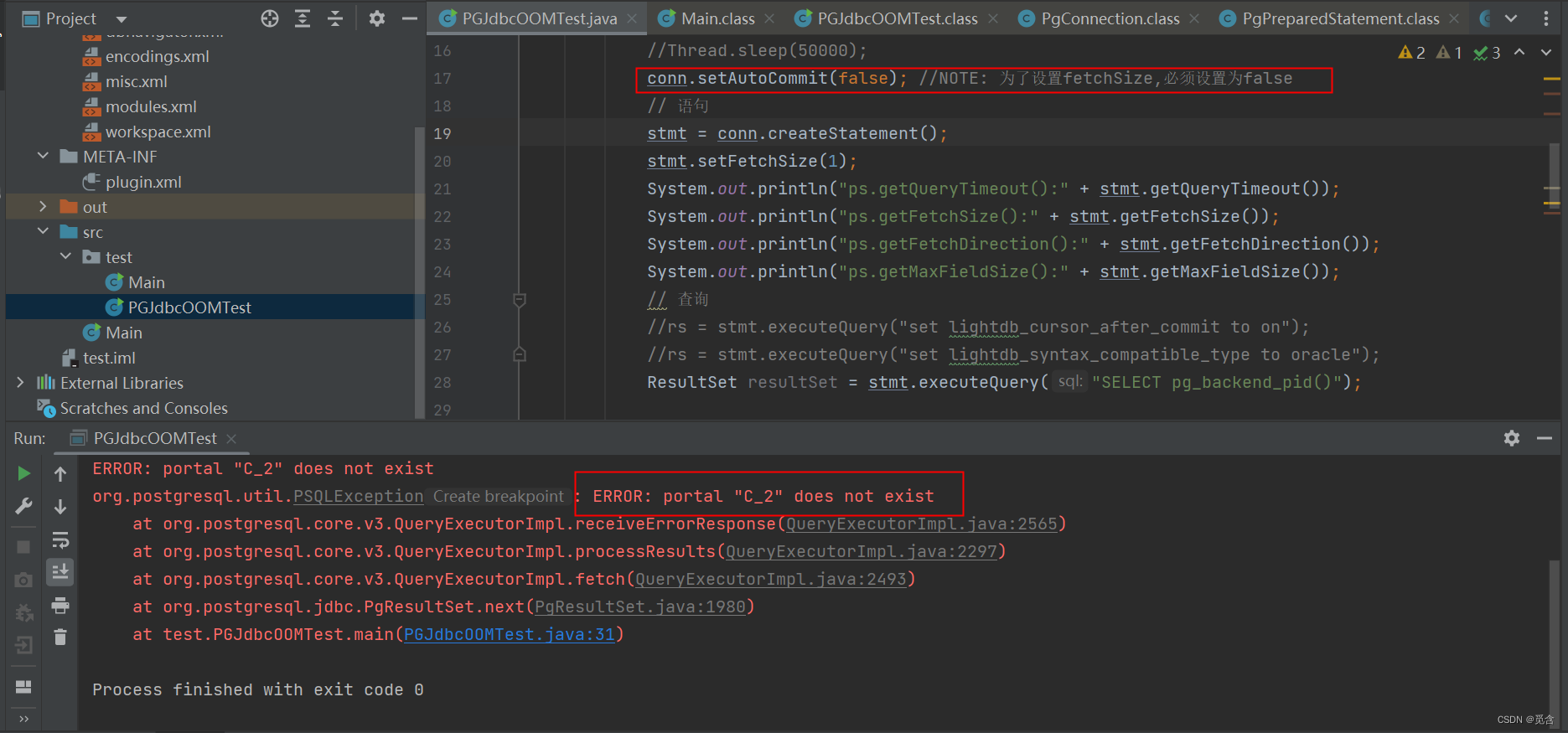
import java.sql.*;public class PGJdbcOOMTest {public static void main(String[] args) {Connection conn = null;Statement stmt = null;ResultSet rs = null;try {Class.forName("org.postgresql.Driver");java.lang.String dbURL = "jdbc:postgresql://192.168.105.161:5432/test_hs_oracle";conn = DriverManager.getConnection(dbURL, "lightdb", "1");//Thread.sleep(50000);conn.setAutoCommit(false); //NOTE: 为了设置fetchSize,必须设置为false// 语句stmt = conn.createStatement();stmt.setFetchSize(1);System.out.println("ps.getQueryTimeout():" + stmt.getQueryTimeout());System.out.println("ps.getFetchSize():" + stmt.getFetchSize());System.out.println("ps.getFetchDirection():" + stmt.getFetchDirection());System.out.println("ps.getMaxFieldSize():" + stmt.getMaxFieldSize());// 查询//rs = stmt.executeQuery("set lightdb_cursor_after_commit to on");//rs = stmt.executeQuery("set lightdb_syntax_compatible_type to oracle");ResultSet resultSet = stmt.executeQuery("SELECT