本文主要是介绍DAX教程:篮子分析2.0,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者|Davis Zhang 编译|VK 来源|Towards Data Science
本文旨在利用DAX分析Power-BI中的客户购买行为,并深入了解产品潜力。
几年前,Marco Russo和Alberto Ferrari发表了一篇名为“篮子分析”的博客
https://www.daxpatterns.com/basket-analysis/
这篇有趣的文章详细描述了如何使用DAX计算任何产品组合下的订单数量和客户数量等非常有用的指标。本文可以看作是“篮子分析”的一个扩展,它考虑了顾客购买不同产品的时间顺序。
与原始的“篮子分析”相比
假设A和B代表两种不同的产品,那么“篮子分析”计算P(AB),而本文计算P(A|B)和P(B|A)。你可以比较下面的两个数字:

上图是“篮子分析”中“两种产品都有顾客”的衡量标准,显示72位顾客同时拥有“瓶笼”和“自行车架”的购买记录。
但是,下图中显示的数据考虑了客户购买产品的时间顺序。你可以发现,先购买自行车架后购买瓶、笼的客户有8家,先购买瓶、笼后购买自行车架的客户有14家(注:暂时不考虑同时购买A、B的情况)

为什么这个分析有意义
客户的订单记录反映了一些非常有用的事实,为产品之间的相关性提供了方向。换言之,“购物篮分析”在分析超市数据时非常有用,因为顾客通常在购物时选择多种产品,然后到收银台一起下订单。
在这种情况下,所有产品都被视为同时订购。但事实上,在超市购物过程中,顾客选择的不同产品的记录是无法追踪的。
但如果是在其他情况下,比如客户在电子商务平台或官网上下单,如果你是店长,你可能想知道A和B是最畅销的车型,哪一款可以带来更多的回头客,哪一款更容易流失客户。
因此,我们需要知道每种产品的回购百分比。例如,所有先购买产品A的顾客,未来会有多少人再回来购买产品,进一步分析,在这些人中,购买的仍然是产品A或其他产品?各占多少比例,这是一个值得研究的问题。
计算过程
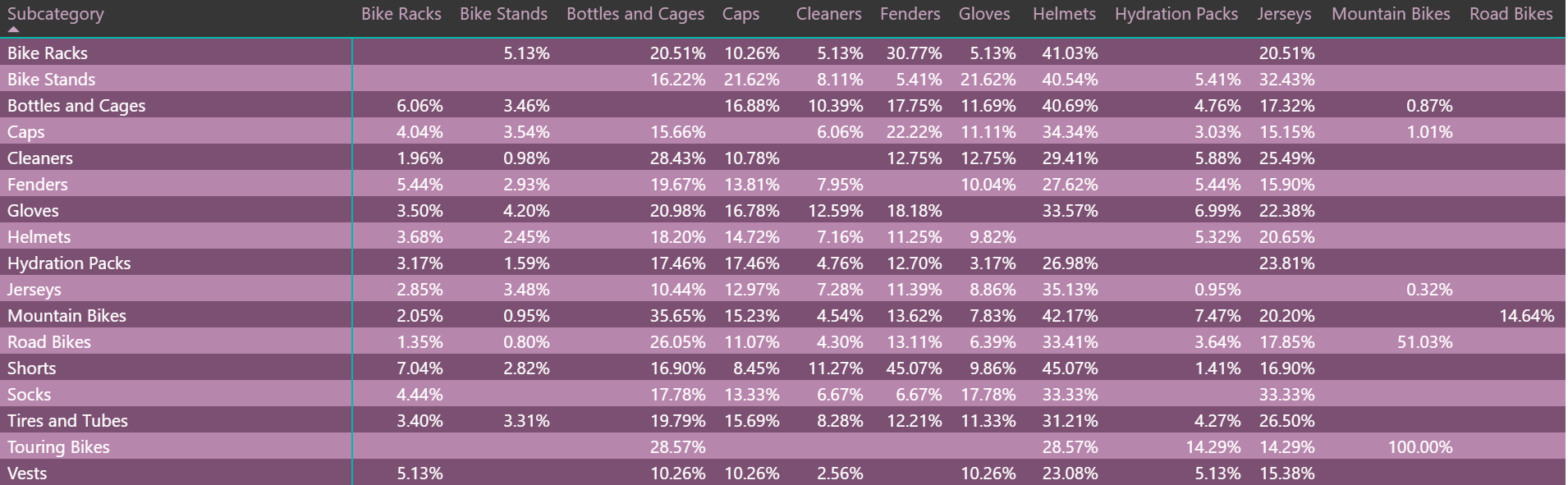
经过计算过程,我们最终将得到如下图所示的计算结果(注:我使用与“篮子分析”相同的数据集):
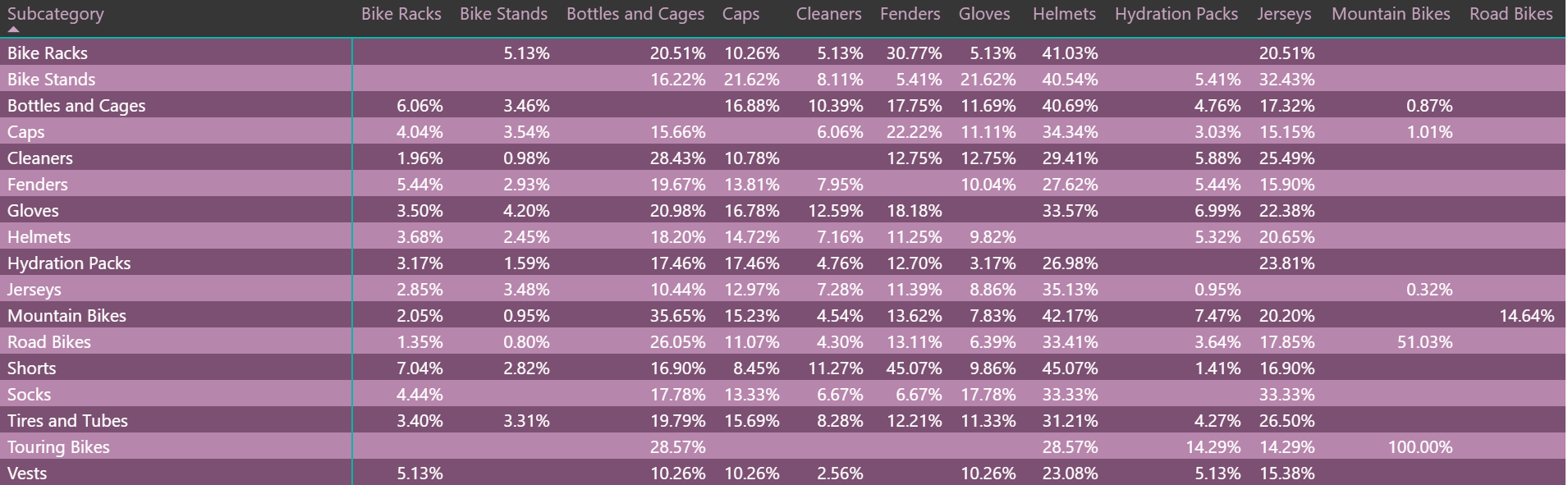
如前所述,它显示了哪些客户先购买了产品A并有后续的购买记录,他们中有多少人购买了产品B或产品C等。
因此,为了达到这个计算结果,这里有五个步骤:
1.首先,对销售表中的所有订单进行分类,在客户的所有订单中,一个或多个订单日期最早的订单被分类为第一个订单,其余的为“非第一”:
IsFirstOrder =
VAR
E_Date = 'Sales'[OrderDateKey]
VAR
CUST = 'Sales'[CustomerKey]
RETURN
IF(SUMX(FILTER('Sales',CUST = 'Sales'[CustomerKey]&&E_Date > 'Sales'[OrderDateKey]),COUNTROWS('Sales'))>0,FALSE,TRUE)2.过滤销售中所有产品A的订单数据,然后进一步过滤哪些订单被标记为客户的第一个订单。我们在此过滤表中提取客户列表,并向其添加一个名为“ROWS”的虚拟列,得到虚拟表VT1。