pg_backend_pid()");rs = stmt.executeQuery("SELECT * FROM nested_tab;");while(rs.next()){System.out.println(rs.getObject(1));conn.commit();}} catch (Exception e) {System.err.println(e.getMessage());e.printStackTrace();}finally {try {if(rs != null){rs.close();}} catch (SQLException e) {System.err.println(e.getMessage());e.printStackTrace();}try {if(stmt != null) {stmt.close();}} catch (SQLException e) {System.err.println(e.getMessage());e.printStackTrace();}try {if(conn != null) {conn.close();}} catch (SQLException e) {System.err.println(e.getMessage());e.printStackTrace();}}}}
–lightdb_cursor_after_commit 设置成 off
–lightdb_cursor_after_commit 设置成 on
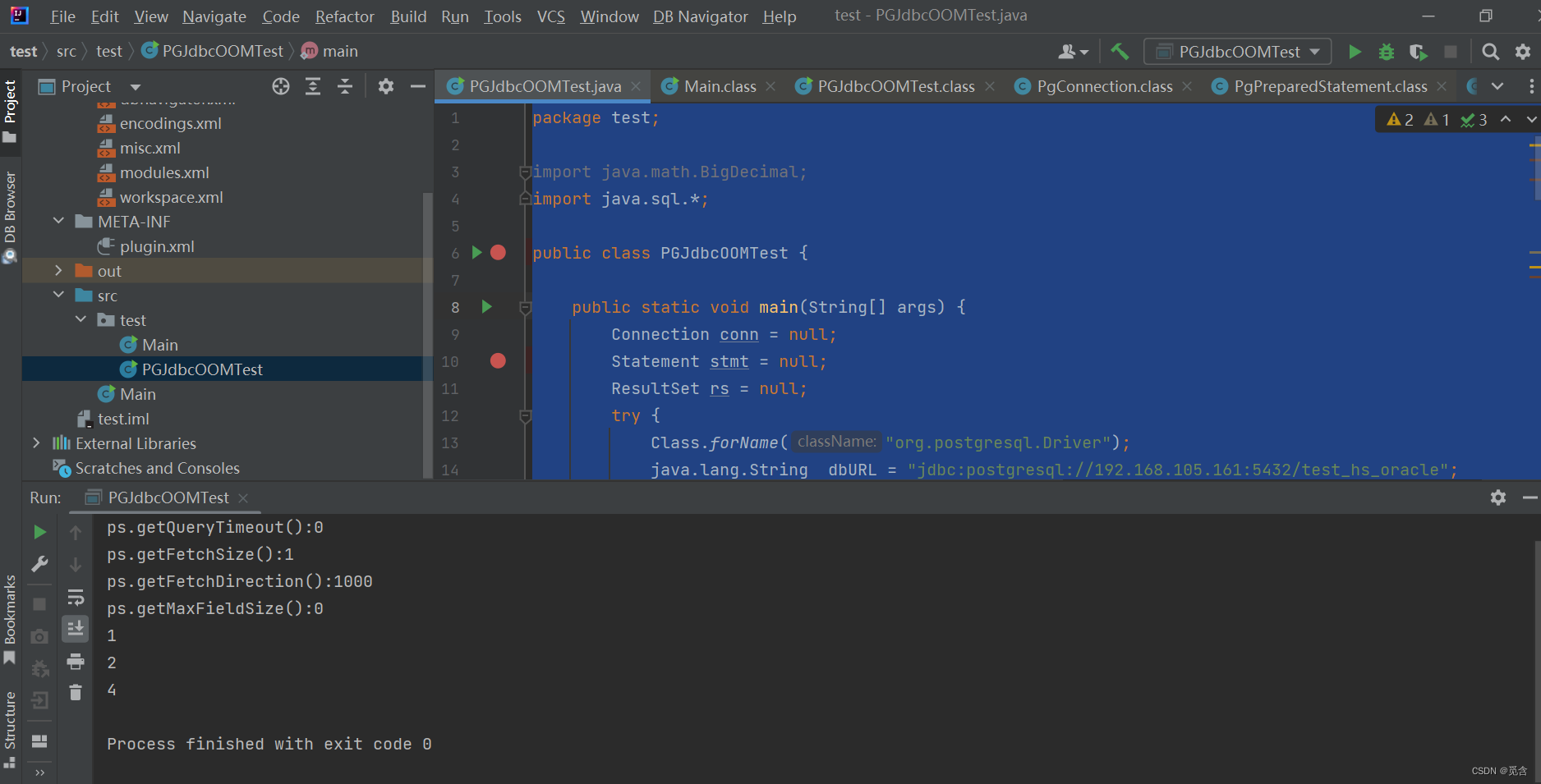
针对for update和for share测试
set lightdb_cursor_after_commit to on
for update
create table nested_tab(id int primary key, name varchar2(100), job varchar2(100), age int);
insert into nested_tab values (1, 'asda', 'gfdgd', 12);
insert into nested_tab values (2, 'sdfsd', 'cvxvx', 14);
insert into nested_tab values (3, 'uyiy', 'mmbv', 16);create or replace function fg(ref inout refcursor) return int as
begin
open ref for select * from nested_tab for update;
return 0;
end;
/lightdb@test_hs_oracle=# begin;
BEGIN
lightdb@test_hs_oracle=*# select fg('cf');fg
----0
(1 row)lightdb@test_hs_oracle=*# fetch all in cf;id | name | job | age
----+-------+-------+-----1 | asda | gfdgd | 122 | sdfsd | cvxvx | 143 | uyiy | mmbv | 16
(3 rows)lightdb@test_hs_oracle=*# commit;
COMMIT
lightdb@test_hs_oracle=# fetch all in cf;id | name | job | age
----+------+-----+-----
(0 rows)lightdb@test_hs_oracle=# fetch all in cf;
ERROR: cursor "cf" does not exist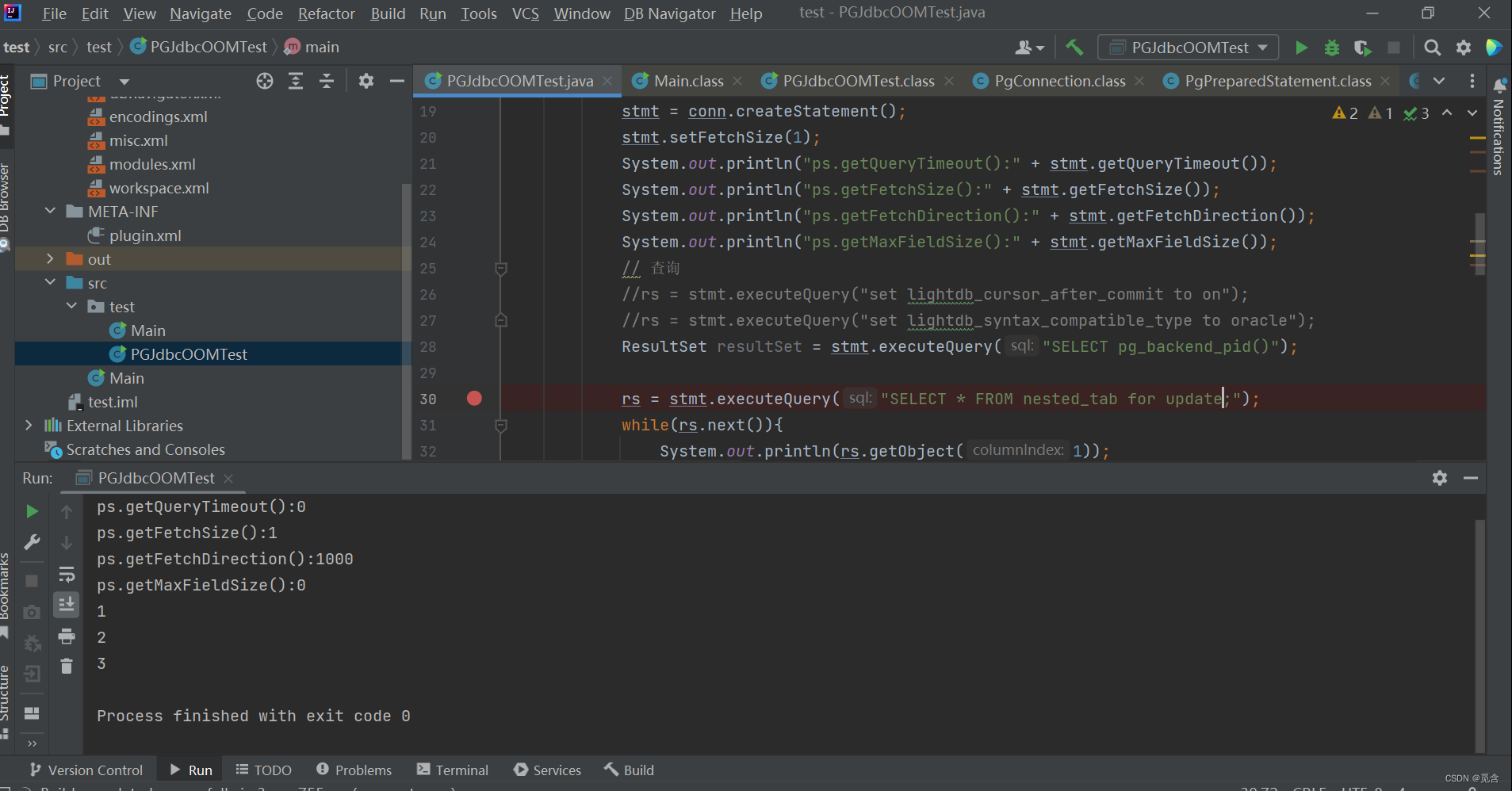
for share
create or replace function fg(ref inout refcursor) return int as
begin
open ref for select * from nested_tab for share;
return 0;
end;
/lightdb@test_hs_oracle=# begin;
BEGIN
lightdb@test_hs_oracle=*# select fg('cf');fg
----0