3.使用Sales作为主表,并使用NATURALLEFTOUTERJOIN()与虚拟表“VT1”关联,然后使用filter()排除[ROWS]值不等于1的行,其余数据(VT2)是“VT1”返回的所有客户的所有订单。最后,对除“一阶”外的所有订单进一步过滤数据,结果命名为“CustDistinctValue”:
CustDistinctValue =
VAR
FIRSTORDERPROD =
IF(HASONEVALUE('Product'[Subcategory]),VALUES('Product'[Subcategory]),0)
VAR
VT1 =
SUMMARIZE(FILTER(Sales,AND(related('Product'[Subcategory]) = FIRSTORDERPROD,'Sales'[IsFirstOrder]=TRUE)),'Sales'[CustomerKey],"ROWS",DISTINCTCOUNT(Sales[CustomerKey]))
VAR
VT2 =
FILTER(NATURALLEFTOUTERJOIN(ALL(Sales),VT1),[ROWS] = 1)
RETURN
CALCULATE(DISTINCTCOUNT('Sales'[CustomerKey]),FILTER(VT2,'Sales'[IsFirstOrder] = FALSE)
)4.之后,我们需要确保这些数据可以按产品进行过滤(在这种情况下,我们只使用子类别)。这里与宏的计算方法基本相同,使用产品表(Filter product)和主表的副本建立非活动关系,然后创建一个度量值,以便其上下文忽略产品表的所有字段,并从其副本(Filter product)接受上下文。
CustPurchaseOthersSubcategoryAfter =
VAR CustPurchaseOthersSubcategoryAfter =
CALCULATE ('Sales'[CustDistinctValue],CALCULATETABLE (SUMMARIZE ( Sales, Sales[CustomerKey] ),'Sales'[IsFirstOrder] = FALSE,ALLSELECTED ('Product'),USERELATIONSHIP ( Sales[ProductCode],'Filter Product'[Filter ProductCode] ))
)
RETURN
IF(NOT([SameSubCategorySelection]),CustPurchaseOthersSubcategoryAfter)注:“SameSubCategorySelection”用于排除选择相同子类别的数据。此公式还使用宏的方法来完成:
SameSubCategorySelection =
IF (HASONEVALUE ( 'Product'[Subcategory] )&& HASONEVALUE ( 'Filter Product'[Filter Subcategory] ),IF (VALUES ( 'Product'[Subcategory])= VALUES ( 'Filter Product'[Filter Subcategory] ),TRUE)
)5.现在,我们已经计算出购买产品A的客户中有多少人首先购买了其他产品,现在我们需要计算出这些客户占购买产品A的客户总数的比例,然后才有购买记录。以下是计算该比例分母的代码。
AsFirstOrderCust =
VAR