(1 row)lightdb@test_hs_oracle=*# fetch all in cf;id | name | job | age
----+-------+-------+-----1 | asda | gfdgd | 122 | sdfsd | cvxvx | 143 | uyiy | mmbv | 16
(3 rows)lightdb@test_hs_oracle=*# commit;
COMMIT
lightdb@test_hs_oracle=# fetch all in cf;id | name | job | age
----+------+-----+-----
(0 rows)lightdb@test_hs_oracle=# fetch all in cf;
ERROR: cursor "cf" does not exist
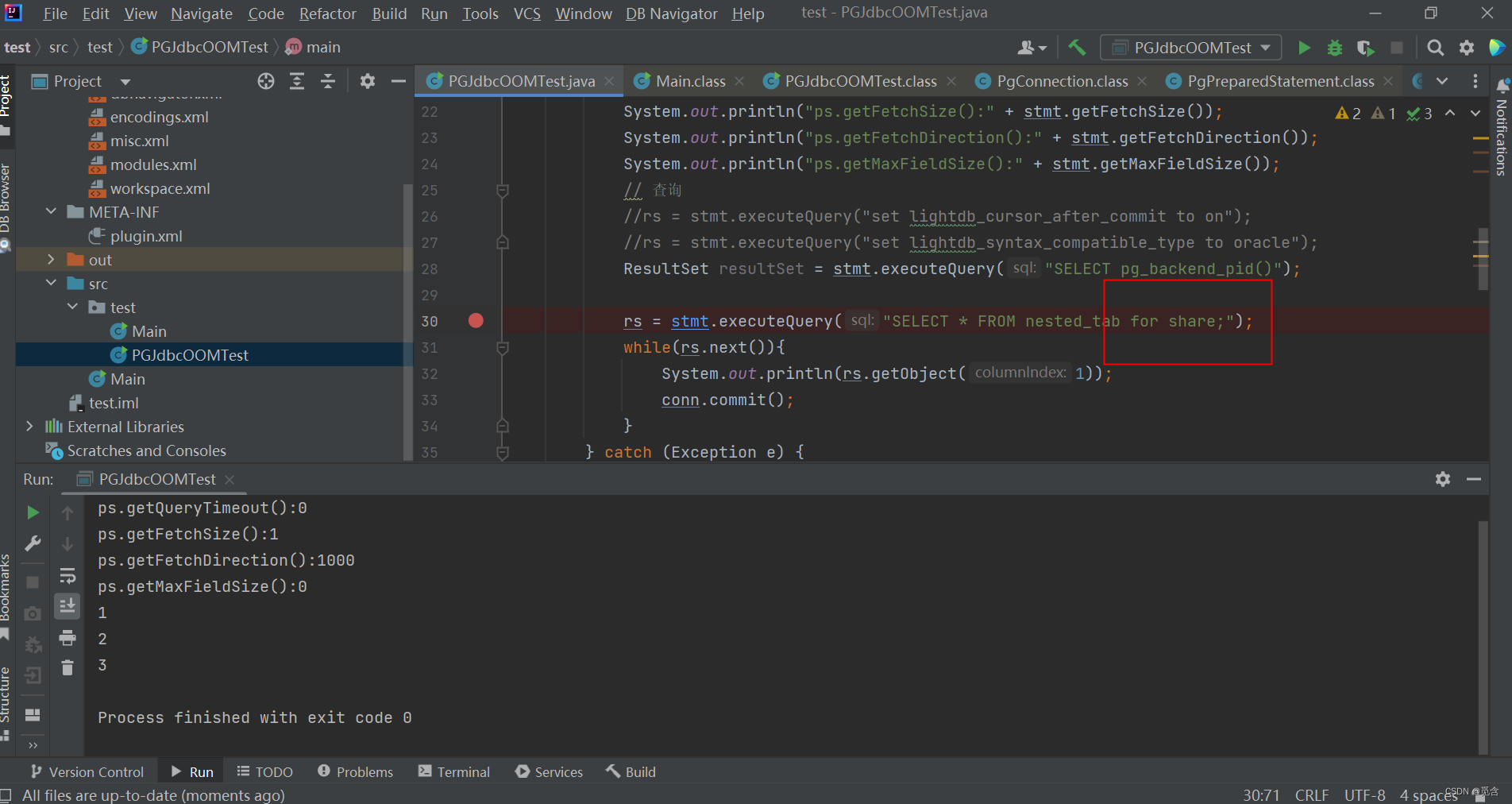
分布式测试
lightdb分布式参照:分布式
set lightdb_cursor_after_commit to off
create table nested_tab(id int primary key, name varchar2(100), job varchar2(100), age int);
insert into nested_tab values (1, 'asda', 'gfdgd', 12);
insert into nested_tab values (2, 'sdfsd', 'cvxvx', 14);
insert into nested_tab values (3, 'uyiy', 'mmbv', 16);select create_distributed_table('nested_tab','id');create function fg(ref inout refcursor) return int as
begin
open ref for select * from nested_tab;
return 0;
end;
/
lightdb@test_hs_oracle=# begin;
BEGIN
lightdb@test_hs_oracle=*# select fg('cf');fg
----0
(1 row)lightdb@test_hs_oracle=*# fetch all in cf;id | name | job | age
----+-------+-------+-----1 | asda | gfdgd | 123 | uyiy | mmbv | 162 | sdfsd | cvxvx | 14
(3 rows)lightdb@test_hs_oracle=*# commit;
COMMIT
lightdb@test_hs_oracle=# fetch all in cf;
ERROR: cursor "cf" does not exist
set lightdb_cursor_after_commit to on
create table nested_tab(id int primary key, name varchar2(100), job varchar2(100), age int);
insert into nested_tab values (1, 'asda', 'gfdgd', 12);
insert into nested_tab values (2, 'sdfsd', 'cvxvx', 14);
insert into nested_tab values (3, 'uyiy', 'mmbv', 16);select create_distributed_table('nested_tab','id');create function fg(ref inout refcursor) return int as
begin
open ref for select * from nested_tab;
return 0;
end;
/lightdb@test_hs_oracle=# begin;
BEGIN
lightdb@test_hs_oracle=*# select fg('cf');fg
----0
(1 row)lightdb@test_hs_oracle=*# fetch all in cf;id | name | job | age
----+-------+-------+-----1 | asda | gfdgd | 123 | uyiy | mmbv | 162 | sdfsd | cvxvx | 14
(3 rows)lightdb@test_hs_oracle=*# commit;
COMMITlightdb@test_hs_oracle=# fetch all in cf;id | name | job | age
----+------+-----+-----
(0 rows)lightdb@test_hs_oracle=# fetch all in cf;
ERROR: cursor "cf" does not exist
for update/for share
create or replace function fg(ref inout refcursor) return int as
begin
open ref for select * from nested_tab for update;
return 0;
end;
/
lightdb@test_hs_oracle=# create or replace function fg(ref inout refcursor) return int as
lightdb@test_hs_oracle$# begin
lightdb@test_hs_oracle$# open ref for select * from nested_tab for update;
lightdb@test_hs_oracle$# return 0;
lightdb@test_hs_oracle$# end;
lightdb@test_hs_oracle$# /
CREATE FUNCTION
lightdb@test_hs_oracle=# begin;
BEGIN
lightdb@test_hs_oracle=*# select fg('cf');
ERROR: could not run distributed query with FOR UPDATE/SHARE commands
HINT: Consider using an equality filter on the distributed table's partition column.