FIRSTORDERPROD =
IF(HASONEVALUE('Product'[Subcategory]),VALUES('Product'[Subcategory]),0)
VAR
VT1 =
SUMMARIZE(FILTER(Sales,AND(RELATED('Product'[Subcategory]) = FIRSTORDERPROD,'Sales'[IsFirstOrder]=TRUE)),'Sales'[CustomerKey]
)
return
CALCULATE(DISTINCTCOUNT('Sales'[CustomerKey]),VT1)
-------------------------------------------------------------------------------
IsLastOrder =
VAR
E_Date = 'Sales'[OrderDateKey]
VAR
CUST = 'Sales'[CustomerKey]
RETURN
IF(SUMX(FILTER('Sales',CUST = 'Sales'[CustomerKey]&&E_Date < 'Sales'[OrderDateKey]),COUNTROWS('Sales'))>0,"F","T")
-------------------------------------------------------------------------------
AsFirstOrderCustRepurchase =
CALCULATE('Sales'[AsFirstOrderCust],'Sales'[IsLastOrder] = "F")现在我们得到了最终的结果:CustPurchaseOthersSubCategoryAfter %,这个度量的名称很长,因为它的逻辑很复杂,就像上面的计算过程一样。
CustPurchaseOthersSubCategoryAfter % =
DIVIDE ( 'Sales'[CustPurchaseOthersSubcategoryAfter],'Sales'[AsFirstOrderCustRepurchase])最终结果
最后,我们将成功获得如下的最终结果,并选择使用名为“CHORD”的自定义视觉效果将其可视化。

如你所见,首先购买公路自行车的顾客中,1853人后来购买了山地自行车,而有趣的是,只有200名顾客在购买了山地自行车之后购买了公路自行车。
附上了PBIX文件,如果你有兴趣的话可以在这里下载。
https://1drv.ms/u/s!AjpQa2fseaxaoDLeh4yBlBSaa-qx
原文链接:https://towardsdatascience.com/explore-the-potential-of-products-through-customers-purchase-behaviour-in-power-bi-basket-a1f77e8a2bf6
欢迎关注磐创AI博客站: http://panchuang.net/
sklearn机器学习中文官方文档: http://sklearn123.com/
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/
这篇关于DAX教程:篮子分析2.0的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