CONTEXT: SQL statement "select * from nested_tab for update"
PL/oraSQL function fg(refcursor) line 3 at OPEN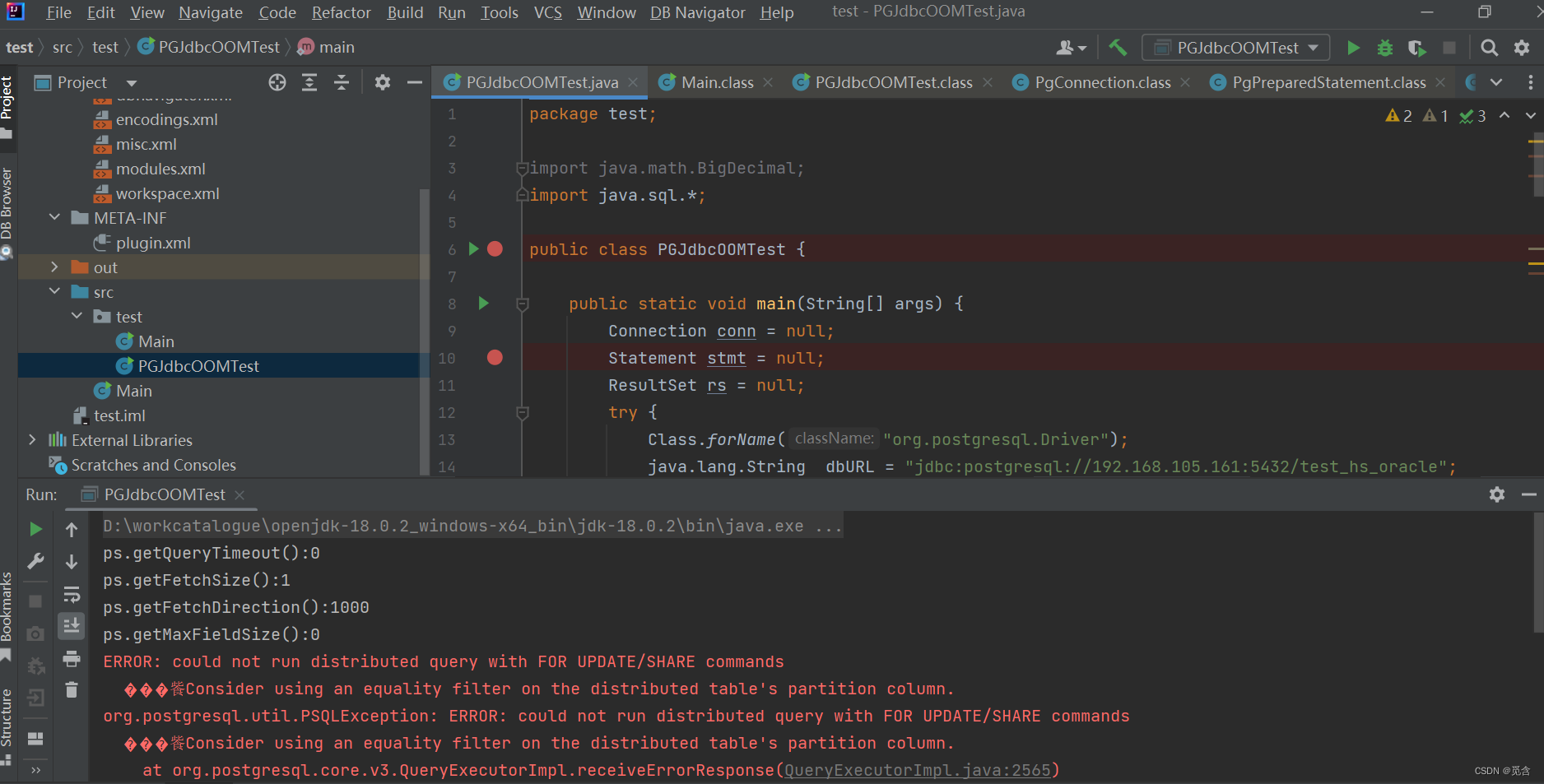
总结
set lightdb_cursor_after_commit to on;在同一个会话中的后续事务中还能够继续访问该游标( 但是如果创建事务被中止,游标会被移除)。对于for update和for share lightdb_cursor_after_commit 参数使能单机模式还是支持的,分布式模式下由于不支持for update和for share直接报错。java端同理。
参见:declare
这篇关于LightDB 23.3 通过GUC参数控制commit fetch的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





